Transformer推理结构简析(Decoder + MHA)
一、Transformer 基本结构
Transformer由encoder和decoder组成,其中:
-
encoder主要负责理解(understanding) The encoder’s role is to generate a rich representation (embedding) of the input sequence, which the decoder can use if needed
-
decoder主要负责生成(generation) The decoder outputs tokens one by one, where the current output depends on the previous tokens. This process is called auto-regressive generation
基本结构如下:
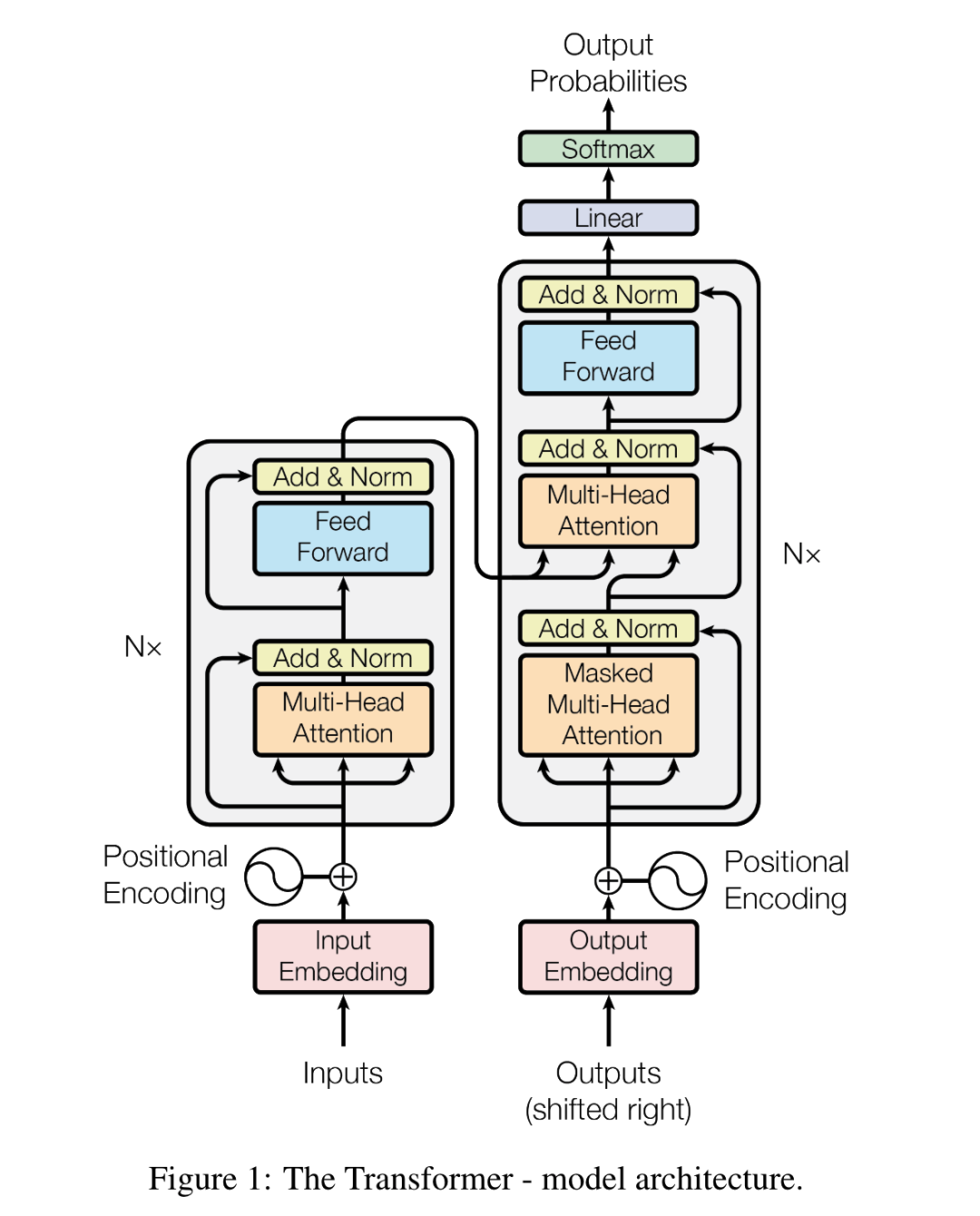
encoder结构和decoder结构基本一致(除了mask),所以主要看decoder即可:
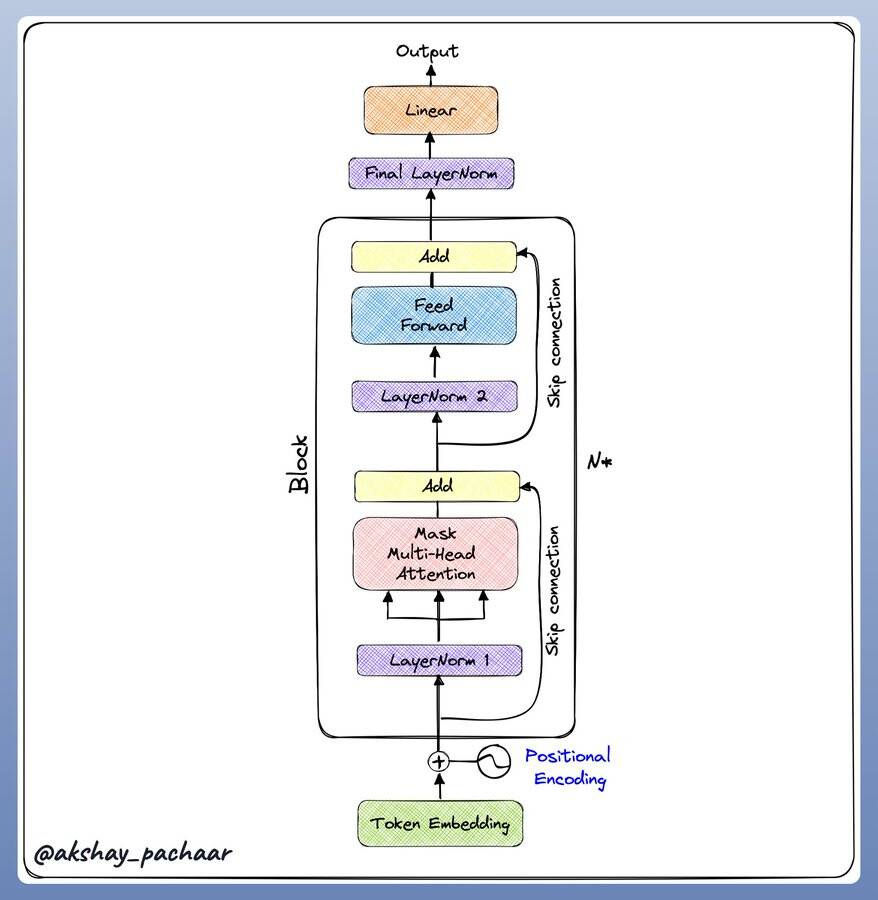
每个核心的Block包含:
- Layer Norm
- Multi headed attention
- A skip connection
- Second layer Norm
- Feed Forward network
- Another skip connection
看下llama decoder部分代码,摘自transformers/models/llama/modeling_llama.py,整个forward过程和上图过程一模一样, 只是layer_norm换成了LlamaRMSNorm:
# 省略了一些不重要的code
class LlamaDecoderLayer(nn.Module):def __init__(self, config: LlamaConfig, layer_idx: int):...def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Tuple[torch.Tensor]] = None,output_attentions: Optional[bool] = False,use_cache: Optional[bool] = False,cache_position: Optional[torch.LongTensor] = None,**kwargs,) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:# hidden_states [bsz, q_len, hidden_size]residual = hidden_stateshidden_states = self.input_layernorm(hidden_states)# Self Attention 即MHAhidden_states, self_attn_weights, present_key_value = self.self_attn(hidden_states=hidden_states,attention_mask=attention_mask,position_ids=position_ids,past_key_value=past_key_value,output_attentions=output_attentions,use_cache=use_cache,cache_position=cache_position,**kwargs,)hidden_states = residual + hidden_states# Fully Connecteresidual = hidden_stateshidden_states = self.post_attention_layernorm(hidden_states)hidden_states = self.mlp(hidden_states)hidden_states = residual + hidden_statesoutputs = (hidden_states,)return outputs上述代码展示的是标准的decoder过程,几个关键输入:
-
hidden_states [batch_size, seq_len, embed_dim] seq_len表示输入长度
-
attention mask的size为
(batch_size, 1, query_sequence_length, key_sequence_length)注意力掩码,实际使用的时候,PyTorch 会自动广播这个掩码到注意力权重矩阵的形状 [bsz, num_heads, q_len, kv_seq_len]。 -
position_ids or position_embeddings,位置id或者已经提前计算好的位置embedding
上述最核心的结构是其调用的self.self_attn,即是Multi-headed attention。
二、Multihead Attention
