2019独角兽企业重金招聘Python工程师标准>>> 
Abstract
摘要
High level of noise reduces the perceptual quality and intelligibility of speech. Therefore, enhancing the captured speech signal is important in everyday applications such as telephony and teleconferencing. Microphone arrays are typically placed at a distance from a speaker and require processing to enhance the captured signal. Beamforming provides directional gain towards the source of interest and attenuation of interference. It is
often followed by a single channel post-filter to further enhance the signal. Non-linear spatial post-filters are capable of providing high noise suppression but can produce unwanted musical noise that lowers the perceptual quality of the output. This work proposes an artificial neural network (ANN) to learn the structure of naturally occurring post-filters to enhance speech
from interfering noise. The ANN uses phase-based features obtained from a multichannel array as an input. Simulations are used to train the ANN in a supervised manner. The performance
is measured with objective scores from speech recorded in an office environment. The post-filters predicted by the ANN are found to improve the perceptual quality over delay-and-sum
beamforming while maintaining high suppression of noise characteristic to spatial post-filters.
高水平的噪声降低了感知质量和可懂度语音。因此,加强抓获的讲话信号在日常应用中是很重要的,如电话与电话会议。麦克风阵列通常放置在一个扬声器的距离,需要处理,以提高捕获信号。波束形成提供了方向性增益感兴趣的来源和干扰的衰减。它是往往其次是一个单通道后过滤器,以进一步提高信号。非线性空间后滤波器能够提供高噪音抑制,但可以产生不必要的音乐降低输出的感知质量的噪声。这工作提出了一种人工神经网络(人工神经网络)学习自然发生的后置滤波器以增强语音的结构干扰噪声。人工神经网络使用相为基础的功能从一个多通道阵列获得一个输入。模拟用于训练神经网络的监督方式。性能测量与客观分数从语音记录在办公环境中。人工神经网络预测的后过滤器被发现,以提高感知质量的延迟和总和保持高抑制噪声特性的波束形成空间后过滤器。
Index Terms:Speech enhancement, Microphone arrays, Array signal processing, Artificial neural networks, Psychoacoustics.
关键词:语音增强,麦克风阵列,阵列信号处理,人工神经网络,心理声学
1. Introduction
介绍
Speech enhancement is used to improve the observed quality and it is important in many everyday applications such as telephony and distant talking interfaces. When the talker is distant from the capturing microphone, reverberation and background noise often reduce the captured quality significantly. Speech enhancement can remove noise (denoising), reverberation (dereverberation), or both. When multiple speakers are talking concurrently the problem of removing the interfering speakers is called speech separation.
语音增强是用来改善所观察到的质量它是重要的,在许多日常应用,如电话和遥远的谈话接口。当说话的人是遥远的从捕获麦克风、混响和背景噪音往往会显着降低捕获的质量。演讲增强可去除噪声(去噪),混响(混响),或两者。当多个演讲者在讲话同时消除干扰扬声器的问题被称为语音分离。
Time-frequency (T-F) masking is based on the windowingdisjoint orthogonality assumption of signals, i.e. speech energy is concentrated only to few time-frequency points, which do not
overlap between speakers [1]. A T-F mask typically approximates the ideal binary mask (IBM) and is applied by multiplying the observed mixture, thus passing only the desired components. However, musical noise artifacts can arise due to errors in mask estimation. Recently, the real-valued idealWiener filter (IWF) has been shown to improve speech intelligibility in noisy conditions over IBM [2].
时间频率(TF)掩蔽是基于windowingd是关节信号的正交性假设,即语音能量只集中到少数的时间-频率点,这不扬声器之间的重叠[ 1 ]。一个以面具通常接近理想的二进制掩码(IBM)和应用乘以所观察到的混合物,从而只通过所需的组件。然而,音乐噪音的文物可能会出现由于误掩模估计。最近,实值idealwiener滤波器(IWF)已被证明是提高语音清晰度在IBM的[ 2 ]
