(强烈推荐)移动端音视频从零到上手(上)
本文已获得作者授权,原文作者:小东邪
概述
随着整个互联网的崛起,数据传递的形式也在不断升级变化,总的流行趋势如下:
纯文本的短信,QQ -> 空间,微博,朋友圈的图片文字结合 -> 微信语音 -> 各大直播软件 -> 抖音短视频
音视频的发展正在向各个行业不断扩展,从教育的远程授课,交通的人脸识别,医疗的远程就医等等,音视频方向已经占据一个相当重要的位置,而音视频真正入门的文章又少之甚少,一个刚毕业小白可能很难切入理解,因为音视频中涉及大量理论知识,而代码的书写需要结合这些理论,所以搞懂音视频,编解码等理论知识至关重要.本人也是从实习开始接触音视频项目,看过很多人的文章,在这里总结一个通俗易懂的文章,让更多准备学习音视频的同学更快入门。
划重点
本文中理论知识来自于各种音视频文章的归纳音视频编码基本原理汇总,其中也会有一些我自己总结增加的部分.若有错误可评论,检查后会更正.
原理
采集
无论是iOS平台,还是安卓平台,我们都是需要借助官方的API实现一系列相关功能.首先我们要明白我们想要什么,最开始我们需要一部手机,智能手机中摄像头是不可缺少的一部分,所以我们通过一些系统API获取就要可以获取物理摄像头将采集到的视频数据与麦克风采集到的音频数据.
处理
音频和视频原始数据本质都是一大段数据,系统将其包装进自定义的结构体中,通常都以回调函数形式提供给我们,拿到音视频数据后,可以根据各自项目需求做一系列特殊处理,如: 视频的旋转,缩放,滤镜,美颜,裁剪等等功能, 音频的单声道降噪,消除回声,静音等等功能.
编码
原始数据做完自定义处理后就可以进行传输,像直播这样的功能就是把采集好的视频数据发送给服务器,以在网页端供所有粉丝观看,而传输由于本身就是基于网络环境,庞大的原始数据就必须压缩后才能带走,可以理解为我们搬家要将物品都打包到行李箱这样理解.
传输
编码后的音视频数据通常以RTMP协议进行传输,这是一种专门用于传输音视频的协议,因为各种各样的视频数据格式无法统一,所以需要有一个标准作为传输的规则.协议就起到这样的作用.
解码
