针对一个长度为n的数组。
[1,2,3,4,5,6,7,8,9]
最快的通用查找类是Dictionary其采用hashcode算法,复杂度为O(1).
而上大学时,最快的查找法为二分查找法,复杂度为O(log(n)).
因此我们得出结论,Dictionary的查找速度应该是最快的。
但是Dictionary里在查找之前必须执行GetHashCode()计算出hashCode.
因此查找效率就是计算hashCode的效率。
如果某种查找算法比计算hashCode的时间要短,也就能超越Dictionary的查找效率。
因此,我开始想办法打造这个查找函数。
//继承原生的查找类
public class FastDictionary<TValue>:Dictionary<string,TValue>{}
//自定义的查找类
public class FastSearch<TValue>{
}
首先两个字符串的对比一般情况下是
public bool compare(string strA,string strB)
{
for(int i=0;i<strA.Length;i++)
{
if(strA[i]!=strB[i])
{
return false;
}
}
return true;
}
以上的情况是对两个字符串中的每一个字符做对比,如果所有的字符都相同,则代表两个字符串相同。
很好理解。但其实还有更快的算法。
在C#中所有的字符串为utf-16格式,即两个字节代表一个字符。而一个long类型是8个字节。也就是说,一个long类型可以存储4个字符。
那么以上的对比函数可以这样写:
public bool Compare(string strA,string strB) { int length=0; int longLength=(length+3)>>2; int remain=0; fixed(char* ptA=&strA) fixed(char* ptB=&strB) { for(int i=0;i<longLength;i++) { if(i==longLength-1) { remain=length&3; if(remain==0) { if(*(long*)(ptA+i*4)==*(long*)(ptB+i*4)) { return false; } } else if(remain==1) { if(*(short*)(ptA+i*4)==*(short*)(ptB+i*4)) { return false; } } else if(remain==2) { if(*(int*)(ptA+i*4)==*(int*)(ptB+i*4)) { return false; } } else if(remain==3) { if(*(long*)(ptA+i*4-1)==*(long*)(ptB+i*4-1)) { return false; } } } if(*(long*)(ptA+i*4)==*(long*)(ptB+i*4)) { return false; } } return true; } }
当字符串中的字符为五个时。前四个字符串转为long类型。第五个字符串转为short类型,然后再转存为long类型
['a','b','c','d','e']
当字符串中的字符为六个时,前四个字符串转为long类型。第五,六个字符串转为int类型,然后再转存为long类型
['a','b','c','d','e','f']
当字符串中的字符为七个时,前四个字符串转为long类型。第四,五,六,七个字符转为long类型
['a','b','c','d','e','f','g']
当字符串中的字符为八个时,前四个字符串转为long类型。后四个字符转为long类型
['a','b','c','d','e','f','g','h']
也就是说,所有的字符串都能转为long数组。
long[] strLong=getLongArray("sdfasdfsfd");
然后再对long数组对行对比,那么效率也快多了。
再进一步,在Compare函数中,需要不断的判断length的长度,以及判断是否是最后一个字符。
其实在已经确定了字符串长度的时候,这些判断代码是不需要的。
因此,可以利用Emit生成对比函数缓存代理,然后再执行,这样的字符串对比效率应该是最快的。
当然最好是在64位操作系统下,这样处理long类型效率比32位系统快。
下面是生成字符串对比的函数的代理函数
public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length); public static CompareDelegate GetCompareDelegate(int length) { TypeBuilder typeBuilder = UnSafeHelper.GetDynamicType(); MethodBuilder dynamicMethod= typeBuilder.DefineMethod("Compare", MethodAttributes.Public | MethodAttributes.Static | MethodAttributes.HideBySig, CallingConventions.Standard, typeof(bool),new Type[]{ typeof(char*),typeof(char*),typeof(int) }); ILGenerator methodIL= dynamicMethod.GetILGenerator(); #region var fourCount = methodIL.DeclareLocal(typeof(int)); //var position = methodIL.DeclareLocal(typeof(int)); var remain = methodIL.DeclareLocal(typeof(int)); int position = 0; var fourEnd = methodIL.DefineLabel(); var