条件。
Machine learning techniques are popular in speech enhancement. In [3] a non-negative matrix factorization (NMF) technique is used to learn spectral basis of speech and different
noise types. The NMF reconstruction is then used to denoise the observation. The authors of [4] train a long short-term memory (LSTM) recurrent neural network (RNN) to predict a T-F mask for speech enhancement. In [5] spectral features (such as Melfrequency cepstral coefficients) and their delta components are used to train a deep neural network (DNN) to predict the instantaneous SNR for each frequency band, which is used to estimate
the ideal ratio mask IRM. The authors of [6] use a combination of DNNs and support vector machines (SVMs) for speech enhancement by binary classification of T-F bands. In [7], deep
recurrent autoencoder neural network is trained to denoise input features for noise robust automatic speech recognition (ASR).
机器学习技术在语音增强中很受欢迎。在[ 3 ]一个非负矩阵分解(NMF)技术是用来学习的语音和不同的噪声类型的光谱基础。NMF重建进行去噪观察。[ 4 ]培养一个长的短期记忆的作者
(LSTM)递归神经网络(RNN)预测时的面具语音增强。在[ 5 ]的光谱特征(如采用倒谱系数)和三角洲组件用于训练深层神经网络(DNN)预测瞬时每个频带的信噪比,这是用来估计
理想比面具IRM。[ 6 ]使用组合的作者的DNNs和支持向量机(SVM)的语音增强通过时频带的分类。在[ 7 ],深复发性自编码神经网络进行训练,去噪的输入噪音强大的自动语音识别的特点。
While the above methods primarily utilize a monophonic signal, binaural signals enable the use of spatial cues, i.e., interaural time delay (ITD) and interaural level difference (ILD).
The degenerate unmixing estimation technique (DUET) clusters each TF point based on its cue values [8]. In [9] this is done by supervised learning via kernel-density estimation for a binary T-F mask value. In [10] the spatial cues (along with pitch features for voiced frames) are used to train two sets of multilayer perceptrons (MLPs) for each combination of azimuth angle and frequency band. This approach requires a lot of training data and computations.
虽然上述的方法主要是利用单声道信号,双耳信号使空间线索,即使用双耳时间延迟(ITD)和双耳强度差(ILD)。退化分解估计技术(合唱)集群基于它的提示值的每个转移点[ 8 ]。在[ 9 ]这是通过二元核密度估计的监督学习TF的掩码值。在[ 10 ]的空间线索(随着间距的功能
对于有声的帧)被用来训练两组多层感知器(MLP)为每个组合和方位角频带。这种方法需要大量的训练数据和计算。
Beamforming is linear filtering applied to microphone array signals in order to amplify the desired direction(s) and/or attenuate unwanted one(s). The most simple fixed weight beamformer is the delay-and-sum beamformer (DSB) that sums the temporally aligned input signals from the desired direction of arrival (DOA). In contrast, adaptive methods update the filter coefficients based on estimates of the noise and signal statistics. The beamforming output can be further enhanced by multiplying with a post-filter, i.e. a type of T-F mask. An adaptive beamformer known as minimum variance distortionless response
(MVDR) combined with the single channel Wiener filter has been shown to be an optimal approach in the minimum mean square error (MMSE) sense [11, Ch.3]. The ability to increase
the SNR of the beamformer output has been successfully shown with different post-filters [12, 11, 13, 14], which differ in the assumptions made of the signal and noise.
波束形成是一线性滤波应用于麦克风阵列信号,以扩大所需的方向(S)和/或衰减不需要的一个(s)。最简单的固定重量的波束形成器是延迟和波束形成器(DSB)总结从所需的方向上的时间对准的输入信号到达(DOA)。与之相反,自适应方法更新过滤器基于噪声和信号统计估计的系数。可以进一步提高波束形成的波束形成输出用后过滤,即一种时频掩模。一种自适应