服务端接收到我们送过去的编码数据后,需要对其解码成原始数据,因为编码的数据直接送给物理硬件的设备是不能直接播放的,只有解码为原始数据才能使用.
音视频同步
解码后的每帧音视频中都含有最开始录制时候设置的时间戳,我们需要根据时间戳将它们正确的播放出来,但是在网络传输中可能会丢失一些数据,或者是延时获取,这时我们就需要一定的策略去实现音视频的同步,大体分为几种策略:缓存一定视频数据,视频追音频等等.
推流与拉流流程
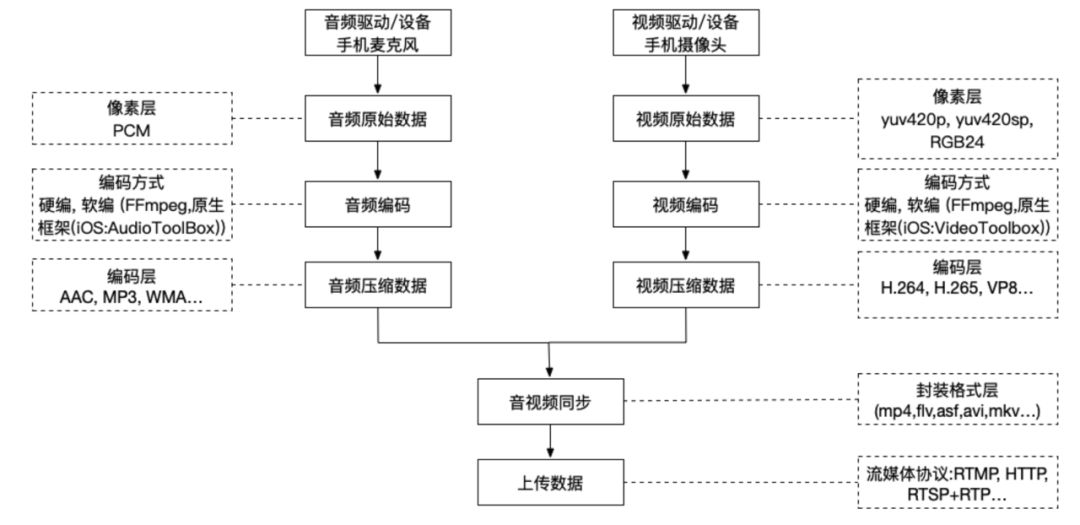
推流
将手机采集到的视频数据传给后台播放端进行展示,播放端可以是windows, linux, web端,即手机充当采集的功能,将手机摄像头采集到视频和麦克风采集到的音频合成编码后传给对应平台的播放端。
推流如下:
拉流
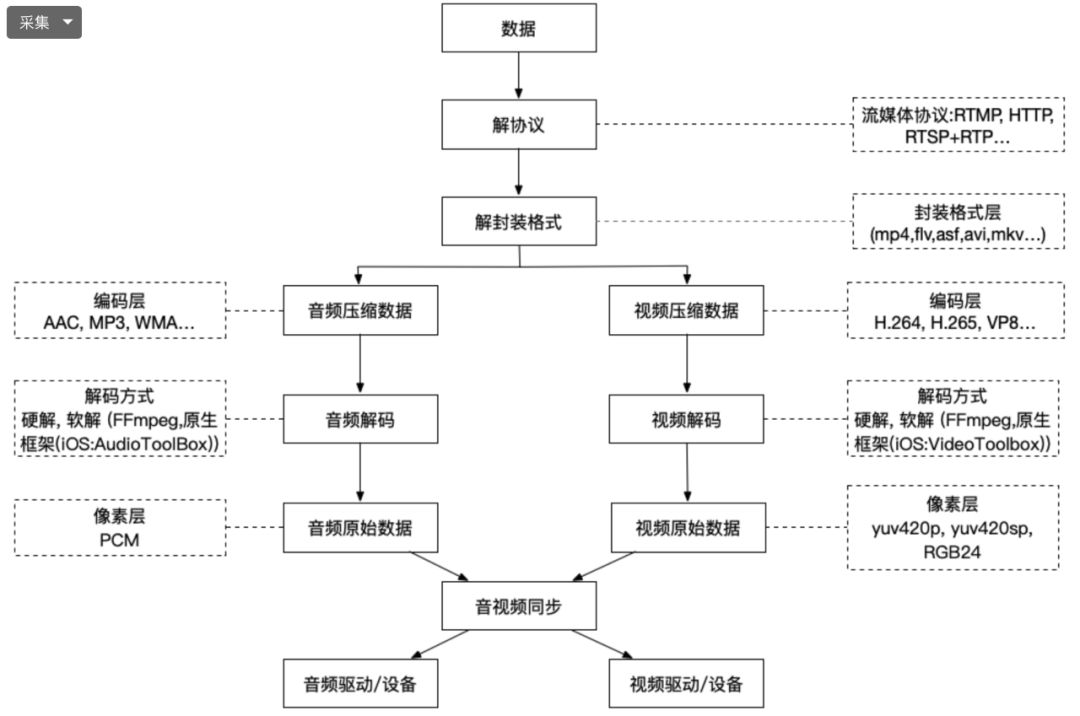
将播放端传来的视频数据在手机上播放,推流的逆过程,即将windows, linux, web端传来的视频数据进行解码后传给对应音视频硬件,最终将视频渲染在手机界面上播放.
拉流如下:
具体剖析
推流,拉流实际为互逆过程,这里按照从采集开始介绍.
1. 采集
采集是推流的第一个环节,是原始的音视频数据的来源.采集的原始数据类型为音频数据PCM,视频数据YUV,RGB…
1.1. 音频采集
深入研究
iOS Core Audio简介
iOS Audio Session管理音频上下文
iOS Audio Queue采集播放音频数据
iOS Audio Queue采集音频数据实战
iOS Audio Unit采集音频数据
iOS Audio Unit采集音频数据实战
采集来源
内置麦克风
外置具有麦克风功能的设备(相机,话筒…)
系统自带相册
音频主要参数
采样率(samplerate): 模拟信号数字化的过程,每秒钟采集的数据量,采样频率越高,数据量越大,音质越好。
声道数(channels): 即单声道或双声道 (iPhone无法直接采集双声道,但可以模拟,即复制一份采集到的单声道数据.安卓部分机型可以)
位宽: 每个采样点的大小,位数越多,表示越精细,音质越好,一般是8bit或16bit.