Multihead Attention,多头注意力,上述decoder过程中最核心的地方,同时也是算子优化发力的地方。要理解多头先从单头开始。
单个attention
即Scaled Dot-Product Attention,公式如下:
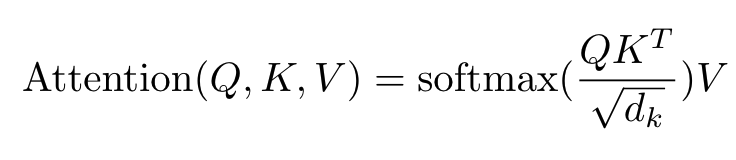
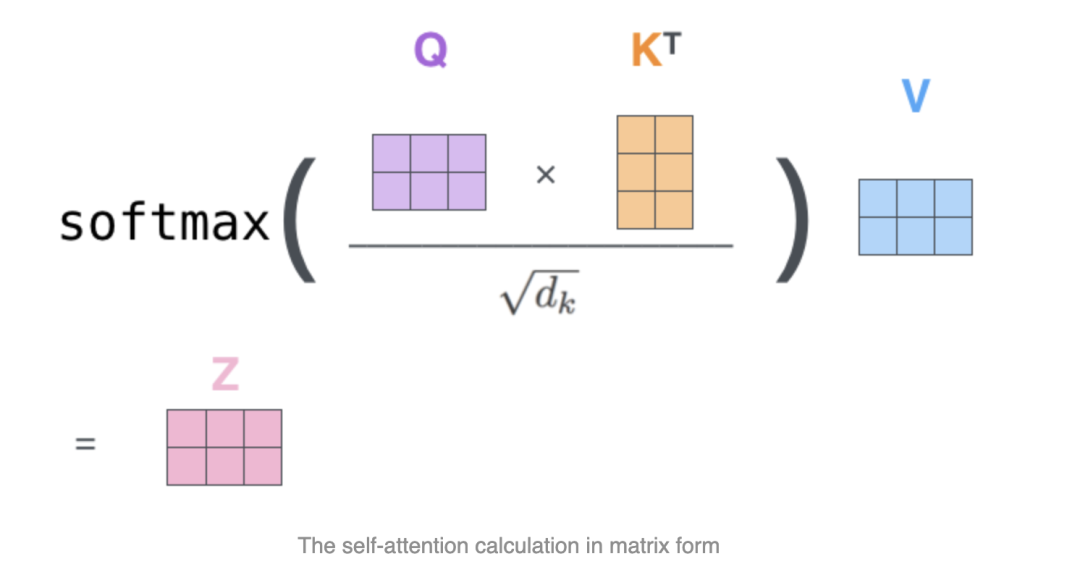
其中QKV的维度一致,比如这里都是(2,3):
那么QKV怎么得到的呢?通过输入embedding和WqWkWv相乘得到qkv,这里WqWkWv是可学习参数:
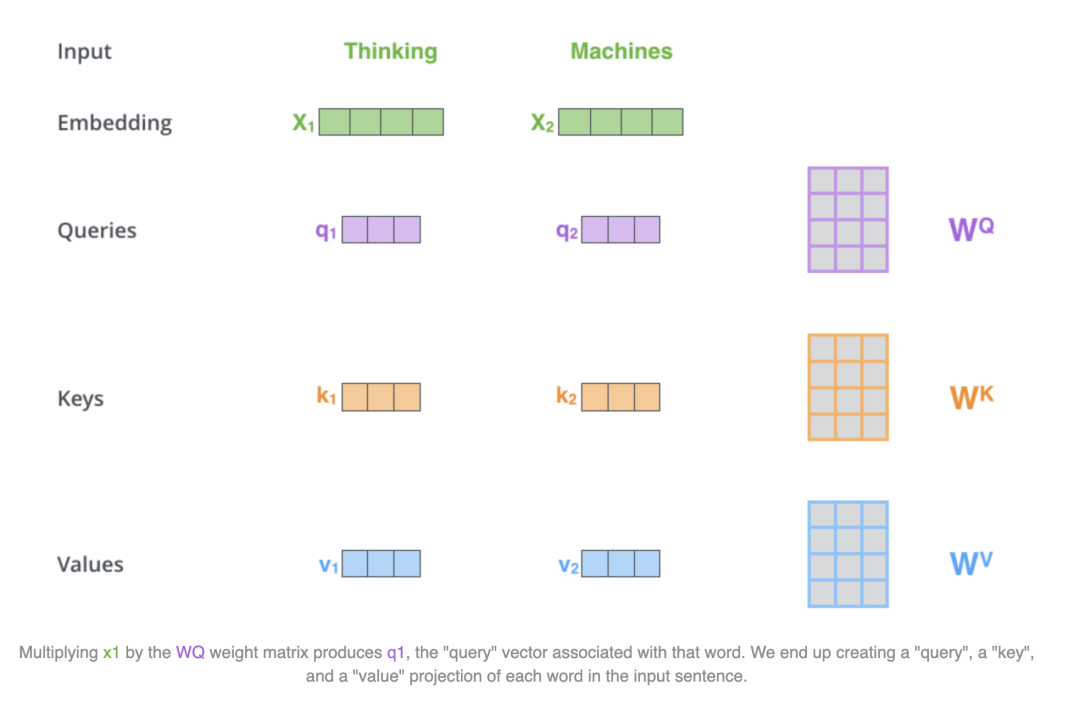
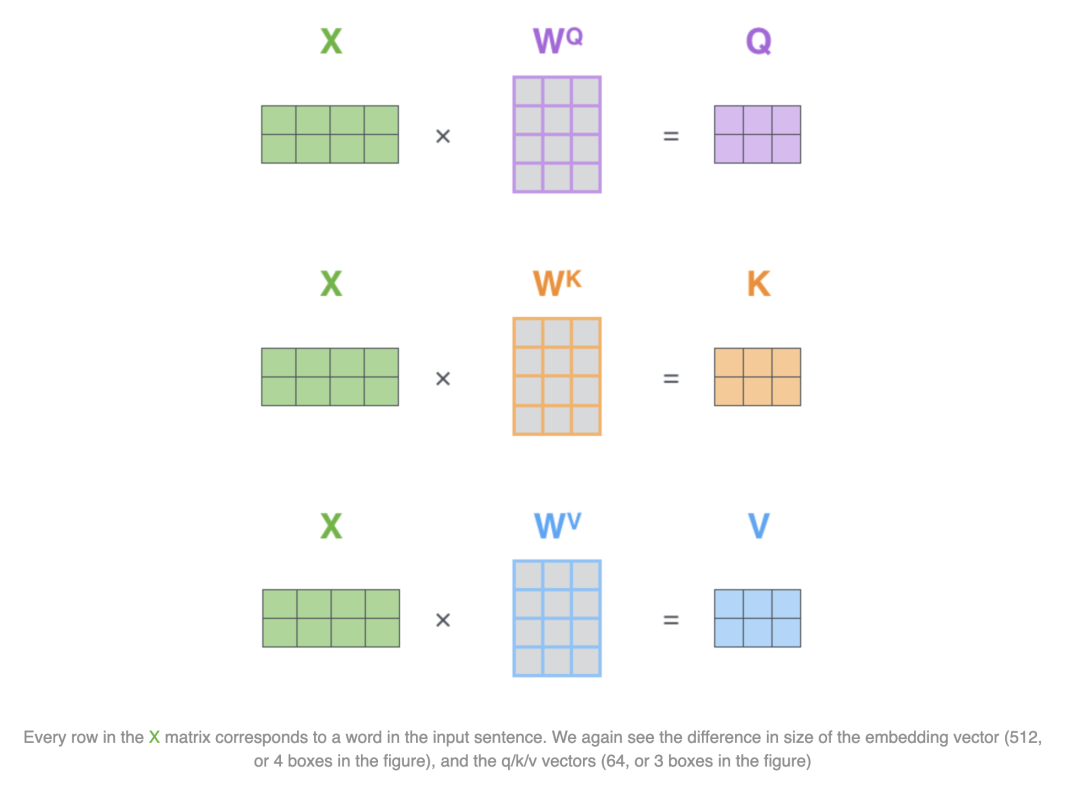
拆开合起来计算都是等价的,上述的X1和X2是拆开计算,但是组合起来为(2,4)维度,同样可以和WqWkWv进行矩阵乘
实际在decoder的计算中,会带入causal (or look-ahead) mask:
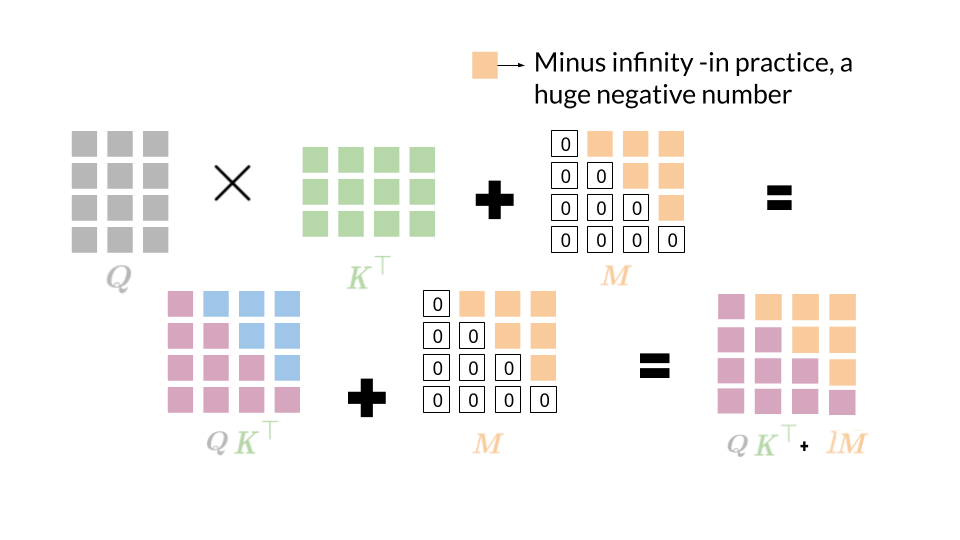
Causal mask 是为了确保模型在解码时不会关注未来的 token,这对于生成任务是必不可少的。通过这个掩码,模型只会依赖已经生成的 token,确保解码过程中是自回归的。
多个attention
实际中一般都是多个attention,和单个attention区别不大,下图右侧是多个attention的结构:
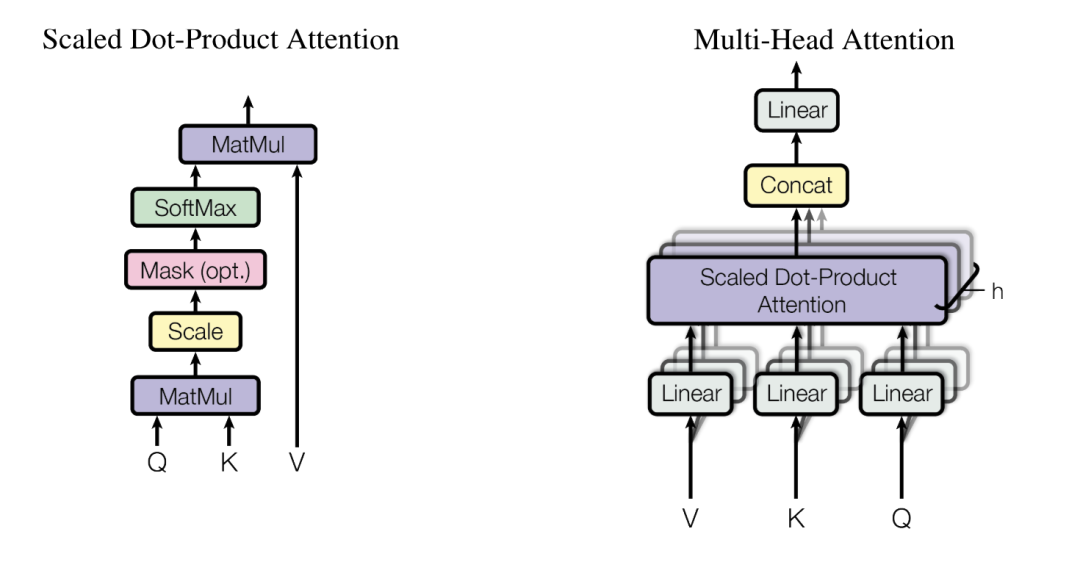
自注意力在多个头部之间并行应用,最后将结果连接在一起,我们输入(2,4)维度的X,分别和不同头的WqWkWv进行矩阵乘法得到每个头对应的QKV,然后QKV算出Z,再将所有Z合并和Wo相乘得到维度和X一致的Z:
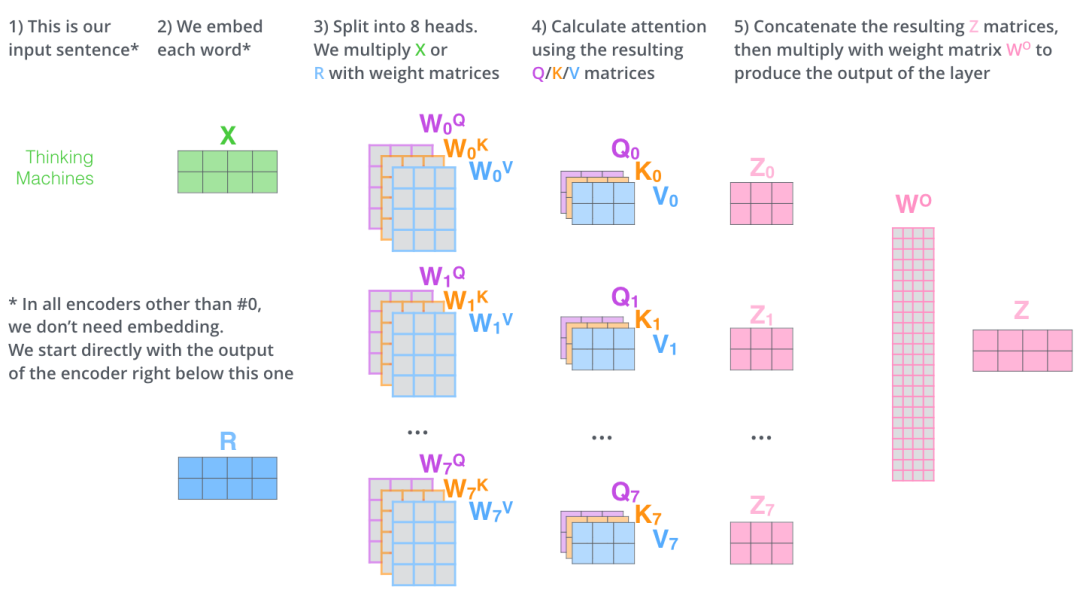
实际中需要学习的权重为每个头的WqWkWv,同时也需要一个Wo,看一下llama中的实际计算过程:
class LlamaAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def __init__(self, config: LlamaConfig, layer_idx: Optional[int] = None):super().__init__()self.config = configself.layer_idx = layer_idxself.attention_dropout = config.attention_dropoutself.