最近着手看word2vec的讲解,初始要点有sigmoid,逻辑回归,贝叶斯,到神经概率模型。到这里觉得应该先转到神经网络,之前细致看过hmm的讲解,一个输入层一个输出层,期间一些转换概率发射概率等,神经网络neruon network(nn)和hmm相差多一个隐藏层,以为他们之间有什么共性或者连接,结果看下来完全没关系。网络也毫无这两者之间的比较对比啥的。果然依然是只观其面还未近其身的阶段啊。回头再写一篇hmm 每个是一个点 不混淆不笼统的梳理一下。
从分类接触机器学习,之前做的给词语标记词性,划分停顿片段,以及词语分词(区分当前字在词语中的位置BEMS),NER(区分词语是否是各种实体)其实都是分类问题。
机器学习的主要流程就是训练(也称学习)和识别。训练的过程是准备大量数据样本,让机器自己学习根据输入(样本本身或者提取到的特征),和输出(已经标记好的分类结果),机器总结一套规则处理啊。识别(分类)就是对于新的一种样本输入,机器能根据已经学到的经验,判定出该新样本所属的类别。所以感觉展开又要好多好多了。
模型训练流程
1.数据处理-数据清洗方法
2.提取特征(有哪些方法?特征有效性评判)
3.训练模型的选择
4.模型训练过程-就是找一个近似模型,预测出的数值和实际数值差异最小,就是最佳模型,如何寻找这个最佳模型(将差异用误差率表示出来,然后找满足误差最小的模型-变为最优化求误差全局极小值的问题))
5.模型性能判定(有哪些参数表征模型性能?召回率识别率)
神经网络是什么
神经网络是分类器的一种,由于原理是模拟人脑识别物体的机制,人脑神经元的反应过程,所以这个名字。
-**神经元:神经元有输入,生物中称作激励,类似针尖扎一下,肌肉会收缩产生反应叫做输出。神经元是一个简单的分类器,而神经网络由大量多层的神经元组成,所以神经网络是个巨大的分类器。
如下一个神经元的结构,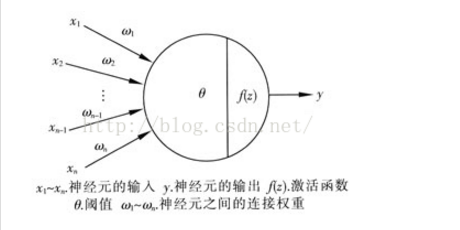
首先输入会有多条进入一个神经元,输出会在无穷范围,将输出做一个函数转换,加一个激活函数在此,可以有效的将输出框在一个范围,这样便于数据分析。每条输入产生的刺激强度不同,此处加一个权重,来表示输入和神经元之间的连接权重。输入(也就是激励),加一个阈值区分,超过这个阈值分为一类,这个阈值以下另一类。如此是一个神经元的构造和原理。
如下是另一个版本神经元结构。此处强调了 ,每个输入到神经元的连接之间,会有对权重做加权求和,再用阈值限定,在通过激发函数对输出做限定,最后是输出。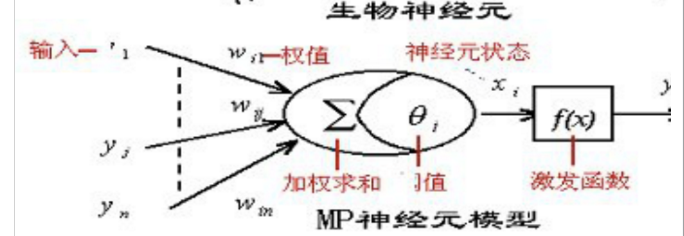
以上通俗提到的知识点有:激活函数, 后面有专业概念梳理
以上是一个神经元的构造,多个神经元就组成一个神经网络,如下图。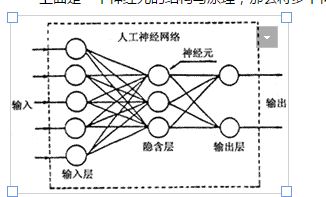
神经元包含一个输入层,一个输出层,以及可能多个隐藏层。输入层和输出层各有多个节点,这是固定的。隐藏层的节点可以调整。实验经验来谈,此处不列出。
神经网络的类型