数据格式: iOS端设备采集的原始数据为线性PCM类型音频数据
其他: 还可以设置采样值的精度,每个数据包有几帧数据,每帧数据占多少字节等等.
音频帧
音频与视频不同,视频每一帧就是一张图片,音频是流式,本身没有明确的帧的概念,实际中为了方便,取2.5ms~60ms为单位的数据为一帧音频.
计算
数据量(字节 / 秒)=(采样频率(Hz)* 采样位数(bit)* 声道数)/ 8
单声道的声道数为1,立体声的声道数为2. 字节B,1MB=1024KB = 1024*1024B
1.2. 视频采集
深入研究
iOS AVCaptureSession采集视频数据
iOS AVCaptureSession采集视频数据Demo)
视频原始数据YUV介绍
采集来源
摄像头
屏幕录制
外置带摄像头采集功能的设备(相机,DJI无人机,OSMO…)
系统自带相册
注意: 像一些外置摄像头,如像利用摄像机的摄像头采集,然后用手机将数据处理编码并发出,也是可以的,但是数据的流向需要我们解析,即从摄像头的HDMI线转成网线口,网线口再转USB,USB转苹果Lighting接口,利用FFmpeg可以获取其中的数据.
视频主要参数
图像格式: YUV, RGB (即红黄蓝三种颜色混合组成各种颜色).
分辨率: 当前设备屏幕支持的最大分辨率
帧率: 一秒钟采集的帧数
其他: 白平衡,对焦,曝光,闪光灯等等
计算 (RGB)
一帧数据量 = 分辨率(width * height) * 每个像素的所占字节数(一般是3个字节)
注意上面计算的方法并不是唯一的,因为视频的数据格式有很多种,如YUV420计算方式为分辨率(width * height) * 3/2
1.3. 综上所述
我们假设要上传的视频是1080P 30fps(分辨率:1920*1080), 声音是48kHz,那么每秒钟数据量如下:
video = 1920 * 1080 * 30 * 3 = 186624000B = 186.624 MB
复制代码由此我们可得,如果直接将原始采集的数据进行传输,那么一部电影就需要1000多G的视频,如果是这样将多么恐怖,所以就涉及到我们后面的编码环节。
2. 处理
深入研究 (待添加)
高效裁剪视频
根据声音大小实现音量柱功能
从上一步中,我们可以得到采集到的音频原始数据和视频原始数据,在移动端,一般是通过各自手机平台官方API中拿到, 前文链接中皆有实现的方法.
之后,我们可以对原始数据加以处理,对原始操作处理只能在编码之前,因为编码后的数据只能用于传输. 比如可
美颜
水印
滤镜
裁剪
旋转
…
对音频处理
混音
消除回声
降噪
…
目前流行的有很多大型框架专门用来处理视频,音频,如OpenGL, OpenAL, GPUImage…以上的各种处理网上均有开源的库可以实现,基本原理就是,我们拿到原始的音视频帧数据,将其送给开源库,处理完后再拿到处理好的音视频继续我们自己的流程.当然很多开源库仍需要根据项目需求略微更改并封装.
3.编码
深入研究
iOS视频视频编码
iOS音频音频编码
3.1. 为什么要编码
在第1.步采集最后已经讲到,原始的视频每秒钟就产生200多MB,如果直接拿原始数据传输,网络带宽即内存消耗是巨大的,所以视频在传输中是必须经过编码的.
类似的例子就像我们平常搬家,如果直接搬家,东西很零散,需要跑很多趟拿,如果将衣服,物品打包,我们仅仅需要几个行李箱就可以一次搞定.等我们到达新家,再将东西取出来,重新布置,编解码的原理就是如此.
3.2. 有损压缩 VS 无损压缩
有损压缩
视频利用人眼的视觉特性, 以一定的客观失真换取数据的压缩,比如人眼对亮度识别的阈值,视觉阈值,对亮度和色度的敏感度不同,以至于可以在编码时引入适量误差,不会被察觉出来.
