模块初识
一、定义
在python中,模块是用来实现某一特定功能的代码集合。其本质上就是以‘.py’结尾的python文件。例如某文件名为test.py,则模块名为test。
二、导入方法
我们在这一节通过举例来向大家简单介绍模块的导入方法。
我们在这里创建一个自定义模块‘module_test’,如下(module_test.py):
name='kobe' def say_hello(): print('hello kobe!')
另新建'import_test.py'并在其中导入模块module_test,方法如下:
import module_test print(module_test.name) print(module_test.say_hello())
代码执行结果如下:

通过上例,我们可以看出import_test.py通过导入模块module_test,取出了module_test中‘name’变量的值,并且运行了函数say_hello。
若想导入导入多个模块,则可‘import module1,module2...’
>>>import module1, module2,...
若想导入某个模块中某个功能或全部功能
>>>from module import * #导入module模块中的全部功能 >>>from module import (功能名) #导入module模块中的某功能
还以上例说明:
from module_test import say_hello as say #导入module_test模块中的say_hello函数功能,并用‘say’来代替函数名 say()
代码执行结果如下:

通过上述例子我们简单总结一下,即导入模块的本质就是把模块python文件解释一遍。
三、‘包’的定义及导入
‘包’本质就是一个目录(创建好之后会自动其目录下生成一个‘_init_.py’文件)。若包下无其他文件,则导入这个包则本质上即是导入包下的‘_init_.py’文件。
例如,若我们创建一个包‘package_age’,并在其下的‘_init_.py’文件中写入:
print('123456')
再创建一个Python文件‘p_test.py’并导入包‘package_age’:
import package_test
则结果为:

四、非同级目录下的模块导入
若主代码与想要导入的Python文件不在同一级目录下,则不能导入,在导入时会优先在当前路径下去寻找相应的python模块。
例如我们想在目录‘module_test’下的python文件‘main.py’中导入目录‘test4’下的'p_test.py'的python文件(如下图)。
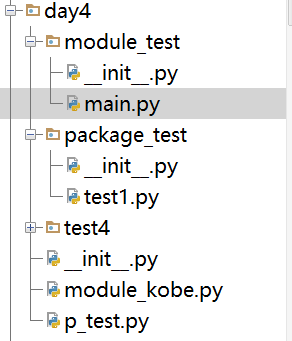
程序实现如下 :
#main.py from module_kobe import * logger()
#module_kobe.py name='kobe bryant' def say_hello(): print('hello kobe!') def logger(): print('in the module')
代码执行结果如下:

即显示差找不到模块‘module_kobe’。
那么若我们想导入不在同一目录下的模块怎么做呢?这就需要使用‘os’和‘sys’模块来将想要导入模块所在的路径加载到主程序中,还以上述为例,代码编写如下:
import sys,os print(sys.path) #以列表的形式打印当前文件所在的路径 print(os.path.abspath(__file__)) #打印当前文件所在的绝对路径 print(os.path.dirname(os.path.abspath(__file__))) #打印当前文件所在目录 print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #打印当前文件所在目录的上一级目录 sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #将当前文件所在目录的上一级目录加载过来 from module_kobe import * logger()
代码执行结果如下:

