揭秘 Elasticsearch 集群架构,解锁大数据处理神器
Elasticsearch 是一个强大且广泛使用的分布式搜索和分析引擎,它在大数据处理、实时搜索和分析领域发挥着重要作用。
Elasticsearch 集群同时具备高可用性和负载均衡的特性。这两个特性是确保集群在大规模数据处理和高并发环境中稳定运行的关键。本文将深入探讨 Elasticsearch 集群的架构和特性。
一、什么是 Elasticsearch 集群?
Elasticsearch 集群是由一个或多个节点(node)组成的分布式系统,这些节点共同工作以存储和检索数据。
1、典型集群架构
一个典型的 Elasticsearch 集群包括多个 Node 节点,其中一个节点为主节点(master node)。多个节点以确保集群的高可用性、数据存储、查询处理和负载均衡。
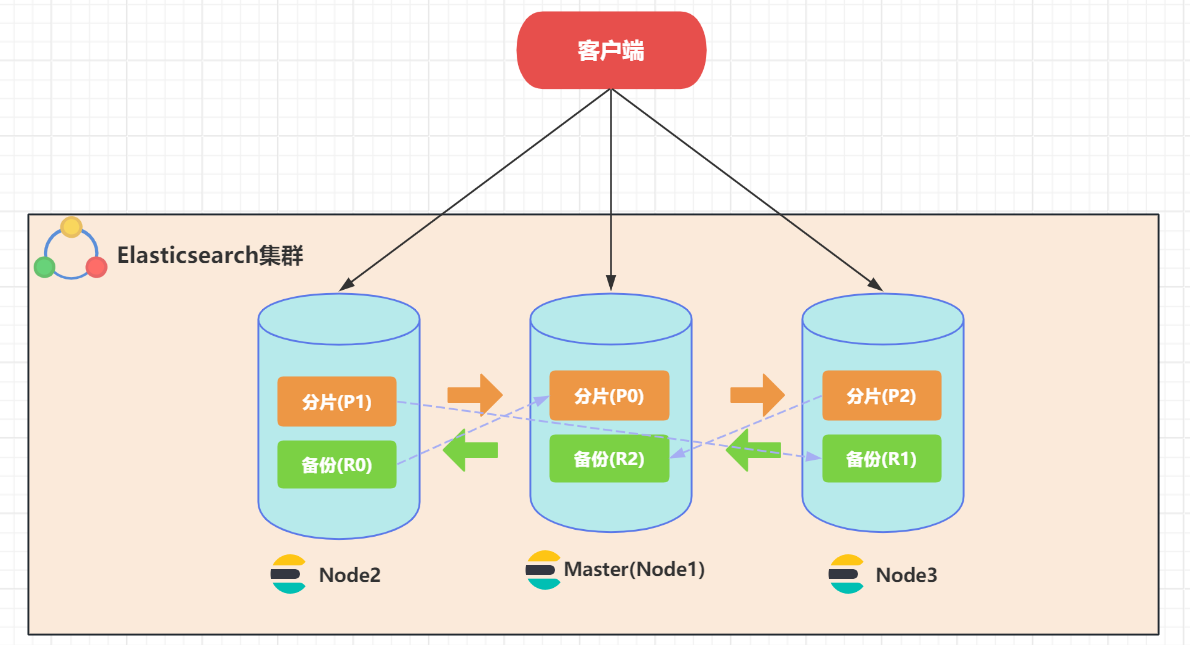
主节点:
- 主节点(Node 1)负责管理集群元数据,如索引的创建、删除和分片的分配。
- 主节点还监控集群的健康状态,并在节点出现故障时重新分配分片。
数据节点:
- 数据节点(Node 1、Node 2、Node 3)存储分片数据,并处理搜索和聚合请求。
- 数据节点可以是主节点,也可以不是,具体取决于集群的配置和规模。
读写请求处理:
- 写请求首先被发送到主分片,然后再同步到副本分片。
- 读请求可以由主分片或副本分片处理,从而分担负载并提高查询性能。
数据存储:
- 当数据被索引时,它被存储在主分片(P0、P1、P2)中。
- 每个主分片都有相应的副本分片(R0、R1、R2),这些副本分片存储在不同的节点上交叉存储,以确保数据的高可用性。
2、大型集群架构