音频利用了人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息;去除声音中冗余成分的方法实现。冗余成分指的是音频中不能被人耳朵察觉的信号,它们对声音的音色,音调等信息没有任何帮助。重构后的数据与原来的数据有所不同,但不影响人对原始资料表达的信息造成误解。
有损压缩适用于重构信号不一定非要和原始信号完全相同的场合。
无损压缩
视频的空间冗余,时间冗余,结构冗余,熵冗余等,即图像的各个像素间存在很强的关联性,消除这些冗余不会导致信息丢失.
音频压缩格式则是利用数据的统计冗余进行压缩,可完全恢复原始数据而不引起任何失真,但压缩率是受到数据统计冗余度的理论限制,一般为2:1到5:1。
正因为有着上面的压缩方法,视频数据量可以极大的压缩,有利于传输和存储.
3.3. 视频编码
原理:
编码是如何做到将很大的数据量变小的呢? 主要原理如下
空间冗余: 图像相邻像素之间有很强的相关性
时间冗余: 视频序列的相邻图像之间内容相似
编码冗余: 不同像素值出现的概率不同
视觉冗余: 人的视觉系统对某些细节不敏感
知识冗余: 规律性的结构可由先前知识和背景知识得到
压缩编码的方法
变换编码 (了解即可,具体请谷歌)
将空间域描述的图像信号变换成频率域,然后对变换后的系数进行编码处理。一般来说,图像在空间上具有较强的相关性,变换频率域可以实现去除相关与能量集中。常用的正交变换有离散傅里叶变换,离散余弦变换等等。
熵编码 (了解即可,具体请谷歌)
熵编码是因编码后的平均码长接近信源熵值而得名。熵编码多用可变字长编码(VLC,Variable Length Coding)实现。其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。可变字长编码通常有霍夫曼编码、算术编码、游程编码等。
运动估计和运动补偿 (重要)
运动估计和运动补偿是消除图像序列时间方向相关性的有效手段。上面介绍的变换编码,熵编码都是在以一帧图像的基础上进行的,通过这些方法可以消除图像内部各像素在空间上的相关性。实际上图像信号除了空间上的相关性外,还有时间上的相关性。例如对于像新闻联播这种背景静止,画面主体运动较小的数字视频,每一幅画面之间的区别很小,画面之间的相关性很大。对于这种情况我们没有必要对每一帧图像单独进行编码,而是可以只对相邻视频帧中变化的部分进行编码,从而进一步减小数据量,这方面的工作是由运动估计和运动补偿来实现的。
a. 运动估计技术
将当前的输入图像分割成若干彼此不相重叠的小图像子块,例如一帧图像为1280720,首先将其以网格状形式分成4045个尺寸为16*16彼此没有重叠的图像块,然后在前一图像或者后一图像某个搜索窗口的范围内为每一个图像块寻找一个与之最为相似的图像块,这个搜寻的过程叫做运动估计。
b. 运动补偿
通过计算最相似的图像块与该图像块之间的位置信息,可以得到一个运动矢量。这样在编码的过程中就可以将当前图像中的块与参考图像运动矢量所指向的最相似的图像块相减,得到一个残差图像块,由于每个残差图像块中的每个像素值都很小,所以在压缩编码中可以获得更高的压缩比。
压缩数据类型
正因为运动估计与运动补偿,所以编码器将输入的每一帧图像根据参考图像分成了三种类型:I帧,P帧,B帧。
