java日历算法分析_Java基础算法分析之一

Java进步点点滴滴
Java基础算法分析之一
基础概念与二分查找法
程序猿出品
导语
Java是世界上最流行、应用最广泛的编程语言,没有之一。作为Java程序员,享受相对高薪和光鲜体面的生活同时,也时时面对一个严重的问题,就是Java开发方面的知识技能太多,更新得也太快,使得程序员必须不停地更新知识技能,才能不被就业市场淘汰,维持较长的职业生命。在这里,我们提供一些比较基础一些的技能知识,希望能帮助到新入行的朋友,谢谢大家。
1算法的简单定义与要求
有这样一个著名公式:算法+数据结构=程序。足以见证算法的重要性,否则你就根本没法写程序。简单说来就是我们用来解决问题的方法。 算法:算法是规则的有限集合,为解决特定问题而规定的一系列操作。
算法的特性:
有穷性:有限步骤内正常结束,不能无限循环。
确定性:每个步骤都必须有确定的含义,无歧义。
可行性:原则上能精确进行,操作能通过有限次完成。
输入:有0或多个输入。
输出:至少有一个输出。
设计算法的要求:
算法的正确性:对于一切的合法输入都能产生正确的满足要求的结果。
可读性:一个好的算法应该便于人们理解和相互交流。
健壮性:即使用户输入了非法数据,算法也应该识别并做出处理。
高效率和低存储量:即运行速度最快,需要的存储空间最少。

2时间复杂度与空间复杂度
判断一个算法优劣,我们通常从时间复杂度与空间复杂度,这两个维度来精选分析。
时间复杂度
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n),在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
有时候,算法中基本操作重复执行的次数还随问题的输入数据集不同而不同,如在冒泡排序中,输入数据有序而无序,其结果是不一样的。此时,我们计算平均值。
这样用大写O来体现时间复杂度的的记法,我们称为大O表示法。
一般情况下,随着n的增大,T(n)增长最慢的算法我们称之为最优算法。
比如说我们有三个求和算法,按顺序时间复杂度为O(n),O(1),O(n^2),分别称为线性阶,常数阶和平方阶。
O(1)常数阶:每条语句的频度都是1,算法的执行时间不随着问题规模n增大而增长,即使有上千条语句,其执行时间也不过是一个比较大的常数。
O(n)线性阶:有一个n次循环的循环语句。随着n增长执行时间线性增长。
O(n^2)平方阶:随着数据增长,运行时间呈指数增长,例如循环中嵌套一个循环的情况。
空间复杂度
空间复杂度:算法所需存储空间的度量,记作:S(n)=O( f(n) ),其中 n 为问题的规模。
一个算法在计算机存储器上所占用的存储空间,包括存储算法本身所占用的存储空间,算法的输入输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间这三个方面。如果额外空间相对于输入数据量来说是个常数,则称此算法是原地工作。
算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随本算法的不同而改变。存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。