对于大型Elasticsearch 集群会包括多种类型的节点,每种节点在集群中扮演不同的角色,如主节点(master node)、数据节点(data node)、协调节点(coordinating node)和ingest节点(ingest node)。
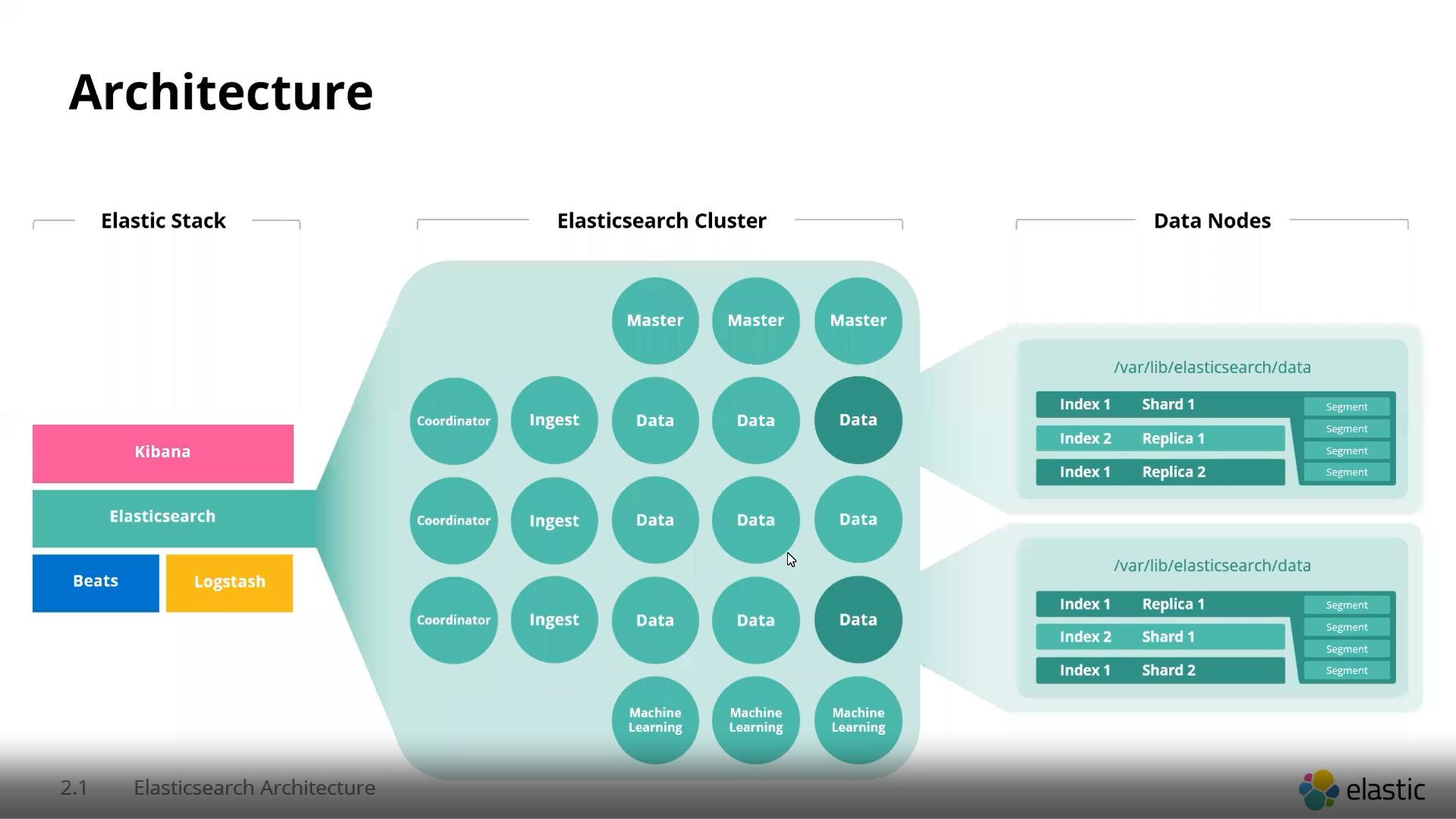
Master Node:
- 负责集群范围内的管理任务,如创建或删除索引、跟踪节点的加入或离开、以及分片分配。
- 建议设置为奇数个节点(3个或5个),以确保在网络分区时能够达成共识。
Data Node:
- 负责存储数据和执行数据相关的操作,如CRUD操作、搜索和聚合。
- 根据数据量和查询需求,合理配置CPU、内存和磁盘。
Ingest Node:
- 负责预处理文档数据(例如,通过管道进行数据转换和丰富)。
- 可根据数据摄入需求进行水平扩展。
Coordinating Node:
- 作为负载均衡器,将请求分发到合适的数据节点,并聚合结果返回给客户端。
- 默认情况下,所有节点都可以充当协调节点,但在大规模集群中,可以专门配置此角色以提高性能。
二、集群高可用性(High Availability)
高可用性是分布式系统的关键特性,确保在部分节点故障时,系统依然能够正常运行。Elasticsearch 通过以下机制实现高可用性:
1. 节点冗余
Elasticsearch 集群通过引入多个节点,确保在一个或多个节点故障时,其他节点可以继续提供服务。这种节点冗余设计避免了单点故障(SPOF),提高了集群的可靠性。
2. 数据冗余
数据冗余是高可用性的核心。Elasticsearch 通过分片(shard)和副本(replica)机制实现数据冗余。每个索引可以分为多个主分片,每个主分片可以有一个或多个副本分片。副本分片存储在不同的节点上,当主分片所在节点故障时,副本分片可以立即接替主分片的工作,确保数据可用性。
