Druid入门
应用场景
设计一个系统来预估未来一年的广告流量,不是总流量,是任意时间段任何定向(Targeting)条件约束情况下的流量。定向条件有近百种(内容类别,设备平台,用户地域,用户人口属性等),整个时间区间不同组合数(也就是数据行数)是亿级别。目标是秒级的查询响应时间。

存储系统选择
MySQL不是适合的选择
最容易想到的是用Mysql作为数据存放和查询引擎,由于数据行数太多,Mysql必须通过创建索引或者组合索引来加速查询。
典型的查询包含若干个定向类别,这些定向条件的组合是非常多的(top 80%的查询也会包含几十种组合),故需要创建非常多的组合索引,代价很高。
另外,对于那些没有创建组合索引的查询,查询时间完全不能接受。
为什么没有用Hbase或者Hive
Hbase本身是一个经典的基于hdfs的分布式存储系统,通常来说其是行存储的,当创建column families之后,每个column family是列存储的。在这个应用中,可以为每个定向类别(包括日期)创建一个单独的column family,但Hbase本身没有为column family创建bitmap indexing,查询速度应该会受到影响。
另外不用Hbase的一个原因是希望存储系统尽量轻量级,最好不要安装hadoop
Hive将查询转化为M/R任务,没法保证查询的快速响应(比如M/R cluster资源竞争很激烈时),而且使用Hive需要以来hadoop cluster,对这个应用来说也略微重量级。
我们需要一个高可用的分布式的列存储系统
核心需求包含2点,一是查询速度快,二是系统的拓展性好,最好是分布式的。
- 第一点要求意味着最好用column-store而不是row-store,在这个应用中,虽然定向类别有近百种,但是单次查询通常只会涉及几个。对于修改操作较少且查询往往只涉及少数几列的场景使用column-store可以获得快一个量级的查询速度。而且column-store可以通过bitmap indexing,encoding,以及compression来优化查询速度和存储开销
- 第二点要求一方面是由于我们的数据量较大,并行存储和查询可以减少时间开销,另一方面是数据量每年还在快速上涨,以后可以简单地通过加机器来应对。
对系统的其他要求比较普遍:系统可用性要高,稳定,轻量级,易于上手。
为什么Druid是适合的选择
Druid满足我们上面2点要求,其是一个开源的、分布式的、列存储系统,特别适用于大数据上的(准)实时分析统计。且具有较好的稳定性(Highly Available)。 其相对比较轻量级,文档非常完善,也比较容易上手。
Druid介绍
概念
Segment: Druid中有个重要的数据单位叫segment,其是Druid通过bitmap indexing从raw data生成的(batch or realtime)。
segment保证了查询的速度。可以自己设置每个segment对应的数据粒度,这个应用中广告流量查询的最小粒度是天,所以每天的数据会被创建成一个segment。注意segment是不可修改的,如果需要修改,只能够修改raw data,重新创建segment了
架构
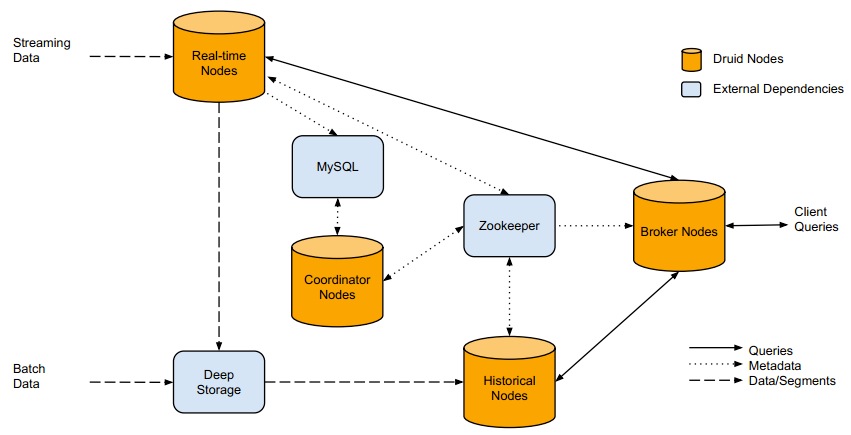
Druid本身包含5个组成部分:Broker nodes, Historical nodes, Realtime nodes, Coordinator Nodes和indexing services. 分别的作用如下:
- Broker nodes: 负责响应外部的查询请求,通过查询Zookeeper将请求划分成segments分别转发给Historical和Real-time nodes,最终合并并返回查询结果给外部;
- Historial nodes: 负责’Historical’ segments的存储和查询。其会从deep storage中load segments,并响应Broder nodes的请求。Historical nodes通常会在本机同步deep storage上的部分segments,所以即使deep storage不可访问了,Historical nodes还是能serve其同步的segments的查询;