3经典算法之二分查找法
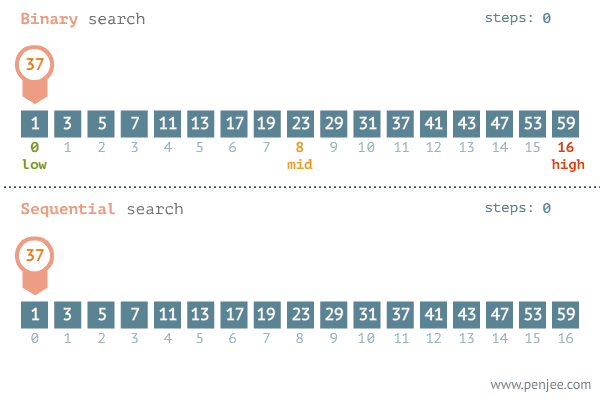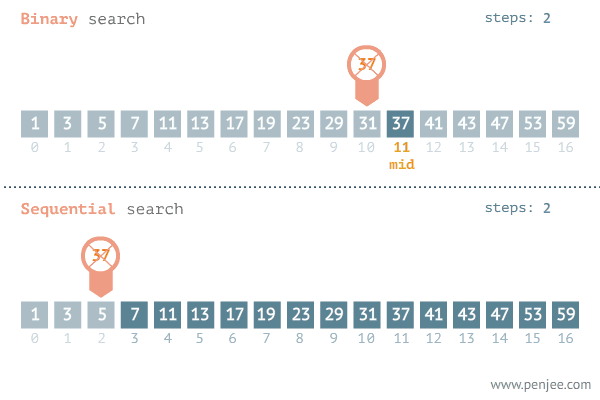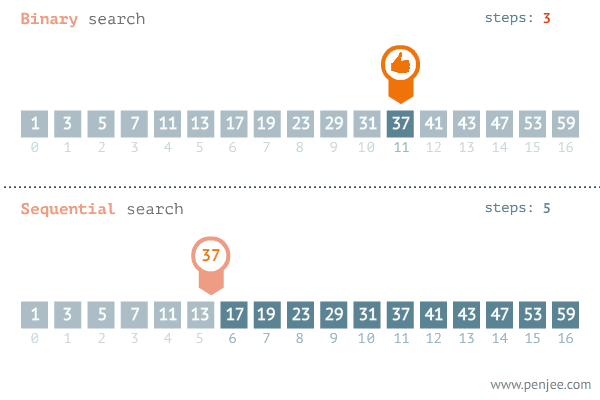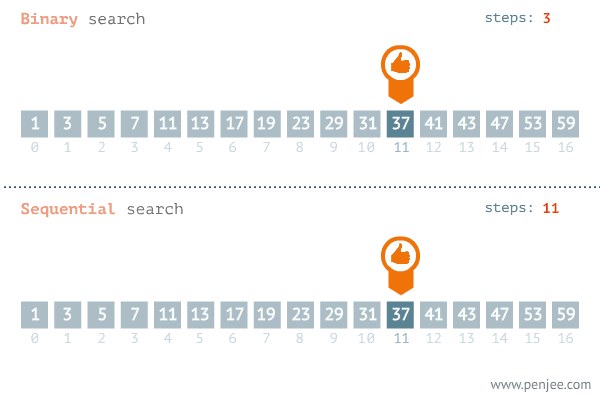
二分查找(binary search),也称折半搜索,是一种在 有序数组 中 查找某一特定元素 的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
时间复杂度:折半搜索每次把搜索区域减少一半,时间复杂度为O(log n)。(n代表集合中元素的个数)
空间复杂度::O(1)。虽以递归形式定义,但也可改写为循环。
递归算法实现:
int binarysearch(int array[], int low, int high, int target) { if (low > high) return -1; int mid = low + (high - low) / 2; if (array[mid] > target) return binarysearch(array, low, mid - 1, target); if (array[mid] < target) return binarysearch(array, mid + 1, high, target); return mid; } |
循环算法实现:
int bsearchWithoutRecursion(int a[], int key) { int low = 0; int high = a.length - 1; while (low <= high) { int mid = low + (high - low) / 2; if (a[mid] > key) high = mid - 1; else if (a[mid] < key) low = mid + 1; else return mid; } return -1; } |
算法分析:
二分查找法的O(log n)让它成为十分高效的算法。不过它的缺陷却也是那么明显的。就在它的限定之上:必须有序,我们很难保证我们的数组都是有序的。当然可以在构建数组的时候进行排序,可是又落到了第二个瓶颈上:它必须是数组。
数组读取效率是O(1),可是它的插入和删除某个元素的效率却是O(n)。因而导致构建有序数组变成低效的事情。
解决这些缺陷问题更好的方法应该是使用二叉查找树了,最好自然是自平衡二叉查找树了,既能高效的(O(n log n))构建有序元素集合,又能如同二分查找法一样快速(O(log n))的搜寻目标数。

以上是 Java经典算法之二分查找法 的介绍与分析。各位朋友,我们下期再见。