被称为最小方差无失真响应波束形成器(MVDR)结合单通道维纳滤波器已被证明是一个最佳的方法在最小均方误差(MMSE)的意义[ 11 ],第3章。增加的能力波束形成器的输出信噪比已成功显示不同的后过滤器[ 12,11,13,14 ],其中不同在由信号和噪声的假设中。
A spatial post-filter can suppress also point-wise noise sources. Tashev et al. derived the instantaneous DOA (IDOA) filter in [15], in which phase-difference measurements form a
likelihood function for post-filter estimation. Selzer et al. [16] proposed a statistical generative model to estimate speech and noise parameters as Gaussian random variables with application to post-filtering using phase-difference and spectral observations for a four microphone linear array. As in [10] the phase based features are dependent on the angle of the source. While spatial filtering has impressive suppression of noise as evident
in [15] it can also produce unwanted artifacts that lead to lower perceptual quality than that of the simple DSB. Therefore, it is important to investigate noise suppression capability of spatial
filtering in conjunction with perceptual quality. Selzer et al. [17] proposed a log-MMSE adaptive beamformer that uses the spatially post-filtered signal as the desired signal to produce higher perceptual quality over DSB.
空间滤波后可以抑制也逐点噪声 来源。tashev等人。导出了瞬时DOA(观念) 过滤器[ 15 ],其中相位差测量形式后滤波估计的似然函数。Selzer等人。[ 16 ] 提出统计生成模型估计的语音和 噪声参数的高斯随机变量的应用 后用一四传声器线性阵列的相位差和光谱观测 过滤。在[ 10 ]相 为基础的功能是依赖于源的角度。而 空间滤波对噪声有令人印象深刻的抑制明显在[ 15 ],它也可以产生不必要的文物,导致较低的 感知质量比简单的DSB。因此,它是研究空间的噪声抑制能力 重要结合感知质量的过滤。Selzer等人。[ 17 ] 提出日志MMSE自适应波束形成器的使用空间 过滤后的信号所需的信号在 DSB产生更高的感知质量。
This work proposes the use of a multilayer perceptron (MLP), a type of artificial neural network, to learn the mapping from phase-based features directly into post-filter values
using a circular microphone array. In contrast to angle dependent models [16, 10] the input feature is angle independent and a single MLP can be used to predict the post-filter. This reduces the model complexity over previous methods. In contrast to previous binaural approaches that utilize the IBM as the target, the MLP here predicts the IWF, i.e., a real-valued postfilter. Finally, in contrast to traditional post-filters, the MLP does not require explicit assumptions or estimates of the signal and noise statistics. Instead, data generated by simulations is used to train the MLP, while the performance is evaluated with recorded speech. The proposed MLP based post-filter operates in the MEL-frequency domain.
这项工作提出了使用的多层感知器(MLP),一种人工神经网络,学习的映射从相为基础的功能,直接进入后过滤值使用圆形麦克风阵列。相反角度依赖性模型[ 16,10 ]的输入功能是角度独立和一个单一的MLP可以用来预测滤波器。这减少了模型的复杂性比以前的方法。在对比
以前的双耳的方法,利用IBM的目标,这里的MLP预测IWF,即实值后置滤波器。最后,在对比传统的后置滤波器,MLP不需要明确的假设或估计的信号和噪声统计。相反,模拟所产生的数据是用于训练MLP,而评估与性能录制的语音。所提出的基于MLP-后过滤操作在频率域。
This paper is organized as follows. Section 2 reviews beamforming and DOA estimation. The conventional spatial postfilter is reviewed in Section 3. The proposed MLP based spatial
post-filter is presented in Section 4. Section 5 describes the array speech recordings. Section 6 reports and discusses the results and is followed by the conclusions Section 7.
本文组织如下。第2节评论波束形成和DOA估计。传统空间后置滤波器在第3节检讨。所提出的基于多层空间后过滤器是在第4节。第5节介绍阵列语音记录。第6节报告和讨论结果和随后的结论部分7。
2. Beamforming and DOA Estimation
2波束形成和DOA估计