- Real-time nodes: 用于存储和查询热数据,会定期地将数据build成segments移到Historical nodes。一般会使用外部依赖kafka来提高realtime data ingestion的可用性。如果不需要实时ingest数据到cluter中,可以舍弃Real-time nodes,只定时地batch ingestion数据到deep storage;
- Coordinator nodes: 可以认为是Druid中的master,其通过Zookeeper管理Historical和Real-time nodes,且通过Mysql中的metadata管理Segments
- Druid中通常还会起一些indexing services用于数据导入,batch data和streaming data都可以通过给indexing services发请求来导入数据。
Druid还包含3个外部依赖
- Mysql:存储Druid中的各种metadata(里面的数据都是Druid自身创建和插入的),包含3张表:”druid_config”(通常是空的), “druid_rules”(coordinator nodes使用的一些规则信息,比如哪个segment从哪个node去load)和“druid_segments”(存储每个segment的metadata信息);
- Deep storage: 存储segments,Druid目前已经支持本地磁盘,NFS挂载磁盘,HDFS,S3等。Deep Storage的数据有2个来源,一个是batch Ingestion, 另一个是real-time nodes;
- ZooKeeper: 被Druid用于管理当前cluster的状态,比如记录哪些segments从Real-time nodes移到了Historical nodes;
查询
Druid的查询是通过给Broker Nodes发送HTTP POST请求(也可以直接给Historical or Realtime Node),具体可见Druid官方文档。查询条件的描述是json文件,查询的response也是json格式。Druid的查询包含如下4种:
- Time Boundary Queries: 用于查询全部数据的时间跨度
- groupBy Queries: 是Druid的最典型查询方式,非常类似于Mysql的groupBy查询。query body中几个元素可以这么理解:
- “aggregation”: 对应mysql”select XX from”部分,即你想查哪些列的聚合结果;
- “dimensions”: 对应mysql”group by XX”,即你想基于哪些列做聚合;
- “filter”: 对应mysql”where XX”条件,即过滤条件;
- “granularity”: 数据聚合的粒度;
- Timeseries queries: 其统计满足filter条件的”rows”上某几列的聚合结果,相比”groupBy Queries”不指定基于哪几列进行聚合,效率更高;
- TopN queries: 用于查询某一列上按照某种metric排序的最常见的N个values;
本文小结
- Druid是一个开源的,分布式的,列存储的,适用于实时数据分析的系统,文档详细,易于上手;
- Druid在设计时充分考虑到了Highly Available,各种nodes挂掉都不会使得druid停止工作(但是状态会无法更新);
- Druid中的各个components之间耦合性低,如果不需要streaming data ingestion完全可以忽略realtime node;
- Druid的数据单位Segment是不可修改的,我们的做法是生成新的segments替换现有的;
- Druid使用Bitmap indexing加速column-store的查询速度,使用了一个叫做CONCISE的算法来对bitmap indexing进行压缩,使得生成的segments比原始文本文件小很多;
- 在我们的应用场景下(一共10几台机器,数据大概100列,行数是亿级别),平均查询时间<2秒,是同样机器数目的Mysql cluter的1/100 ~ 1/10;
- Druid的一些“局限”:
- Segment的不可修改性简化了Druid的实现,但是如果你有修改数据的需求,必须重新创建segment,而bitmap indexing的过程是比较耗时的;
- Druid能接受的数据的格式相对简单,比如不能处理嵌套结构的数据