1.Spark简介
什么是Spark?
Spark是UC BerkeleyAmp实验室开源的类Hadoop MapReduce的通用并行计算框架
Spark VS MapReduce
MapReduce
①.缺少对迭代计算以及DAG运算的支持
②.Shuffle过程多次排序和落地,MR之间的数据需要落Hdfs文件系统
Spark
①.提供了一套支持DAG图的分布式并行计算的编程框架,减少多次计算之间中间结果写到hdfs的开销
②.提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
③.使用多线程池模型来减少task启动开稍,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
④.广泛的数据集操作类型(map,groupby,count,filter)
⑤.Spark通过提供丰富的Scala, Java,PythonAPI及交互式Shell来提高可用性
⑥.RDD之间维护了血统关系,一旦RDDfail掉了,能通过父RDD自动重建,保证了容错性。 采用容错的、高可伸缩性的akka作为通讯框架
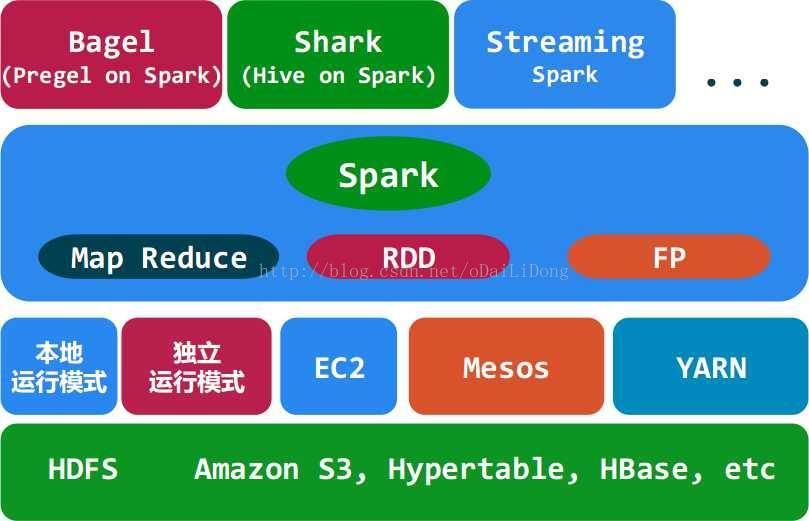
2.Spark生态系统
3.Scala集合简介
vallist2 = List(1,2,3,4,5)
list2.map{x=>x +8} //{9,10,11,12,13}
list2.filter{x=>x > 3} //{4,5}
list2.reduce(_ + _)
更多scala学习网址:http://twitter.github.io/scala_school/zh_cn/collections.html
4.spark的关键组件
•Master
•Worker
•SparkContext(客户端)
5.核心概念:弹性分布式数据集
Spark围绕的概念是弹性分布式数据集(RDD),这是一个有容错机制并可以被并行操作的元素集合。
RDD的特点:
失败自动重建。对于丢失部分数据分区只需根据它的lineage(见文章最后介绍)就可重新计算出来,而不需要做特定的Checkpoint
可以控制存储级别(内存、磁盘等)来进行重用。默认是存储于内存,但当内存不足时,RDD会spill到disk
必须是可序列化的。
目前RDD有两种创建方式:并行集合(ParallelizedCollections):接收一个已经存在的Scala集合,然后进行各种并行计算。 Hadoop数据集(HadoopDatasets):在一个文件的每条记录上运行函数。只要文件系统是HDFS,或者hadoop支持的任意存储系统即可。这两种类型的RDD都可以通过相同的方式进行操作。
1.并行集合(Parallelized Collections)
•并行集合是通过调用SparkContext的parallelize方法,在一个已经存在的Scala集合上创建的(一个Seq对象)。集合的对象将会被拷贝,创建出一个可以被并行操作的分布式数据集。例如,下面的输出,演示了如何从一个数组创建一个并行集合:
•scala> val data = Array(1, 2, 3, 4, 5)
•scala> val distData =sc.parallelize(data)
•一旦分布式数据集(distData)被创建好,它们将可以被并行操作。例如,我们可以调用distData.reduce(_+_ )来将数组的元素相加
2.Hadoop数据集(Hadoop Datasets)
•Spark可以从存储在HDFS,或者Hadoop支持的其它文件系统(包括本地文件,HBase等等)上的文件创建分布式数据集。
•Text file的RDDs可以通过SparkContext’stextFile的方式创建,
•scala> val distFile =sc.textFile("data.txt")
并行集合的一个重要参数是slices,表示数据集切分的份数。Spark将会在集群上为每一份数据起一个任务。典型地,你可以在集群的每个CPU上分布2-4个slices.一般来说,Spark会尝试根据集群的状况,来自动设定slices的数目。然而,你也可以通过传递给parallelize的第二个参数来进行手动设置。(例如:sc.parallelize(data,10)).