可以看到我们实现了导入非同级目录下的python自定义模块功能,其中关于‘os’和‘sys’模块我们在后面会有详细介绍。
五、模块分类
python中常用的模块主要分为三种:a. 开源模块,b. 自定义模块,c. 标准库(内置模块)。
其中前两种都是程序员自己编写的模块,其中开源模块可以供他人使用,自定义模块一般就是自己使用,上述章节介绍的就是自定义模块。而标准库(内置模块)是python自带的模块,我们写程序时可以直接拿来使用的。
接下来我们简单介绍几个常用的内置模块。
一、时间模块——time与datetime
在python中,通常有这几种方式来表示时间——a. 格式化的时间字符串,b. 时间戳,和表示时间的元组(struct_time)。
首先,格式化的字符串即我们通常意义下的用来表示时间的形式,形如:‘2019-08-29 20:39:40’表示2019年8月29日20时39分40秒。
其次,关于时间戳,我们首先要向大家介绍一下几个概念:
UTC(Coordinated Universal Time,世界协调时间),即格林威治天文时间、世界标准时间,在中国为UTC+8(即比标准时间早八个小时 )。
DST(Daylight Saving Time,夏时制,夏时令):又称“日光节约时制”和“夏令时间”,是一种为节约能源而人为规定地方时间的制度,在这一制度实行期间所采用的统一时间称为“夏令时间”。
时间戳(time stamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,我们可以用‘time.time()’来获取当前的时间戳,如下:
>>>import time >>>time.time() 1567083047.565318
还有一个是元组(struct_time),获取struct_time的方法如下:
>>>import time >>> time.localtime() time.struct_time(tm_year=2019, tm_mon=8, tm_mday=29, tm_hour=20, tm_min=53, tm_sec=2, tm_wday=3, tm_yday=241, tm_isdst=0)
如上,元组struct_time内共有九个元素,依次为:年;月;日;时;分钟;秒;一周的第几天(周一为0,周二为1,以此类推);一年的第几天;是否是夏令时。
接下来向大家简单介绍一下time模块的几个常用方法:
>>> import time >>> time.time() #获取当前时间戳 1567168188.3943985 >>> time.localtime() #获取当前当地时间的struct_time元组 time.struct_time(tm_year=2019, tm_mon=8, tm_mday=30, tm_hour=20, tm_min=30, tm_sec=0, tm_wday=4, tm_yday=242, tm_isdst=0) >>> time.timezone #获取当地的时区,以秒为单位 -28800 >>> time.altzone #UTC时间与夏令时的差值 -32400 >>> time.sleep(2) #睡眠2秒,括号内为可设置的睡眠的秒数 >>> time.gmtime(1567168188.3943985) #将括号内的时间戳转换成UTC下的struct_time元组格式 time.struct_time(tm_year=2019, tm_mon=8, tm_mday=30, tm_hour=12, tm_min=29, tm_sec=48, tm_wday=4, tm_yday=242, tm_isdst=0) >>> time.localtime(1567168188.3943985) #将括号内的时间戳转换成当地的struct_time元组格式(注意与time.gmtime()的差别) time.struct_time(tm_year=2019, tm_mon=8, tm_mday=30, tm_hour=20, tm_min=29, tm_sec=48, tm_wday=4, tm_yday=242, tm_isdst=0)
>>> time.asctime()
'Fri Aug 30 20:56:58 2019'
若想把struct_time元组的格式转换为格式化的字符串的形式:
>>> x=time.localtime() >>> time.strftime('%Y-%m-%d %H:%M:%S',x) #将x以%年-%月-%日 %时:%分钟:%秒的格式输出 '2019-08-30 20:48:52'
同样的,也可以将格式化的字符串装换为struct_time元组格式:
>>> time.strptime('2019-08-30 20:48:52','%Y-%m-%d %H:%M:%S') time.struct_time(tm_year=2019, tm_mon=8, tm_mday=30, tm_hour=20, tm_min=48, tm_sec=52, tm_wday=4, tm_yday=242, tm_isdst=-1)
若想取出struct_time元组格式时间中的某个元素,如下例:
import time x=time.localtime() print(x) print(x.tm_year) print('%d' %x.tm_yday)
代码执行结果如下:
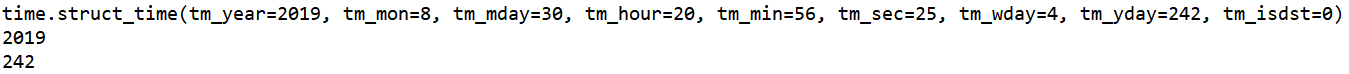
接下来为大家介绍一下datetime模块的使用方法,具体如下:
import datetime print(datetime.datetime.now()) #获取当前时间 print(datetime.datetime.now()+datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now()+datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now()+datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now()+datetime.timedelta(minutes=3)) #当前时间+3分钟 c_time=datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) #修改时间,将分钟改为3,小时改为2
代码执行结果如下:

二、random模块
random模块即随机数模块,它用来生成随机数。具体介绍如下:
>>> import random >>> random.random() #在0到1之间随机取出一个浮点数 0.9835265154729393 >>> random.randint(1,3) #在[1,3]之间随机取出一个整数(包含1和3) 1 >>> random.randint(1,3) 3 >>> random.randrange(1,3) #从range(1,3)即[0,1,2]中随机取出一个整数 1 >>> random.choice('hello') #从字符串‘hello’中随机取出一个字符 'l' >>> random.choice([1,3,5]) #从列表[1,3,5]中随机取出一个数字 5 >>> random.sample('hello',2) #从字符串‘hello’中随机取出2个字符 ['h', 'l'] >>> random.uniform(1,3) #在1到3之间随机取出一个浮点数 1.2706200726679393 >>> l=[1,2,3,4,5,6] >>> random.shuffle(l) #对l进行重新排序 >>> l [6, 4, 2, 5, 3, 1]
那么有了上面的铺垫,我们就可以试着写出一个随机输出验证码的代码如下:
''' 设置一个有4位数字的验证码 ''' import random checkcode='' for i in range (4): #将验证码设置成四位 current=random.randint(0,9) #从0到9之间随机取出一位整数 checkcode += str(current) print(checkcode)
代码执行结果如下:

上例实现了一个比较简单的四位数字的验证码,接下来我们可以尝试写出可以输出含有数字和字母的验证码,且数字和字母的位置数量不固定。
代码实现如下:
''' 设置一个4位的验证码,包含数字和字母 ''' import random checkcode='' for i in range (4): #设置验证码长度为4位 current=random.randint(0,4) #从[0,1,2,3]中随机选择一位整数 if current==i: #若current==i,则输出子母 tmp=chr(random.randint(65,90)) #65到90为26个英文字母对应的ASCII码数字 else: #若current!=i,则输出数字 tmp=random.randint(0,9) checkcode += str(tmp) print(checkcode)
代码实现结果如下:

可以看到我们实现了输出包含数字和字母的四位验证码。
三、os模块
os模块即操作系统模块,它提供对操作系统进行调用的接口。
主要调用方式如下:
import os >>> os.getcwd() #查看当前目录 'C:\\Users\\pc' >>> os.chdir(r'C:\Program Files') #切换路径到C:\Program Files >>> os.getcwd() #查看当前目录 'C:\\Program Files' >>> os.curdir #获取当前目录 '.' #‘.’代表当前目录 >>> os.pardir #获取当前目录的父目录 '..' #'..' 代表上一级目录 >>> os.makedirs(r'D:\a\b\c\d') #递归的创建目录 >>> os.removedirs(r'D:\a\b\c\d') #递归地删除目录 >>> os.chdir(r'D:') #切换路径到D盘 >>> os.makedirs('a') #生成单级目录 >>> os.rmdir('a') #删除单级目录 >>> os.listdir('.') #列出当前目录下的子目录 ['.idlerc', '.jssc', '.LSC', '.packettracer', '.PyCharm40', '.QtWebEngineProcess', '3D Objects', 'AppData', 'Application Data', 'Cisco Packet Tracer 6.2sv', 'Contacts', 'Cookies', 'Desktop', 'Documents', 'Downloads', 'Favorites', 'gsview32.ini', 'IntelGraphicsProfiles', 'Links', 'Local Settings', 'MicrosoftEdgeBackups', 'Music', 'My Documents', 'NetHood', 'NTUSER.DAT', 'ntuser.dat.LOG1', 'ntuser.dat.LOG2', 'NTUSER.DAT{1b051980-cfce-11e9-b42b-005056c00001}.TM.blf', 'NTUSER.DAT{1b051980-cfce-11e9-b42b-005056c00001}.TMContainer00000000000000000001.regtrans-ms', 'NTUSER.DAT{1b051980-cfce-11e9-b42b-005056c00001}.TMContainer00000000000000000002.regtrans-ms', 'ntuser.ini', 'OneDrive', 'Pictures', 'PrintHood', 'PycharmProjects', 'q.log', 'Recent', 'Roaming', 'Saved Games', 'Searches', 'SendTo', 'Templates', 'Videos', 'WebpageIcons.db', '「开始」菜单'] >>> os.remove( ) #删除一个文件 >>> os.rename('oldname','newname') 重命名文件,目录 >>> os.stat('D:') #获取D盘的信息,括号内可为其他文件名或目录名 os.stat_result(st_mode=16895, st_ino=1407374883553285, st_dev=12081982, st_nlink=1, st_uid=0, st_gid=0, st_size=12288, st_atime=1567682975, st_mtime=1567682975,
st_ctime=1495248147) >>> os.sep #输出操作系统特定的路径分隔符,win为‘\\’,Linux为‘/’ '\\' >>> os.linesep #输出当前平台使用的行终止符,win为‘\r\n’,Linux为‘\n’ '\r\n' >>> os.pathsep #输出用于分隔文件路径的字符串 ';' >>> os.environ #显示环境变量 environ({'COMSPEC': 'C:\\WINDOWS\\system32\\cmd.exe', 'CCPKPATH': 'D:\\CTEX\\CTeX\\fonts\\pk\\modeless\\cct\\dpi$d', 'NUMBER_OF_PROCESSORS': ...... >>> os.name #输出字符串指示当前的使用平台,win为‘nt’,Linux为‘posix’ 'nt' >>> os.system('dir') #运行shell命令 >>> os.path.abspath('d:') #输出括号内目录或文件的规范化的绝对路径 'D:\\' >>> os.path.dirname(path) #返回path所在的目录 >>> os.path.exits(path) #判断path是否存在 >>> os.path.isabs(path) #判断是否是绝对路径(以根目录开头) >>> os.path.isfile(path) #判断是否是文件 >>> os.path.getatime(path) #返回path所指向的文件或目录的最后存取时间 >>> os.path.getmtime(path) #返回path所指向的文件或目录的最后修改时间
四、sys模块
接下来简单介绍一下sys模块的功能,如下:
>>> import sys >>> sys.argv #运行命令行参数list,第一个元素是程序本身路径 [''] >>> sys.exit() #退出程序 >>> sys.version #获取python解释程序的版本信息 '3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:18:55) [MSC v.1900 64 bit (AMD64)]'
五、shutil模块
shutil模块是一个高级的文件、文件夹、压缩包处理模块。
接下来简单介绍一下shutil模块的功能。
首先我们可以用shutil模块来复制文件的内容,具体如下:
import shutil f1=open('本节笔记',encoding='utf-8') f2=open('本节笔记2','w',encoding='utf-8') shutil.copyfileobj(f1,f2) #将'本节笔记'内的内容复制到'本节笔记2'中
同样可以起到复制文件功能的还有shutil.copyfile(),具体如下:
import shutil shutil.copyfile('笔记','笔记2') #将文件'笔记'的内容复制到'笔记2'中
同时,shutil模块还可以实现压缩文件的功能,介绍如下:
>>>shutil.make_archive(basename,format,root_dir)