3. 主节点选举
主节点在集群中负责管理元数据和分片分配。当主节点故障时,Elasticsearch 集群会自动进行主节点选举,从剩余的主节点候选人中选出新的主节点。这种机制确保了集群管理功能的连续性。
4. 分片自动重分配
当节点加入或离开集群时,Elasticsearch 会自动重新分配分片,以确保数据的冗余性和负载均衡。分片重分配过程是透明的,不会中断集群的正常运行。
三、集群负载均衡(Load Balancing)
负载均衡是确保系统高效运行的关键。Elasticsearch 通过多种机制实现请求的均匀分布,防止单点过载。
1. 协调节点
协调节点接收用户的请求,将其分发到合适的数据节点进行处理,并将结果聚合后返回给客户端。虽然默认情况下所有节点都可以充当协调节点,但在大型集群中,可以配置专门的协调节点以优化性能和资源利用。
2. 数据节点分布
数据节点存储和处理数据。Elasticsearch 通过分片机制将数据分布到不同的数据节点上,每个节点处理一部分数据请求。合理的分片策略可以确保查询和索引请求在各节点之间均匀分布,防止某些节点过载。
3. 请求分发
查询请求和索引请求可以由任意节点接收,并根据分片信息路由到相应的数据节点。Elasticsearch 的分片机制使得请求可以并行处理,提高了查询和索引的响应速度。
4. 并行处理
Elasticsearch 通过并行处理机制,将查询和索引请求分布到多个节点上执行。特别是在处理复杂查询和大数据量时,并行处理显著提高了系统的处理效率和响应速度。
我是栈江湖,如果你喜欢此文章,不要忘记关注+点赞哦!你的支持是我创作的动力。如果你有任何意见或建议,欢迎在下方留言。若转载,请注明文章来源。