2019独角兽企业重金招聘Python工程师标准>>> 
本节主要讲解FileMessageSet
Kafka使用FileMessageSet来管理日志文件,对应磁盘上的一个真正的文件。
一开始没找到这个类
后来下了0.10版本看了下,才知道在0.11版本这个类没了,不知道是删除了还是转移了。在0.10.0中,Kafka使用FileMessageSet管理日志文件。
它对应着磁盘上的一个真正的日志文件。
看一下类的继承关系
@nonthreadsafe
class FileMessageSet private[kafka](@volatile var file: File,
private[log] val channel: FileChannel,
private[log] val start: Int,
private[log] val end: Int,
isSlice: Boolean) extends MessageSet with Logging {/**
* A set of messages with offsets. A message set has a fixed serialized form, though the container
* for the bytes could be either in-memory or on disk. The format of each message is
* as follows:
* 8 byte message offset number
* 4 byte size containing an integer N
* N message bytes as described in the Message class
*/
abstract class MessageSet extends Iterable[MessageAndOffset] {MessageSet中保存的数据格式分为3部分:
1) 8字节的offset
2) 4字节的size表示data的大小
3) data表示真正的数据
1)+2)--->LogOverhead
这个从上面的注释也可以看得出来
/**
* A set of messages with offsets. A message set has a fixed serialized form, though the container
* for the bytes could be either in-memory or on disk. The format of each message is
* as follows:
* 8 byte message offset number
* 4 byte size containing an integer N
* N message bytes as described in the Message class
*/不用关注细节,只要知道这里面包含了哪些信息点就足够了,协议都是人定的!
下面开始聊Message的格式,我们打开这个类
/**
* Constants related to messages
*/
object Message {
/**
* The current offset and size for all the fixed-length fields
*/
val CrcOffset = 0
val CrcLength = 4
val MagicOffset = CrcOffset + CrcLength
val MagicLength = 1
val AttributesOffset = MagicOffset + MagicLength
val AttributesLength = 1
// Only message format version 1 has the timestamp field.
val TimestampOffset = AttributesOffset + AttributesLength
val TimestampLength = 8
val KeySizeOffset_V0 = AttributesOffset + AttributesLength
val KeySizeOffset_V1 = TimestampOffset + TimestampLength
val KeySizeLength = 4
val KeyOffset_V0 = KeySizeOffset_V0 + KeySizeLength
val KeyOffset_V1 = KeySizeOffset_V1 + KeySizeLength
val ValueSizeLength = 4下面是各个字段的含义
crc---4个字节,消息的校验码,防止消息错误
magic---1个字节,魔数,取值为0或者1,影响了消息的长度和格式。
attributes:1字节,消息的属性,比如压缩类型,时间戳类型,创建时间/追加时间等。
读者可以理解为一些meta信息点。
timestamp: 时间戳信息,由上面的字段负责解释具体含义。
key:你懂的,不解释
value:你懂的,不解释
------------------------------------------------------------------------------
有2个比较关键的方法:
1)writeTo---写消息
/**
* Write some of this set to the given channel.
* @param destChannel The channel to write to.
* @param writePosition The position in the message set to begin writing from.
* @param size The maximum number of bytes to write
* @return The number of bytes actually written.
*/
def writeTo(destChannel: GatheringByteChannel, writePosition: Long, size: Int): Int = {
2)
/**
* Provides an iterator over the message/offset pairs in this set
*/
def iterator: Iterator[MessageAndOffset]
提供迭代器,顺序读取MessageSet中的消息这个很好理解,写了就要读,MessageSet具有顺序写入和读取的特性。
在Kafka里,一切都是顺序IO---上面聊的是MessageSet抽象类以及其中保存消息的格式,我们开始分析FileMessageSet实现类
先看下类的定义
/**
* An on-disk message set. An optional start and end position can be applied to the message set
* which will allow slicing a subset of the file.