textFile方法也可以通过输入一个可选的第二参数,来控制文件的分片数目。默认情况下,Spark为每一块文件创建一个分片(HDFS默认的块大小为64MB),但是你也可以通过传入一个更大的值,来指定一个更高的片值。注意,你不能指定一个比块数更小的片值(和Map数不能小于Block数一样,但是可以比它多)
6.RDD的操作
RDD支持两种操作:转换(transformation)从现有的数据集创建一个新的数据集;而动作(actions)在数据集上运行计算后,返回一个值给驱动程序。例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布数据集表示结果。另一方面,reduce是一种动作,通过一些函数将所有的元素叠加起来,并将最终结果返回给Driver程序。
转换(transformation)
转换 | 含义 |
map(func) | 返回一个新分布式数据集,由每一个输入元素经过func函数转换后组成 |
filter(func) | 返回一个新数据集,由经过func函数计算后返回值为true的输入元素组成 |
flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(因此func应该返回一个序列,而不是单一元素) |
distinct([numTasks])) | 返回一个包含源数据集中所有不重复元素的新数据集 |
groupByKey([numTasks]) | 在一个(K,V)对的数据集上调用,返回一个(K,Seq[V])对的数据集注意:默认情况下,只有8个并行任务来做操作,但是你可以传入一个可选的numTasks参数来改变它 |
reduceByKey(func[numTasks]) | 在一个(K,V)对的数据集上调用时,返回一个(K,V)对的数据集,使用指定的reduce函数,将相同key的值聚合到一起。类似groupByKey,reduce任务个数是可以通过第二个可选参数来配置的 |
sortByKey([ascending[numTasks]) | 在一个(K,V)对的数据集上调用,K必须实现Ordered接口,返回一个按照Key进行排序的(K,V)对数据集。升序或降序由ascending布尔参数决定 |
join(otherDataset[numTasks]) | 在类型为(K,V)和(K,W)类型的数据集上调用时,返回一个相同key对应的所有元素对在一起的(K, (V, W))数据集 |
动作(actions)
动作 | 含义 |
reduce(func) | 通过函数func(接受两个参数,返回一个参数)聚集数据集中的所有元素。这个功能必须可交换且可关联的,从而可以正确的被并行执行。 |
collect() | 在驱动程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作并返回一个足够小的数据子集后再使用会比较有用。 |
count() | 返回数据集的元素的个数。 |
first() | 返回数据集的第一个元素(类似于take(1)) |
take(n) | 返回一个由数据集的前n个元素组成的数组。注意,这个操作目前并非并行执行,而是由驱动程序计算所有的元素 |
saveAsTextFile(path) | 将数据集的元素,以textfile的形式,保存到本地文件系统,HDFS或者任何其它hadoop支持的文件系统。对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本行 |
countByKey() | 对(K,V)类型的RDD有效,返回一个(K,Int)对的Map,表示每一个key对应的元素个数 |
foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。这通常用于边缘效果,例如更新一个累加器,或者和外部存储系统进行交互,例如HBase |
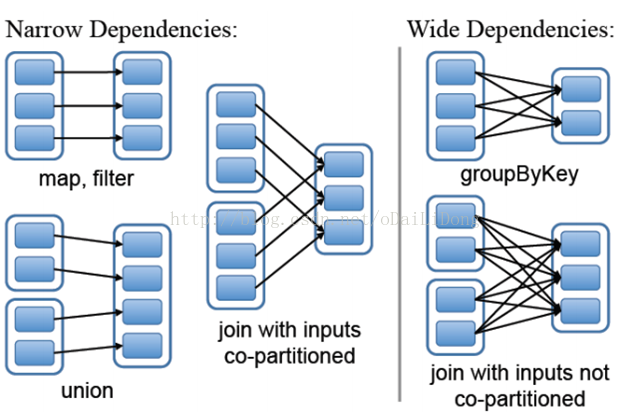
7. RDD依赖
•转换操作,最主要的操作,是Spark生成DAG图的对象,转换操作并不立即执行,在触发行动操作后再提交给driver处理,生成DAG图--> Stage --> Task --> Worker执行。按转化操作在DAG图中作用,可以分成两种:
•窄依赖
»输入输出一对一的操作,且结果RDD的分区结构不变,主要是map、flatMap;
»输入输出一对一,但结果RDD的分区结构发生了变化,如union等;
»从输入中选择部分元素的操作,如filter、distinct、subtract、sample。
•宽依赖,宽依赖会涉及shuffle类,在DAG图解析时以此为边界产生Stage,如图所示。
»对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
»对两个RDD基于key进行join和重组,如join等。
Stage的划分
在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。比如rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;如果是rdd.map(x=> (x, 1)).reduceByKey(_ + _).foreach(println),这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
8.Wordcount例子
输入文件例子:由空格分隔的
aaabbbccc
ccc bbbddd
计算过程:读入文件,把每行数据,按空格分成单个的单词。对每个单词记数
val ssc = newSparkContext().setAppName("WordCount")
val lines =ssc.textFile(args(1))//输入
val words =
lines.flatMap(x=>x.split(" "))
words.cache()//缓存
valwordCounts =
words.map(x=>(x, 1) )
val red =wordCounts.reduceByKey( (a,b)=>{a + b})
red.saveAsTextFile(“/root/Desktop/out”) //行动
蓝色的部分,生成相关的上下文,负责和Master,exutor通信,请求资源,搜集task执行的进度等
绿色的部分,仅仅是在定义相关的运算规则(也就是画一张有向无环图),没有执行实际的计算
当红色的部分(action rdd)被调用的时候,才会真正的向spark集群去提交,Dag。。。根据之前代码(也就是绿色的部分)生成rdd链,在根据分区算法生成partition,每个partition对应一个Task,把这些task,交给Excutor去执行
9. 提交job
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hangzhou-jishuan-DDS0258.dratio.puppet:7077 \