I帧: 只使用本帧内的数据进行编码,在编码过程中不需要进行运动估计和运动补偿。
P帧: 在编码过程中使用前面的I帧或P帧作为参考图像的运动补偿,实际是对当前图像与参考图像的差值进行编码。
B帧: 在编码过程中使用前面的I帧或P帧和后面的I帧或P帧进行预测。由此可见,每个P帧利用一帧图像为参考图像。而B帧需要两帧图像作为参考。
实际应用中使用混合编码(变换编码+运动估计,运动补偿+熵编码)
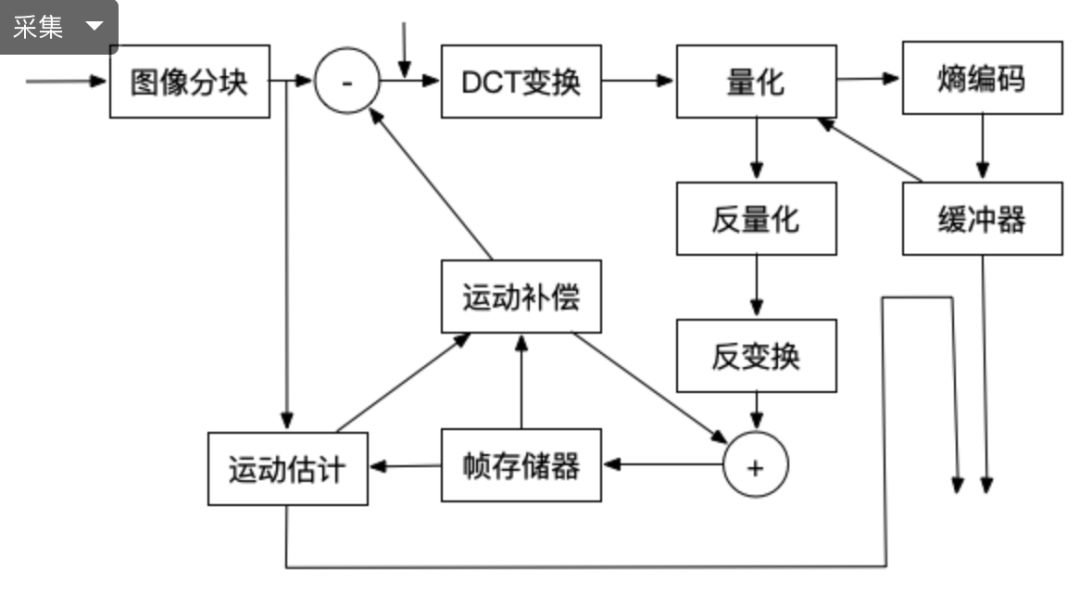
编码器
经过数十年的发展,编码器的功能已经十分强大,种类繁多,下面介绍最主流的一些编码器。
H.264
与旧标准相比,它能够在更低带宽下提供优质视频(换言之,只有 MPEG-2,H.263 或 MPEG-4 第 2 部分的一半带宽或更少),也不增加太多设计复杂度使得无法实现或实现成本过高。
H.265/HEVC
高效率视频编码(High Efficiency Video Coding,简称HEVC)是一种视频压缩标准,被视为是 ITU-T H.264/MPEG-4 AVC 标准的继任者。HEVC 被认为不仅提升视频质量,同时也能达到 H.264/MPEG-4 AVC 两倍之压缩率(等同于同样画面质量下比特率减少了 50%).
VP8
VP8 是一个开放的视频压缩格式,最早由 On2 Technologies 开发,随后由 Google 发布。
VP9
VP9 的开发从 2011 年第三季开始,目标是在同画质下,比 VP8 编码减少 50%的文件大小,另一个目标则是要在编码效率上超越 HEVC 编码。
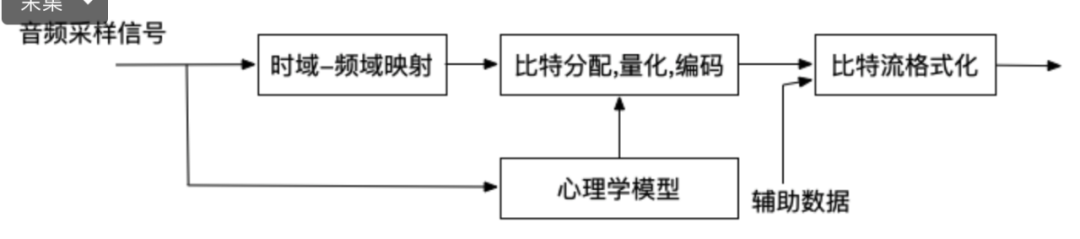
3.4. 音频编码
原理
数字音频压缩编码在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能的压缩。数字音频压缩编码采取去除声音中冗余成分的方法实现。冗余成分指的是音频中不能被人耳朵察觉的信号,它们对声音的音色,音调等信息没有任何帮助。
压缩编码方法
频谱掩蔽
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈。当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应
时域掩蔽
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应,前掩蔽,同时掩蔽,后掩蔽。前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到。
前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到
同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到。
后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽。这些被掩蔽的弱信号即可视为冗余信号。
未完待续
关注微信公众号【纸上浅谈】, Android 开发、Camera、OpenGL、FFmpeg 等音视频和图形图像开发文章~~