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_headsself.head_dim = self.hidden_size // self.num_headsself.num_key_value_heads = config.num_key_value_headsself.num_key_value_groups = self.num_heads // self.num_key_value_headsself.max_position_embeddings = config.max_position_embeddingsself.rope_theta = config.rope_thetaself.is_causal = True# 这行代码是一个检查条件,确保hidden_size能够被num_heads整除。# 在多头注意力(Multi-Head Attention, MHA)机制中,输入的hidden_size被分割成多个头,每个头处理输入的一个子集。# head_dim是每个头处理的维度大小,它由hidden_size除以num_heads得到。if (self.head_dim * self.num_heads) != self.hidden_size:raise ValueError(f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"f" and `num_heads`: {self.num_heads}).")# 需要学习更新的四个权重 WqWkWvWoself.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)self._init_rope()def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,**kwargs,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size()query_states = self.q_proj(hidden_states)key_states = self.k_proj(hidden_states)value_states = self.v_proj(hidden_states)query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None:if self.layer_idx is None:raise ValueError(f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} ""for auto-regressive decoding with k/v caching, please make sure to initialize the attention class ""with a layer index.")kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)key_states = repeat_kv(key_states, self.num_key_value_groups)value_states = repeat_kv(value_states, self.num_key_value_groups)attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None:if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):raise ValueError(f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")attn_weights = attn_weights + attention_mask# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)# (bsz, self.num_heads, q_len, self.head_dim)attn_output = torch.matmul(attn_weights, value_states)# (bsz, q_len, self.num_heads, self.head_dim)attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)attn_output = self.o_proj(attn_output)return attn_output, attn_weights, past_key_value上述的计算过程可以总结为以下几个步骤,假设输入张量hidden_states的维度为[batch_size, seq_length, hidden_size]。


这个过程实现了将输入通过多个注意力"头"并行处理的能力,每个"头"关注输入的不同部分,最终的输出是所有"头"输出的拼接,再经过一个线性变换。这种机制增强了模型的表达能力,使其能够从多个子空间同时捕获信息。
因为不用GQA,q_len 就是 seq_length 就是 kv_seq_len
三、MHA计算