--executor-memory 2G \
--total-executor-cores 3 \
/opt/spark-1.0.2-bin-hadoop1/lib/spark-examples-1.0.2-hadoop1.0.4.jar \
10
更详细的参数说明参见:http://blog.csdn.net/book_mmicky/article/details/25714545
10. 编程接口
Scala
Spark使用Scala开发,默认使用Scala作为编程语言。编写Spark程序比编写HadoopMapReduce程序要简单的多,SparK提供了Spark-Shell,可以在Spark-Shell测试程序。写SparK程序的一般步骤就是创建或使用(SparkContext)实例,使用SparkContext创建RDD,然后就是对RDD进行操作。参见:http://spark.apache.org/docs/latest/quick-start.html#tab_scala_3
如:
• val sc = new SparkContext(master, appName,[sparkHome], [jars])
• val textFile =sc.textFile("hdfs://.....")
• textFile.map(....).filter(.....).....
•
Java
• JavaSparkContext sc = newJavaSparkContext(...);
• JavaRDD lines =ctx.textFile("hdfs://...");
• JavaRDD words = lines.flatMap(
• new FlatMapFunction<String,String>() {
• public Iterable call(String s) {
• return Arrays.asList(s.split("")); } } );
•
Python
• from pyspark import SparkContext
• sc = SparkContext("local","Job Name", pyFiles=['MyFile.py', 'lib.zip', 'app.egg'])
• words =sc.textFile("/usr/share/dict/words")
• words.filter(lambda w:w.startswith("spar")).take(5)
11. Spark运行架构
Sparkon YARN 运行过程(cluster模式)
1.用户通过bin/spark-submit或bin/spark-class 向YARN提交Application
2.RM为Application分配第一个container,并在指定节点的container上启动SparkContext。
3.SparkContext向RM申请资源以运行Executor
4.RM分配Container给SparkContext,SparkContext和相关的NM通讯,在获得的Container上启动 StandaloneExecutorBackend,StandaloneExecutorBackend启动后,开始向SparkContext注册并申请 Task
5.SparkContext分配Task给StandaloneExecutorBackend执行
6.StandaloneExecutorBackend执行Task并向SparkContext汇报运行状况
7.Task运行完毕,SparkContext归还资源给NM,并注销退出。
12.Spark SQL
Spark SQL是一个即席查询系统,其前身是shark,不过代码几乎都重写了,但利用了shark的最好部分内容。SparkSQL可以通过SQL表达式、HiveQL或者Scala DSL在Spark上执行查询。目前Spark SQL还是一个alpha版本。
13.SparkStreaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP套接字)进行类似map、reduce、join、window等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
SparkStreaming流式处理系统特点有:
• 将流式计算分解成一系列短小的(按秒)批处理作业
• 将失败或者执行较慢的任务在其它节点上并行执行
• 较强的容错能力(checkpoint等)
• 使用和RDD一样的语义

./bin/run-exampleorg.apache.spark.examples.streaming.NetworkWordCount localhost 9999
nc-lk 9999
14. 练习题
有一批ip,找出出现次数最多的前50个?
10.129.41.91
61.172.251.20
10.150.9.240
...
答案:
data.map(word=>(word,1)).reduceByKey(_+_).map(word=>(word._2,word._1)).sortByKey(false).map(word=>(word._2,word._1)).take(50)
15.延伸
Lineage(血统)
Spark处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用血统关系(Lineage)方案。RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
RDD在Lineage依赖方面分为两种NarrowDependencies与WideDependencies用来解决数据容错的高效性。NarrowDependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。WideDependencies是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。对与WideDependencies,这种计算的输入和输出在不同的节点上,lineage方法对与输入节点完好,而输出节点宕机时,通过重新计算,这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上其祖先追溯看是否可以重试(这就是lineage,血统的意思),NarrowDependencies对于数据的重算开销要远小于WideDependencies的数据重算开销。
容错
在RDD计算,通过checkpint进行容错,做checkpoint有两种方式,一个是checkpointdata,一个是loggingthe updates。用户可以控制采用哪种方式来实现容错,默认是loggingthe updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。