methodEnd = methodIL.DefineLabel(); while (position < (length & ~3)) { methodIL.Emit(OpCodes.Ldarg_0); methodIL.Emit(OpCodes.Ldc_I4, position*2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Ldarg_1); methodIL.Emit(OpCodes.Ldc_I4, position * 2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Beq_S, fourEnd); methodIL.Emit(OpCodes.Ldc_I4_0);//false methodIL.Emit(OpCodes.Ret); position += 4; } methodIL.MarkLabel(fourEnd); switch (length & 3) { case 1: { methodIL.Emit(OpCodes.Ldarg_0); methodIL.Emit(OpCodes.Ldc_I4, position*2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I2); methodIL.Emit(OpCodes.Ldarg_1); methodIL.Emit(OpCodes.Ldc_I4, position*2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I2); methodIL.Emit(OpCodes.Beq_S, methodEnd); methodIL.Emit(OpCodes.Ldc_I4_0); methodIL.Emit(OpCodes.Ret); } break; case 2: { methodIL.Emit(OpCodes.Ldarg_0); methodIL.Emit(OpCodes.Ldc_I4, position * 2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I4); methodIL.Emit(OpCodes.Ldarg_1); methodIL.Emit(OpCodes.Ldc_I4, position * 2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I4); methodIL.Emit(OpCodes.Beq_S, methodEnd); methodIL.Emit(OpCodes.Ldc_I4_0); methodIL.Emit(OpCodes.Ret); } break; case 3: { position--; methodIL.Emit(OpCodes.Ldarg_0); methodIL.Emit(OpCodes.Ldc_I4, position * 2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Ldarg_1); methodIL.Emit(OpCodes.Ldc_I4, position * 2); methodIL.Emit(OpCodes.Add); methodIL.Emit(OpCodes.Ldind_I8); methodIL.Emit(OpCodes.Beq_S, methodEnd); methodIL.Emit(OpCodes.Ldc_I4_0); methodIL.Emit(OpCodes.Ret); } break; } #endregion methodIL.MarkLabel(methodEnd); methodIL.Emit(OpCodes.Ldc_I4_1); methodIL.Emit(OpCodes.Ret); Type t= typeBuilder.CreateType(); MethodInfo method= t.GetMethod("Compare"); Delegate delete = Delegate.CreateDelegate(typeof(CompareDelegate), method); return (CompareDelegate)delete; }
那么基于对以上函数的认识,有两个是需要明确的。
1.利用Emit可以省略掉一部分判断代码。
2.利用long类型可以一次判断4个字符,加快字符串的对比速度。
那么字符串的查找问题就能转换为long类型的查找问题。这时候很容易就能想到二分查找。
假如有以下字符串。
string[] keys={“aa”,"bb","ccc","dddd"};
从中查出"bb"字符串所在的索引。
先根据字符串中的字符转为byte整型
['a','a']=>[97,97,0,0]
['b','b']=>[98,98,0,0]
['c','c','c']=>[99,99,99,0]
['d','d','d','d']=>[100,100,100,100]
那么整体的二维数组为:
[097,097,000,000]
[098,098,000,000]
[099,099,099,000]
[100,100,100,100]
是不是很像高数中的矩阵?
那么这个二维数组共四行四列。
在第一列中有97,98,99,100四个值。
这四个值先进行排序。然后再选出中间值。利用二分法。进行代码生成。
即:if(str[0]<99){}else{}
或:if(str[0]>98{}else{}.
这样的话,就可以把以上四组分为两组。
即组A:
[097,097,000,000]
[098,098,000,000]
与组B:
[099,099,099,000]
[100,100,100,100]
在组A中。再利用二分法。
if(str[0]<98){
return 0;//数组下标
}else{
return 1;
}
在组B中。利用二分法.
