为什么80%的码农都做不了架构师?>>> 
K最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,也是最简单易懂的机器学习算法。
该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别,则该样本也属于这个类别。
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
先准备下电影分类数据集(纯属虚构):
| 序 号 | 电影名称 | 搞笑镜头 | 拥抱镜头 | 打斗镜头 | 电影类型 |
| 1. | 宝贝当家 | 45 | 2 | 9 | 喜剧片 |
| 2. | 美人鱼 | 21 | 17 | 5 | 喜剧片 |
| 3. | 澳门风云3 | 54 | 9 | 11 | 喜剧片 |
| 4. | 功夫熊猫3 | 39 | 0 | 31 | 喜剧片 |
| 5. | 谍影重重 | 5 | 2 | 57 | 动作片 |
| 6. | 叶问3 | 3 | 2 | 65 | 动作片 |
| 7. | 伦敦陷落 | 2 | 3 | 55 | 动作片 |
| 8. | 我的特工爷爷 | 6 | 4 | 21 | 动作片 |
| 9. | 奔爱 | 7 | 46 | 4 | 爱情片 |
| 10. | 夜孔雀 | 9 | 39 | 8 | 爱情片 |
| 11. | 代理情人 | 9 | 38 | 2 | 爱情片 |
| 12. | 新步步惊心 | 8 | 34 | 17 | 爱情片 |
| 13. | 唐人街探案 | 23 | 3 | 17 | ? |
上面数据集中序号1-12为已知的电影分类,分为喜剧片、动作片、爱情片三个种类,使用的特征值分别为搞笑镜头、打斗镜头、拥抱镜头的数量。那么来了一部新电影《唐人街探案》,它属于上述3个电影分类中的哪个类型?
构建一个已分好类的数据集
对于一个规模巨大的数据集,显然数据库是更好的选择。这里为了方便验证,使用Python的字典dict构造数据集。
计算一个新样本与数据集中所有数据的距离
这里的新样本就是:"唐人街探案": [23, 3, 17, "?片"]。欧式距离是一个非常简单又最常用的距离计算方法。
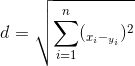
其中x,y为2个样本,n为维度,xi,yi为x,y第i个维度上的特征值。如x为:"唐人街探案": [23, 3, 17, "?片"],y为:"伦敦陷落": [2, 3, 55, "动作片"],则两者之间的距离为: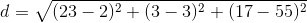 =43.42。
=43.42。
按照距离大小进行递增排序
方便选取最小距离集。
选取距离最小的k个样本,确定前k个样本所在类别出现的频率,并输出出现频率最高的类别
import math
# 构建一个已分好类的数据集
movie_data = {
"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]
}
# 待测数据
x = [23, 3, 17]
# 欧氏距离集合
KNN = []
for key, v in movie_data.items():
# 欧氏距离
d = math.sqrt((x[0] - v[0])**2 + (x[1] - v[1])**2 + (x[2] - v[2])**2)
KNN.append([key, round(d, 2)]) # 保留两位小数
# 按照距离大小进行递增排序。
KNN.sort(key=lambda dis: dis[1]) # (key=lambda dis: dis[1])表示按每个元素的第2个参数排序
# 选取距离最小的k个样本
KNN = KNN[: 5]
# 确定前k个样本所在类别出现的频率,并输出出现频率最高的类别。
labels = {"喜剧片": 0, "动作片": 0, "爱情片": 0} # 统计值初始化
for s in KNN:
label = movie_data[s[0]] # 遍历标签
labels[label[3]] += 1 # 标签对应的值增加
finalL = sorted(labels.items(), key=lambda l: l[1], reverse=True) # 使用内置排序,不改变源标签序列,降序
print(finalL, finalL[0][0], sep="\n")
"E:\Python 3.6.2\python.exe" F:/PycharmProjects/KNN.py
[('喜剧片', 4), ('动作片', 1), ('爱情片', 0)]
喜剧片
Process finished with exit code 0
KNN有几个特点:
(1)KNN属于惰性学习
这是与急切学习相对应的,因为KNN没有显式的学习过程!也就是说没有训练阶段,从上面的例子就可以看出,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。
(2)KNN的计算复杂度较高
我们从上面的例子可以看到,新样本需要与数据集中每个数据进行距离计算,计算复杂度和数据集中的数据数目n成正比,也就是说,KNN的时间复杂度为O(n),因此KNN一般适用于样本数较少的数据集。
(3)k取不同值时,分类结果可能会有显著不同。
上例中,如果k取值为k=1,那么分类就是动作片,而不是喜剧片。一般k的取值不超过20,上限是n的开方。
使用numpy写通用算法
from numpy import *
import operator
# 数据集与标签
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.1], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
# k-近邻算法
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # 获取数组行数
'''
计算距离
'''
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistance = sqDiffMat.sum(axis=1)
distance = sqDistance**0.5 # distance中保存的是inX到数据集中的欧氏距离
'''
排序与 K 值
'''
sortedDistIndicie = distance.argsort() # argsort函数返回的是数组值从小到大的索引值
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicie[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # get(key, default),获取指定键对应的值,如果值不存在则返回default
'''
通过iteritems函数,转化为可迭代的对象,提高性能,items()也可以。
operator模块提供的itemgetter()函数用于获取对象的哪些维的数据,参数为一些序号。
'''
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
group,labels = createDataSet()
print(classify([0, 0], group, labels, 3))
"E:\Python 3.6.2\python.exe" F:/PycharmProjects/knn2.py
B
Process finished with exit code 0