* @param file The file name for the underlying log data
* @param channel the underlying file channel used
* @param start A lower bound on the absolute position in the file from which the message set begins
* @param end The upper bound on the absolute position in the file at which the message set ends
* @param isSlice Should the start and end parameters be used for slicing?
*/
@nonthreadsafe
class FileMessageSet private[kafka](@volatile var file: File,
private[log] val channel: FileChannel,
private[log] val start: Int,
private[log] val end: Int,
isSlice: Boolean) extends MessageSet with Logging {1)file: java.io.File类型,指向真正的磁盘上的日志文件
2)channel:用于读写此日志文件,我们都知道文件可以拿到channel,如果你写过MappedByteBuffer,你自然知道我说的是啥
3)start/end: FileMessageSet除了表示一个完整的日志文件,还可以表示日志文件分片,start/end就是这个分片的起始位置和结束位置,
4)isSlice:表示此FileMessageSet是否为日志文件的分片
5)_size: FileMessageSet大小,单位字节。如果是分片,就表示分片大小,否则表示FileMessageSet大小。
在操作系统里,进行文件的预分配可以提高写操作的性能。
上面解释了预分配的概念!
然后还是直接上源码吧
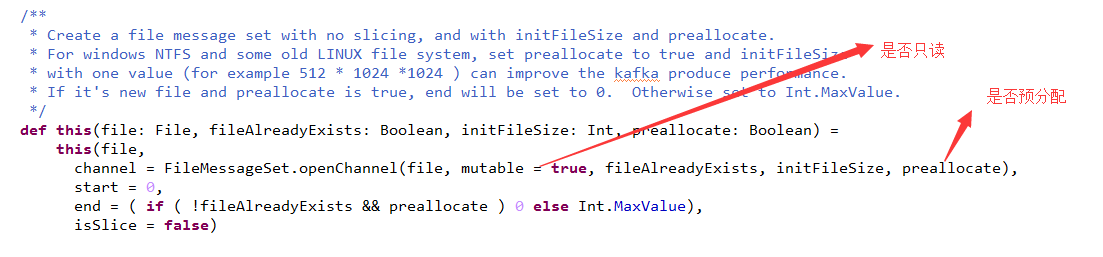
/**
* Create a file message set with no slicing, and with initFileSize and preallocate.
* For windows NTFS and some old LINUX file system, set preallocate to true and initFileSize
* with one value (for example 512 * 1024 *1024 ) can improve the kafka produce performance.
* If it's new file and preallocate is true, end will be set to 0. Otherwise set to Int.MaxValue.
*/
def this(file: File, fileAlreadyExists: Boolean, initFileSize: Int, preallocate: Boolean) =
this(file,
channel = FileMessageSet.openChannel(file, mutable = true, fileAlreadyExists, initFileSize, preallocate),
start = 0,
end = ( if ( !fileAlreadyExists && preallocate ) 0 else Int.MaxValue),
isSlice = false)openChannel的具体实现如下:
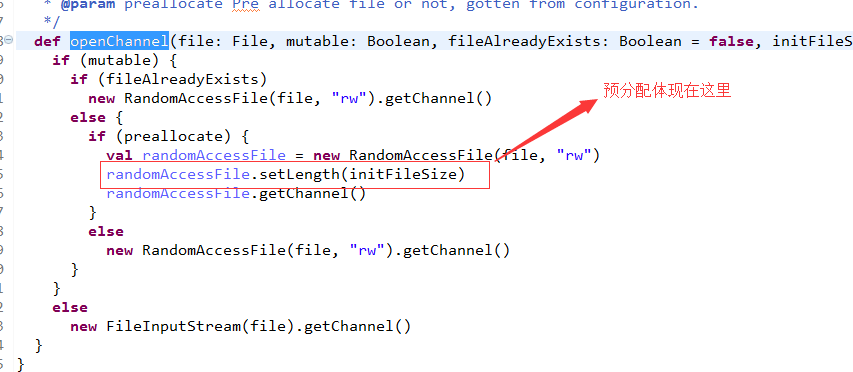
/**
* Open a channel for the given file
* For windows NTFS and some old LINUX file system, set preallocate to true and initFileSize
* with one value (for example 512 * 1025 *1024 ) can improve the kafka produce performance.