其中,basename为压缩包的文件名,也可以是压缩包的路径。format为压缩包的种类,可以是‘zip’,'tar','bztar','gztar'。'root_dir'为要压缩的文件夹路径。
举例如下:
import shutil import os print(os.getcwd()) #获取当前路径 shutil.make_archive('shutil_archive_test','zip','D:\python3.5\day5') #将文件'D:\python3.5\day5'以zip的形式压缩为'shutil_archive_test'
同时,shutil模块还可以其他的一些简单功能,介绍如下:
>>>shutil.copy(src,dst) #拷贝文件和权限 >>>shutil.copy2(src,dst) #拷贝文件和权限 >>>shutil.copytree(src,dst) #递归地拷贝文件 >>>shutil.rmtree(src) #递归删除目录 >>>shutil.move(src,dst) #递归地移动文件
五、xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟jason差不多,但jason使用起来更加简单。不过在jason没诞生之前,大家只能选择用xml,至今仍有许多公司如金融行业的很多系统的接口还主要
是xml。
xml是通过< >节点来区别数据结构的,格式如下:
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year updated_by="han">2010</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year updated_by="han">2013</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year updated_by="han">2013</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
上述代码描述了三个国家的GDP和邻国等信息,我们可以看到这有点类似于字典。那么我们如何对xml进行处理呢?
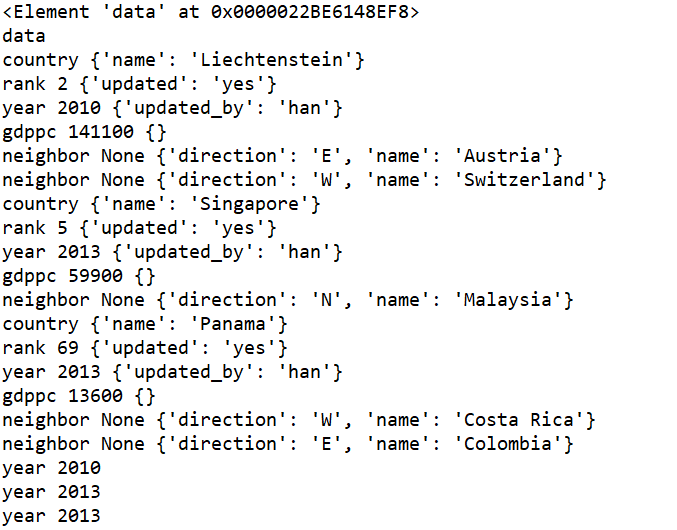
下面我们尝试着把xml中的节点及其属性打印出来:
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root) #打印根节点 print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) #attrib表示属性 for i in child: print(i.tag,i.text,i.attrib) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text)
代码执行结果如下:
那么如何修改xml中的内容呢?
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 2 #year += 2 node.text = str(new_year) node.set("updated_by","kobe") #添加属性 tree.write("xmltest.xml")
可以看到修改后的xml文件如下:
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year updated_by="kobe">2012</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year updated_by="kobe">2015</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year updated_by="kobe">2015</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
同样的,我们也可以自己创建一个xml文件如下:
import xml.etree.ElementTree as ET new_xml = ET.Element("personinfolist") #根节点 personinfo = ET.SubElement(new_xml,"personinfo",attrib={"enrolled":"yes"}) #创建new_xml的子节点,子节点名为‘name’,子节点属性为"enrolled":"yes" name = ET.SubElement(personinfo,"name") name.text='han s' age = ET.SubElement(personinfo,"age",attrib={"checked":"no"}) #age是name的子节点 sex = ET.SubElement(personinfo,"sex") age.text = '33' #赋值 personinfo2 = ET.SubElement(new_xml,"personinfo",attrib={"enrolled":"no"}) name = ET.SubElement(personinfo2,"name") name.text='duan y' age = ET.SubElement(personinfo2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) #将创建的xml文件命名为"test.xml" ET.dump(new_xml) #打印生成的格式
生成的xml文件如下:
<personinfolist> <personinfo enrolled="yes"> <age checked="no">33</age> <sex /> </personinfo> <personinfo enrolled="no"> <name>duan y</name> <age>19</age> </personinfo> </personinfolist>
六、configparser模块
configparser模块常用来生成和修改常见配置文件。
如常用的配置文件示例如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
那么如何用configparser模块来创建这样一个配置文件呢?
如下:
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9'} config['bitbucket.org'] = {} config['bitbucket.org']['User'] = 'hg' config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = '50022' # mutates the parser topsecret['ForwardX11'] = 'no' # same here config['DEFAULT']['ForwardX11'] = 'yes' with open('example.ini', 'w') as configfile: config.write(configfile)
那么,如果我们想要读取其中的某些内容该如何去做呢?
import configparser conf=configparser.ConfigParser() conf.read('example.ini') print(conf.defaults()) #打印默认 print(conf.sections()) #打印节点 print(conf['bitbucket.org']['User']) sec=conf.remove_section('bitbucket.org') conf.write(open('example.cfg','w'))
代码实现结果如下:

七、hashlib模块
hashlib模块用于实现加密相关的操作,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法。
下面的例子实现了对某句话的加密。
import hashlib m=hashlib.md5() #md5加密 m.update(b'hello') print(m.hexdigest()) #十六进制加密 m.update(b'it is me') print(m.hexdigest()) m2=hashlib.md5() m2.update(b'helloit is me') print(m2.hexdigest()) s2=hashlib.sha1() s2.update(b'helloit is me') print(s2.hexdigest())
代码运行结果如下:
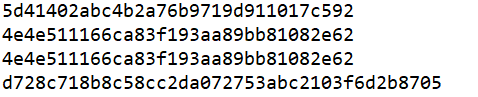
我们可以看到用SHA1加密算法加密后的结果要比用MD5加密要复杂。
八、hmac模块
hmac模块可使内部通过对我们创建key和内容再进行处理后加密。举例如下:
import hmac h=hmac.new(b'123','长亭外,古道边,芳草碧连天'.encode(encoding='utf-8')) print(h.hexdigest())
代码执行结果如下:
我们可以看到这实现了加密的效果。
九、re模块
re模块用做正则表达式,一些常用的正则表达式符号可参见https://www.cnblogs.com/alex3714/articles/5161349.html。
我们在这里简单演示演示一下一些常见的匹配语法:
>>> import re >>> re.match('^han','hanshuo') <_sre.SRE_Match object; span=(0, 3), match='han'> >>> re.match('^han','hanshuo').group() 'han' >>> re.match('.','123ko').group() '1' >>> re.search('R[a-zA-Z]+a','chen123RongAhuaRonghua##').group() 'RongAhuaRonghua' >>> re.search('#.+#','123#hello#').group() '#hello#' >>> re.search('(?P<id>[0-9]+)(?P<name>[a-zA-Z]+)','abcd1234daf@').group() '1234daf' >>> re.search('(?P<id>[0-9]+)(?P<name>[a-zA-Z]+)','abcd1234daf@').groupdict() {'id': '1234', 'name': 'daf'} >>> re.split('[0-9]','abc12de3fr45gh') #分割 ['abc', '', 'de', 'fr', '', 'gh'] >>> re.sub('[0-9]+','1','abc52de3fr45gh',count=2) #替换,count是替换次数 'abc1de1fr45gh'