if(str[0]<100){
return 2;
}else{
return 3;
}
这种近似的二分查找法,应该是查找速度非常快的。下面整理一下思路。
1.首先把数组转换为整数数组。
2.对二维数组中的第一列进行排序,找出中间值。
3.如果第一列中没有找到中间值,就查找第二列。直到找到最优的中间值为止。
4.根据最优中间值生成if...else...代码。并把二维数据分为二组。
5.再根据以上思路继续分组,直到不能分为止。
6.返回所在字符串的数组索引。
但是以上思路存在一个问题。如果字符串的长度不固定。其中长度较短的字符串需要用0补位。
也就是说在取值的时候需要判断字符串的长度。
也就是说,整体思路,应该是这样。
首先,把一组字符串中相同长度的字符串进行分组。
然后再利用以上的方法生成近似的二分查找函数。
那么相同长度的字符串分组需要一个函数进行查找。
分组数据为:
public class GroupData<TValue> { //字符串长度 public int length; //优化的二分查找函数,长度固定 public FindDelegate findDelegate; //优化过的字符串比较函数 public CompareDelegate compareDelegate; public List<KV<TValue>> list; }
其中List<KV<TValue>> list是存储字符串的列表。KV是一个存储key以及value的泛型体。key为string类型:
public struct KV<TValue> { public KV(string key, TValue value,int index) { this.key = key; this.length = key.Length; this.value = value; this.index = index; } public string key; public int length; public int index; public TValue value; }
整体的搜索类如下:
public unsafe delegate int FindDelegate(char* keyChar); public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length); public delegate int FindGroupIndexDelegate(int length); public class FastSearch<TValue> where TValue : class { GroupData<TValue>[] groupArray; public FindGroupIndexDelegate findGroupIndexDelegate; public unsafe FastSearch(Dictionary<string, TValue> originalDictionary) { GroupData<TValue> groupData; int index = 0; SortedList<int, GroupData<TValue>> groupList = new SortedList<int, GroupData<TValue>>(); foreach (var kv in originalDictionary) { if (groupList.TryGetValue(kv.Key.Length, out groupData)) { index = groupList.Count; groupData.list.Add(new KV<TValue>(kv.Key, kv.Value, index)); } else { groupData = new GroupData<TValue>(); //快速比较函数,应用long指针,一次比较4个字符 groupData.compareDelegate = CompareDelegateHelper.GetCompareDelegate(kv.Key.Length); groupData.length = kv.Key.Length; groupData.list = new List<KV<TValue>>(); groupData.list.Add(new KV<TValue>(kv.Key, kv.Value, index)); groupList.Add(kv.Key.Length, groupData); } } groupArray = groupList.Values.ToArray(); groupList.Clear(); //二分查长相同长度的字符串组下标 findGroupIndexDelegate = FindGroupIndexDelegateHelper.GetFindGroupIndexDelegate(groupArray); for (int i = 0; i < groupArray.Length; i++) { //生成在长度相同的字符串中快速查找的函数 groupArray[i].findDelegate = FastFindSameLengthStringHelper.GetFastFindSameLengthStringDelegate(groupArray[i].list, groupArray[i].length); } //originalDictionary.Clear(); } public unsafe bool TryGetValue(string key, int length,out TValue value) { GroupData<TValue> group = groupArray[findGroupIndexDelegate(length)]; int index; fixed (char* keyChar = key) { index = group.findDelegate(keyChar); value = group.list[index].value; string comparekey = group.list[index].key; fixed (char* complareKeyChar = comparekey) { return group.compareDelegate(keyChar, complareKeyChar, length); } } } }
最前面三个是代理
public unsafe delegate int FindDelegate(char* keyChar); public unsafe delegate bool CompareDelegate(char* keyChar, char* CompareKeyChar,int length); public delegate int FindGroupIndexDelegate(int length);
FindDelegate是查找函数。参数为字符串指针。返回为相同长度字符串列表中的字符串下标。
CompareDelegate是字符串比较函数。参数为两字符串指针,以及两字符串长度。
FindGroupIndexDelegate是查找分组的代理函数。
以上三个代理会在FastSearch初始化的时候初始化。而在查找的时候直接调用。
其中CompareDelegate的Emit代码前面已经给出。
FindDelegate的Emit代码为:
public class FindGroupIndexDelegateHelper { public static FindGroupIndexDelegate GetFindGroupIndexDelegate<TValue>(GroupData<TValue>[] groupDataArray) { TypeBuilder typeBuilder = UnSafeHelper.GetDynamicType(); MethodBuilder dynamicMethod = typeBuilder.DefineMethod("FindGroupIndexDelegate", MethodAttributes.Public | MethodAttributes.Static | MethodAttributes.HideBySig, CallingConventions.Standard, typeof(int), new Type[] { typeof(int) }); var methodIL = dynamicMethod.GetILGenerator(); GenerateFindGroupIndexDelegate(methodIL, groupDataArray, 0, groupDataArray.Length - 1); Type t = typeBuilder.CreateType(); MethodInfo method = t.GetMethod("FindGroupIndexDelegate"); return (FindGroupIndexDelegate)Delegate.CreateDelegate(typeof(FindGroupIndexDelegate), method); } public static void GenerateFindGroupIndexDelegate<TValue>(ILGenerator methodIL,GroupData<TValue>[] groupDataArray, int left, int right) { int middle = (right + left + 1) >> 1; int lessThanValue = groupDataArray[middle].length; var elseStatement = methodIL.DefineLabel(); methodIL.Emit(OpCodes.Ldarg_0); methodIL.Emit(OpCodes.Ldc_I4,lessThanValue); methodIL.Emit(OpCodes.Bge_S, elseStatement); //if if (middle == left + 1) { methodIL.Emit(OpCodes.Ldc_I4, left); methodIL.Emit(OpCodes.Ret); } else { GenerateFindGroupIndexDelegate(methodIL, groupDataArray, left, middle - 1); } //else methodIL.MarkLabel(elseStatement); if (middle == right) { methodIL.Emit(OpCodes.Ldc_I4, right); methodIL.Emit(OpCodes.Ret); } else { GenerateFindGroupIndexDelegate(methodIL,groupDataArray,middle,right); } } }
FindGroupIndexDelegate的Emit代码为:
public class FastFindSameLengthStringHelper { public class Node { /// <summary> /// 对比的数字 /// </summary> public long compareValue; /// <summary> /// if 语句节点 /// </summary> public Node ifCase; /// <summary> /// else语句节点 /// </summary> public Node elseCase; /// <summary> /// 节点的类型 /// </summary> public NodeType nodeType; /// <summary> /// 对比的列数 /// </summary> public int charIndex; /// <summary> /// 当只有一个元素时,返回该元素的索引 /// </summary> public int arrayIndex; } public enum NodeType { CompareCreaterThan, CompareLessThan, SetIndex } public struct ColumnCompareData { public int[] ColumnSort; public bool hasMidValue; public long midValue; public int midValueIndex; public int midIndex; public LongCompare compare; public int[] ColumnBig; public int[] ColumnSmall; public int midDistance; } public enum LongCompare { LessThan, CreaterThan } public unsafe static FindDelegate GetFastFindSameLengthStringDelegate<TValue>(List<KV<TValue>> list, int length) { int rowCount = list.Count; int columnLength = (length + 3) >> 2; long[][] KeyLongArray = new long[rowCount][]; for (int row = 0; row < rowCount; row++) { fixed (char* pKey = list[row].key) { KeyLongArray[row] = new long[columnLength]; for (int col = 0; col < columnLength; col++) { if (col == columnLength - 1) { int remain = length & 3; if (remain == 0) { KeyLongArray[row][col] = *(long*)(pKey + col * 4); } else if (remain == 1) { KeyLongArray[row][col] = *(short*)(pKey + col * 4); } else if (remain == 2) { KeyLongArray[row][col] = *(int*)(pKey + col * 4); } else if (remain == 3) { KeyLongArray[row][col] = *(long*)(pKey + col * 4 - 1); } } else { KeyLongArray[row][col] = *(long*)(pKey + col * 4); } } } } // 列排序索引,用于对Long二维数组列进行排序 int[][] ColumnSortArray = new int[columnLength][]; //初始化列索引数组 for (int column = 0; column < columnLength; column++) { ColumnSortArray[column] = new int[rowCount]; for (int row = 0; row < rowCount; row++) { ColumnSortArray[column][row] = row; } } Node rootNode = new Node(); Init(KeyLongArray,KeyLongArray,columnLength, ColumnSortArray, ref rootNode); ILWriter iLWriter = new ILWriter(); return iLWriter.Generate(rootNode, length, columnLength); } public static void Init(long[][] FullKeyLongArray, long[][] KeyLongArray,int columnLength, int[][] ColumnSortArray, ref Node codeNode) { if (KeyLongArray == null) return; if (FullKeyLongArray.Length == 1) { codeNode.nodeType = NodeType.SetIndex; codeNode.arrayIndex = 0; return; } // KeyValue数组长度 int arrayLength = KeyLongArray.Length; //是否为奇数数组 bool isEvenArray = (arrayLength & 1) == 0; //找到的最好中分的那个列 int BestColumnCompareDataIndex = 0; //数组为奇数长度时,最中间的索引值 int midIndex = 0; //数组为偶数长度时,中间左右两边的值 int midLeftIndex, midRightIndex = 0; //距中间值的距离 int midDistance = 0; //距中间值的最长距离 int midDistanceLength = 0; //是否具有中间值,如果一个列中所有元素均相同,则无中间值 bool hasMidValue = false; //是否找到了直接二分值 bool hasFindBestColumnCompareDataIndex = false; //数组中每列比较的结果 ColumnCompareData[] columnCompareData = new ColumnCompareData[columnLength]; ; //一列一列的解析出比较结果,如二分值,索引等 for (int column = 0; column < columnLength; column++) { //对列索引数组进行排序 Array.Sort<int>(ColumnSortArray[column], new KeyLongArrayCompare(FullKeyLongArray, column)); //是否有二分值 hasMidValue = false; //如果数组长度为偶数 if (isEvenArray) { //中间距两边的距离 midDistanceLength = arrayLength >> 1; //中间靠左边的索引值 midLeftIndex = (arrayLength >> 1) - 1; //中间靠右边的索引值 midRightIndex = midLeftIndex + 1; //找到与中间值值不同的行,并记录下来。 long LeftValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midLeftIndex], column); long RightValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midRightIndex], column); //[1][2][3][4] //[1][Left]|[Right][4] if (LeftValue != RightValue) { BestColumnCompareDataIndex = column; hasFindBestColumnCompareDataIndex = true; hasMidValue = true; columnCompareData[column].hasMidValue = hasMidValue; columnCompareData[column].midValue = RightValue; columnCompareData[column].midValueIndex = ColumnSortArray[column][midRightIndex]; columnCompareData[column].compare = LongCompare.LessThan; columnCompareData[column].midIndex = midRightIndex; columnCompareData[column].midDistance = 0; break; } else { //[1][2][3][4] for (midDistance = 1; midDistance < midDistanceLength; midDistance++) { //[1]|[Left][3][4],2 if (LeftValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midLeftIndex - midDistance], column)) { hasMidValue = true; columnCompareData[column].hasMidValue = hasMidValue; columnCompareData[column].midValue = LeftValue; columnCompareData[column].midValueIndex = ColumnSortArray[column][midLeftIndex]; columnCompareData[column].compare = LongCompare.LessThan; columnCompareData[column].midIndex = midLeftIndex; columnCompareData[column].midDistance = midDistance; } //[1][2][Right]|[4] if (RightValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midRightIndex + midDistance], column)) { hasMidValue = true; columnCompareData[column].hasMidValue = hasMidValue; columnCompareData[column].midValue = RightValue; columnCompareData[column].midValueIndex = ColumnSortArray[column][midRightIndex]; columnCompareData[column].compare = LongCompare.CreaterThan; columnCompareData[column].midIndex = midRightIndex; columnCompareData[column].midDistance = midDistance; } } } } //如果数组长度为奇数 else { //中间到两边的距离 midDistanceLength = arrayLength >> 1; //中间值的索引 midIndex = (arrayLength >> 1); //找出与中间值不同的行 //[1][2][mid][3][4] long midValue = GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex], column); for (midDistance = 0; midDistance < midDistanceLength; midDistance++) { //[1][2]|[mid][3][4] if (midValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex - midDistance - 1], column)) { hasMidValue = true; columnCompareData[column].hasMidValue = hasMidValue; columnCompareData[column].midValue = midValue; columnCompareData[column].midValueIndex = ColumnSortArray[column][midIndex - midDistance - 1]; columnCompareData[column].compare = LongCompare.LessThan; columnCompareData[column].midIndex = midIndex; columnCompareData[column].midDistance = midDistance; if (midDistance == 0) { BestColumnCompareDataIndex = column; hasFindBestColumnCompareDataIndex = true; break; } } //[1][2][mid]|[3][4] if (midValue != GetKeyLong(FullKeyLongArray, ColumnSortArray[column][midIndex + midDistance + 1], column)) { hasMidValue = true; columnCompareData[column].hasMidValue = hasMidValue; columnCompareData[column].midValue = midValue; columnCompareData[column].compare = LongCompare.CreaterThan; columnCompareData[column].midValueIndex = ColumnSortArray[column][midIndex + midDistance + 1]; columnCompareData[column].midIndex = midIndex; columnCompareData[column].midDistance = midDistance; if (midDistance == 0) { BestColumnCompareDataIndex = column; hasFindBestColumnCompareDataIndex = true; break; } } } } } //如果没有直接找到了二分索引 if (!hasFindBestColumnCompareDataIndex) { //距离中间最小的距离 int minMidDistance = midDistanceLength; //找到最合适的二分索引,即距两边距离最短的 for (int column = 0; column < columnLength; column++) { if (columnCompareData[column].midDistance < minMidDistance) { minMidDistance = columnCompareData[column].midDistance; BestColumnCompareDataIndex = column; } } } //两个数组Big和Small long[][] KeyLongArrayBig = null; long[][] KeyLongArraySmall = null; int[][] ColumnSortArrayBig = null; int[][] ColumnSortArraySmall = null; int KeyLongArrayBigLength = 0; int KeyLongArraySmallLength = 0; //[1][2][midValue]|[3][4] if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.CreaterThan) { KeyLongArraySmallLength = columnCompareData[BestColumnCompareDataIndex].midIndex + 1; if (KeyLongArraySmallLength > 0) { KeyLongArraySmall = new long[KeyLongArraySmallLength][]; //初始化排序数组 ColumnSortArraySmall = new int[columnLength][]; for (int column = 0; column < columnLength; column++) { ColumnSortArraySmall[column] = new int[KeyLongArraySmallLength]; } } KeyLongArrayBigLength = arrayLength - columnCompareData[BestColumnCompareDataIndex].midIndex - 1; if (KeyLongArrayBigLength > 0) { KeyLongArrayBig = new long[KeyLongArrayBigLength][]; ColumnSortArrayBig = new int[columnLength][]; for (int column = 0; column < columnLength; column++) { ColumnSortArrayBig[column] = new int[KeyLongArrayBigLength]; } } int smallIndex = 0; int bigIndex = 0; for (int row = 0; row < arrayLength; row++) { if (row > columnCompareData[BestColumnCompareDataIndex].midIndex) { KeyLongArrayBig[bigIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]]; for (int column = 0; column < columnLength; column++) { ColumnSortArrayBig[column][bigIndex] = ColumnSortArray[BestColumnCompareDataIndex][row]; } bigIndex++; } else { KeyLongArraySmall[smallIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]]; for (int column = 0; column < columnLength; column++) { ColumnSortArraySmall[column][smallIndex] = ColumnSortArray[BestColumnCompareDataIndex][row]; } smallIndex++; } } } //[1][2]|[midValue][3][4] else if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.LessThan) { KeyLongArraySmallLength = columnCompareData[BestColumnCompareDataIndex].midIndex; if (KeyLongArraySmallLength > 0) { KeyLongArraySmall = new long[KeyLongArraySmallLength][]; ColumnSortArraySmall = new int[columnLength][]; for (int column = 0; column < columnLength; column++) { ColumnSortArraySmall[column] = new int[KeyLongArraySmallLength]; } } KeyLongArrayBigLength = arrayLength - columnCompareData[BestColumnCompareDataIndex].midIndex; if (KeyLongArrayBigLength > 0) { KeyLongArrayBig = new long[KeyLongArrayBigLength][]; ColumnSortArrayBig = new int[columnLength][]; for (int column = 0; column < columnLength; column++) { ColumnSortArrayBig[column] = new int[KeyLongArrayBigLength]; } } int smallIndex = 0; int bigIndex = 0; for (int row = 0; row < arrayLength; row++) { if (row < columnCompareData[BestColumnCompareDataIndex].midIndex) { KeyLongArraySmall[smallIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]]; for (int column = 0; column < columnLength; column++) { ColumnSortArraySmall[column][smallIndex] = ColumnSortArray[BestColumnCompareDataIndex][row]; } smallIndex++; } else { KeyLongArrayBig[bigIndex] = FullKeyLongArray[ColumnSortArray[BestColumnCompareDataIndex][row]]; for (int column = 0; column < columnLength; column++) { ColumnSortArrayBig[column][bigIndex] = ColumnSortArray[BestColumnCompareDataIndex][row]; } bigIndex++; } } } //解析最终结果到CodeNode节点中,用于生成代码用 if (columnCompareData[BestColumnCompareDataIndex].compare == LongCompare.CreaterThan) { codeNode.nodeType = NodeType.CompareCreaterThan; codeNode.compareValue = columnCompareData[BestColumnCompareDataIndex].midValue; } if(columnCompareData[BestColumnCompareDataIndex].compare==LongCompare.LessThan) { codeNode.nodeType = NodeType.CompareLessThan; codeNode.compareValue = columnCompareData[BestColumnCompareDataIndex].midValue; } //codeNode.ifCase = new Node(); //codeNode.elseCase = new Node(); codeNode.charIndex = BestColumnCompareDataIndex << 2; //[1][2][mid]|[4] if(x>mid){ i=3}else{i=4} //[1][2][mid]|[4][5] if (codeNode.nodeType == NodeType.CompareCreaterThan) { if (KeyLongArrayBigLength == 0) { codeNode.ifCase = null; } else { codeNode = new Node(); } if (KeyLongArrayBigLength == 1) { codeNode.ifCase.nodeType = NodeType.SetIndex; codeNode.ifCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex + 1]; codeNode.ifCase.charIndex = codeNode.charIndex; } else { Init(FullKeyLongArray, KeyLongArrayBig,columnLength, ColumnSortArrayBig, ref codeNode.ifCase); } if (KeyLongArraySmallLength == 0) { codeNode.elseCase = null; } else { codeNode.elseCase = new Node(); } if (KeyLongArraySmallLength == 1) { codeNode.elseCase.nodeType = NodeType.SetIndex; codeNode.elseCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex]; codeNode.elseCase.charIndex = codeNode.charIndex; } else { Init(FullKeyLongArray, KeyLongArraySmall,columnLength, ColumnSortArraySmall, ref codeNode.elseCase); } } //[1][2]|[mid][4][5] if(x<mid){}else{} else if (codeNode.nodeType == NodeType.CompareLessThan) { if (KeyLongArraySmallLength == 0) { codeNode.ifCase = null; } else { codeNode.ifCase = new Node(); } if (KeyLongArraySmallLength == 1) { codeNode.ifCase.nodeType = NodeType.SetIndex; codeNode.ifCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex - 1]; codeNode.ifCase.charIndex = codeNode.charIndex; } else { Init(FullKeyLongArray, KeyLongArraySmall,columnLength, ColumnSortArraySmall, ref codeNode.ifCase); } if (KeyLongArrayBigLength == 0) { codeNode.elseCase = null; } else { codeNode.elseCase = new Node(); } if (KeyLongArrayBigLength == 1) { codeNode.elseCase.nodeType = NodeType.SetIndex; codeNode.elseCase.arrayIndex = ColumnSortArray[BestColumnCompareDataIndex][columnCompareData[BestColumnCompareDataIndex].midIndex]; codeNode.elseCase.charIndex = codeNode.charIndex; } else { Init(FullKeyLongArray, KeyLongArrayBig,columnLength, ColumnSortArrayBig, ref codeNode.elseCase); } } } public static long GetKeyLong(long[][] KeyLongArray, int RowIndex, int ColumnIndex) { if (ColumnIndex < KeyLongArray[RowIndex].Length) { return KeyLongArray[RowIndex][ColumnIndex]; } else { return 0; } } }
其运行效率如下:
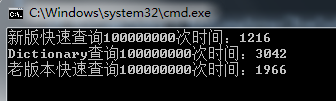
查询效率基本是传统字典的2倍以上。而且数量越多。字符串越长,其查询效率越高。