实际的多头计算代码如下,这里是通过torch.matmul实现的:
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None: # no matter the length, we just slice itcausal_mask = attention_mask[:, :, :, : key_states.shape[-2]]attn_weights = attn_weights + causal_maskposition_ids: Optional[torch.LongTensor] = None,# upcast attention to fp32attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)attn_output = torch.matmul(attn_weights, value_states)上述代码中query_states和key_states的形状分别为[bsz, num_heads, q_len, head_dim]和[bsz, num_heads, kv_seq_len, head_dim]。matmul操作会自动在最后两个维度上进行矩阵乘法,并在前两个维度上进行广播。
应用注意力掩码attn_weights = attn_weights + causal_mask,causal_mask的形状可能是[1, 1, q_len, kv_seq_len]。PyTorch会自动将其广播到attn_weights的形状[bsz, num_heads, q_len, kv_seq_len]。
应用softmax和dropout,然后最后计算attn_output = torch.matmul(attn_weights, value_states),其中attn_weights的形状为[bsz, num_heads, q_len, kv_seq_len],value_states的形状为[bsz, num_heads, kv_seq_len, head_dim]。matmul操作会在最后两个维度上进行矩阵乘法,并在前两个维度上进行广播。这里attn_output的维度为bsz, num_heads, q_len, self.head_dim。
四、torch.matmul
多维矩阵乘法,支持多维和broadcast,比较复杂:
- 如果两个输入张量都是一维张量,执行的是点积操作,返回一个标量
- 如果两个输入张量都是二维张量,执行的是矩阵乘法,返回一个新的二维矩阵,这个操作就是常见的