* @param file File path
* @param mutable mutable
* @param fileAlreadyExists File already exists or not
* @param initFileSize The size used for pre allocate file, for example 512 * 1025 *1024
* @param preallocate Pre allocate file or not, gotten from configuration.
*/
def openChannel(file: File, mutable: Boolean, fileAlreadyExists: Boolean = false, initFileSize: Int = 0, preallocate: Boolean = false): FileChannel = {
if (mutable) {
if (fileAlreadyExists)
new RandomAccessFile(file, "rw").getChannel()
else {
if (preallocate) {
val randomAccessFile = new RandomAccessFile(file, "rw")
randomAccessFile.setLength(initFileSize)
randomAccessFile.getChannel()
}
else
new RandomAccessFile(file, "rw").getChannel()
}
}
else
new FileInputStream(file).getChannel()
}
}比较简单,一个是是否只读,一个是是否预先分配空间。
---------------------------------------------------------------------------------------------

初始化时,会设置channel的position位置
下面我们来分析读写过程
这个主要是看append函数
我们可以理解为初始化了一个FileMessageSet,然后就可以调用append函数进行写了,当然每次都是在文件的最后进行文件IO.
顺序性嘛! /**
* Append these messages to the message set
*/
def append(messages: ByteBufferMessageSet) {
val written = messages.writeFullyTo(channel)
_size.getAndAdd(written)
}writeFullyTo就是调用channel直接写文件了
下面讲查找文件,函数是searchFor()
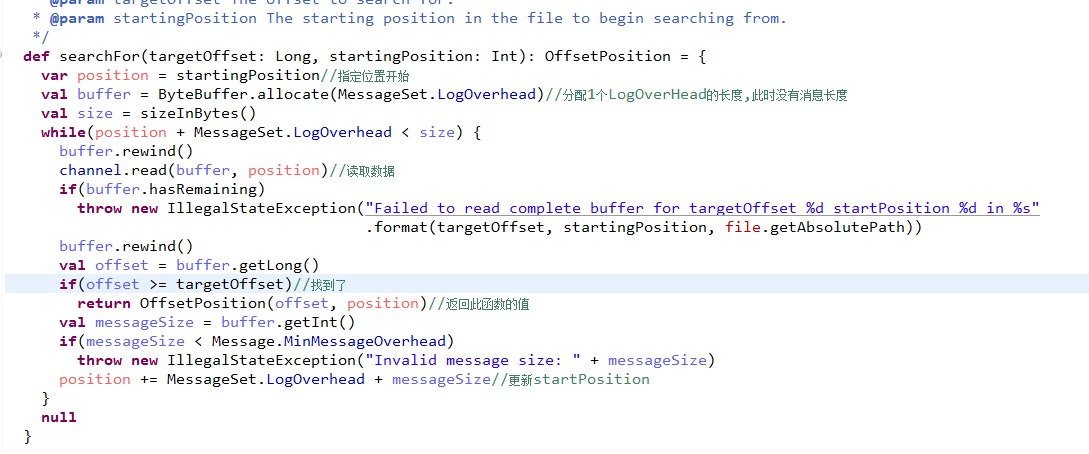
/**
* The mapping between a logical log offset and the physical position
* in some log file of the beginning of the message set entry with the
* given offset.
*/
case class OffsetPosition(offset: Long, position: Int) extends IndexEntry {
override def indexKey = offset
override def indexValue = position.toLong
}也就是标记了position和offset的值!
还有1个writeTo方法,是将数据写入到别的channel.