第i个麦克风接收信号xi(t),i=1,……,M
![]()

式中Hi(t,w)是麦克风到声源的传递函数,w是角频率,t分帧时间。
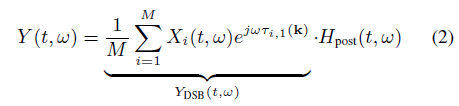
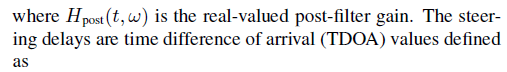
式中Hpost(t,w)是post滤波器的实数值。
![]()

式中mi->R是第i个麦克风的位置,以及K是
![]()

式中c是声速,
2.1. DOA estimation
2.1波达方向估计
The generalized cross-correlation (GCC) is applied to estimate the source DOA k in frame t with the steered response power (SRP) method [18]
广义互相关(GCC)应用于估计在与转向响应帧的源DOA K(SRP)方法[ 18 ]
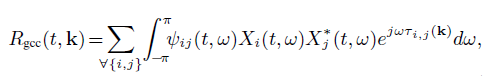

式中,path权重清除了幅度信息。
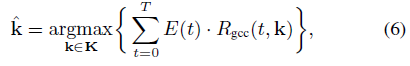

式中E(t)是
3. Conventional Spatial Post-Filter
3. 传统空间的后置滤波器
Following the azimuth angle IDOA filter definition of [15] and omitting the time index for brevity the expression of IDOA for a DOA vector k is
以下的方位观念滤波器定义[ 15 ],省略简洁观念表达的时间指数DOA矢量k
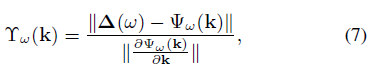
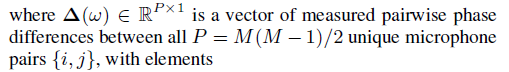
![]()

式中
![]()
![]()
The probability density for frequency ! to come from desired direction k is [15]
频率的概率密度来自所需方向k为[ 15 ]
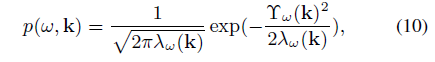
![]()
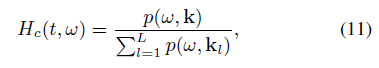
where kl denotes l = 1, . . . , L different steering directions. DSPF allows steep noise suppression but entails artifacts. Note that [15] proposes the additional use of a HMM framework.
在KL表示L = 1,。..,L不同方向。DSPF允许陡峭的噪声抑制但需要文物。注该[ 15 ]提出了一个隐马尔可夫模型框架的附加使用。
4. Neural Network Based Post-Filter
4 基于神经网络的后置滤波器
A block diagram of beamforming with spatial post-filtering is presented in Fig. 1. The post-filter values are obtained in the MEL frequency domain. A widely applied conversion from linear frequency fHz (in Hz) to MEL frequency is
空域滤波后的波束形成框图如图1所示。后过滤器的值在Mel频率域。一种广泛应用的线性变换
频率FHZ(Hz)Mel频率
![]()
The use of MEL-frequency scale is motivated by the psychoacoustic properties of the human hearing system i.e. closely spaced frequencies mask each other. Furthermore, the computational complexity of post-filter gain for B frequency bands instead of NDFT frequency bins can lead to large computational savings, since typically B《NDFT.
Mel频率尺度使用动机的心理声学人类听觉系统的性质即密切间隔频率掩模。此外,计算
用于B频段的后置滤波器增益的复杂性而测量频点可以导致大的计算储蓄,因为通常B NDFT美元。

Figure 1: A block diagram of the proposed post-filter approach. The phase-differences are first extracted between microphone pairs, then subtracted from theoretical delays, and converted into input features ut(b|k) for frequency bands b = 1, . . . ,B. Similarly, averaged features over other directions are extracted as vt(b). Using these values, theMLP predicts the post-filter values for each frequency band. The frequency band values are then converted to linear scale HMLP(t, !). Finally, post-filter values are applied to the beamformer output YDSB(t, !).
图1:提出的后置滤波方法的方框图。第一次提取的麦克风之间的相位差对,然后从理论延迟中减去,并转换为输入特征UT(B | K)频段,B = 1,。..,B.同样,其他方向上的平均特征提取
作为VT(B)。使用这些值,themlp预测滤波器每个频带的值。的频带的值是然后转换为线性刻度HMLP(t,!)最后,后置滤波器值应用到波束形成器的输出ydsb(t,!)。
4.1. MLP Structure
4.1MLP结构
4.2. Training Data
4.2训练数据
An eight microphone circular array with 10 cm radius was used to simulate audio with 16 kHz sampling rate with added noise and reverberation. Two different sized rooms with reverberation times (T60) 0.4 s and 0.9 s with two source distances of 1.2 m
and 2.4 m were used to generate room impulse responses (RIR) for each microphone using the image method [20]. For each room and distance combination 100 randomly selected TIMIT database speech sentences were convolved with the RIRs to simulate the reverberant array signals. In each repetition, the array was placed in the center of the room, and the source angle was drawn randomly between surrounding azimuth angles
[0&, 360&]. Independent and identically distributedwhiteGaussian noise was added to the microphone signals, and the resulting SNR was drawn from a uniform distribution between
[+12, +40] dB. The purpose of adding noise is to provide diverse training samples for the neural network in order to be generic enough to be applied in different conditions.
一个八麦克风的圆形阵列与10厘米半径的使用用16千赫采样率模拟音频与附加噪声和混响。两个不同大小的房间混响倍(T60)0.4年代和0.9年代与1.2米两源的距离2.4米被用来生成房间脉冲响应(RIR)对于每个麦克风使用的图像法[ 20 ]。对于每个空间和距离组合100个随机选择的TIMIT数据库的语音句子卷积RIR来模拟混响信号阵列。在每一个重复中数组被放置在房间的中心,和源角随机在周围的方位角之间的随机[ 0,360 ]。独立同distributedwhitegaussian
噪声被添加到麦克风信号,和所得到的信噪比是从一个统一的分布之间[ 12,+ 40 ]分贝。增加噪音的目的是提供多样化的为了成为神经网络的训练样本通用性,可以应用在不同的条件。
A 32 ms window with 75 % overlap was used to extract the features (15) from all 400 simulated recordings. The target values were obtained from the ideal Wiener filter (IWF) [21]
一个32毫秒的窗口有75%个重叠被用来提取从所有400个模拟录音的功能(15)。目标
从理想的维纳滤波值(IWF)[ 21 ]