- 如果第一个张量是一维张量,第二个张量是二维张量,则会在第一张量的维度前面添加一个1(扩展为2维),然后进行矩阵乘法,计算完后会移除添加的维度
- 如果第一个张量是二维张量,第二个张量是一维张量,则执行的是矩阵-向量乘法,返回一个一维张量
- 当两个输入张量中有一个是多维的(N > 2),会执行批量矩阵乘法。在这种情况下,非矩阵的维度(批量维度)会被广播(broadcasted)。如果一个张量是一维,会对其进行维度扩展和移除
我们这里的多维数据 matmul() 乘法,可以认为该乘法使用使用两个参数的后两个维度来计算,其他的维度都可以认为是batch维度。
比如,输入张量的形状为 (j×1×n×n) 和 (k×n×n) 时,会输出形状为 (j×k×n×n) 的张量。
具体点,假设两个输入的维度分别是input (1000×500×99×11), other (500×11×99)那么我们可以认为torch.matmul(input, other, out=None) 乘法首先是进行后两位矩阵乘法得到(99×11)×(11×99)⇒(99×99) ,然后分析两个参数的batch size分别是 (1000×500)和 500, 可以广播成为 (1000×500), 因此最终输出的维度是(1000×500×99×99)。
计算QK点积的时候:
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)query_states的形状为[bsz, num_heads, q_len, head_dim],key_states.transpose(2, 3)的形状为[bsz, num_heads, head_dim, kv_seq_len]。matmul操作会在最后两个维度上进行矩阵乘法,得到形状为[bsz, num_heads, q_len, kv_seq_len]的注意力权重。
计算注意力输出:
attn_output = torch.matmul(attn_weights, value_states) 这里使用torch.matmul将注意力权重与值(value)相乘。attn_weights的形状为[bsz, num_heads, q_len, kv_seq_len],value_states的形状为[bsz, num_heads, kv_seq_len, head_dim]。matmul操作会在最后两个维度上进行矩阵乘法,得到形状为[bsz, num_heads, q_len, head_dim]的注意力输出。
因为我们不用GQA,q_len 就是 kv_seq_len
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。