1The Deep Learn Toolbox implementation of MLP was used, http://github.com/rasmusbergpalm/DeepLearnToolbox.
5. Description of Recordings
5 关于录音
An small office was used to capture speech recordings with an 8 channel microphone array with 10 cm radius and a reference microphone mounted on a stand at 1.5 m height. The array was elevated on a stand at 1.0 m height, and consisted of omnidirectional electret condenser microphones (Sennheiser MKE 2). The reference microphone was a cardioid pattern Røde NT 55 condenser microphone. The recordings consist of phonetically balanced sentences [22] captured at 1.3 m (near) and 2.0 m (far) distance from the array center with 48 kHz sampling rate. Two PCs were emitting fan noise at approximately 1 m and 1.5 m
distances from the array, in different angles than the speaker. A total of 77 recordings were captured from four different male speakers (38 far, 39 near), with an average sentence length of 3.8 s.
一个小的办公室被用来捕获语音记录10声道麦克风阵列,用8厘米半径和参考安装在一个支架上的麦克风在1.5米的高度。阵列高架上的一个站在1米的高度,包括全方位驻极体电容式麦克风(森海塞尔经济部2)。参考麦克风是一个心形图案Røde NT 55电容式麦克风。录音包括语音平衡的句子[ 22 ]在1.3米(近)和2米(远)与48千赫采样率的阵列中心的距离。二个人电脑在约1米和1.5米的发射风扇噪声从阵列的距离,在不同的角度比扬声器。一共有77录音被抓获,从四个不同的男性扬声器(38远,39个),平均句子长度3.8秒。
6. Results and Discussion
6。结果与讨论
7. Conclusions
This paper proposes using an artificial neural network (ANN) in the design of spatial post-filtering for beamforming. More specifically, the multilayer perceptron (MLP) is applied. Spatial
cues from noisy and reverberant speech are used to train a MLP to predict post-filter values corresponding to the ideal Wiener Filter (IWF). The post-filter is obtained in the MEL-frequency scale and is converted to linear frequency scale before being applied to delay-and-sum beamforming (DSB). The method was evaluated with microphone array recordings of speech sentences in an office at two different distances. Objective measurements
of intelligibility (STOI) show that the MLP based post-filter provides increase in perceptual quality over DSB, while the segmental SNR and frequency-weighted segmental SNR indicate significant noise suppression over DSB.
7。结论
本文提出了使用人工神经网络(人工神经网络)波束形成的空间滤波后滤波设计。更多
具体而言,多层感知器(MLP)的应用。空间从噪声和混响的语音提示是用于训练MLP
预测相应的理想维纳滤波后的值滤波器(IWF)。后的过滤器是在Mel频率得到尺度,并转换成线性频率尺度应用延迟求和波束形成(DSB)。的方法用麦克风阵列录音的语音句子进行评估
在两个不同的距离的办公室里。目的测量可理解性(化学)表明,MLP的基础后置滤波器提供了感知质量对DSB增加,而分段信噪比和频率加权段信噪比有显著的噪声抑制DSB。