- 前向性:简单的神经网络,对于线性可分的分类问题可以操作。调整参数的过程就是对每个路径设置权重,经过加权求和及激励函数得到最终输出,与真实结果比较,根据误差再调整输入层的权重,如此迭代反复直到预测结果与实际结果极其接近。理解为一个直线吧一堆向量分为两类,先随意划一刀,划分结果不靠谱再调整直线位置,再划一刀。如此直线跳来跳去。直到最佳位置。划分两类。
- 反馈型:对于非线性问题,可以用反馈型。不能根据最终误差简单地调整输入层的权重参数,而应该是每次调整,应该沿着误差的下降方向,也就是求误差的梯度方向。
此处知识点:梯度,以及梯度下降。后文详述。
神经网络训练方法
根据神经网络的类型,训练常用方法也分两类:前向训练和反向训练。此处介绍第二种,反向训练也叫BPNN(back_propagate neruon network)
1.数据准备和处理
数据收集来源很多。大数据时代缺的不是数据。数据收集后可以做清洗,正则化规整,甚至转换(NLP中汉字计算词向量,转换为数字),数值归一化。
归一化可以归一到[0,1]区间或者[-1,1]区间。
两个常用归一化公式:y = ( x - min )/( max - min ) (归一到(0,1)区间y = 2 * ( x - min ) / ( max - min ) - 1 (归一到(-1,1)区间
2.初始化神经网络参数
3.调用一次预测,根据预测结果层层反馈误差往前一层,反馈为误差*权重到上一层
训练过程如下图可示,后面是代码详解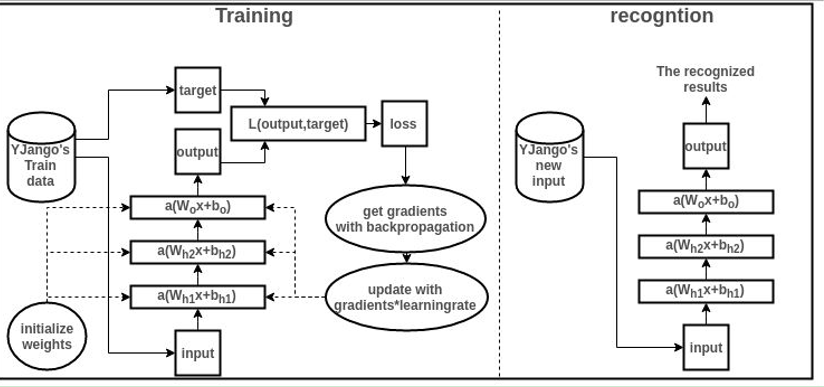
BPNN-python代码
import math
import random
random.seed(0)
def rand(a,b):
return (b-a)*random.random() +a
def make_matrix(m,n,fill = 0.0):
mat = []
for i in range(m):
mat.append([fill]*n)
return mat
def sigmoid(x):
return 1.0/(1.0+math.exp(-x)
def sigmoid_derivate(x):
return x*(1-x)
//BPNN的元素:
//1.三层,输入层,隐含层,输出层,每个层包含多个神经元。用三个列表保存着三层,列表中的元素代笔一个神经元。
//2.连接权值:输入层与隐含层,隐含层与输出层之间的连接权重,用两个二维列表存储
//一 初始化网络
def setup(self,ni,nh,no): ##input hidden output
##初始化三层的元素个数,以下定义隐藏层几个节点,输入层是样本个数还是特征个数?隐含层的节点个数如何定义的?输出节点个数就是分几类:四种类型就是4,两种类型就是2
self.input_n = ni+1
self.hidden_n = nh
self.output_n = no
##init cells 初始化三个神经元
self.input_cells = [1.0] * self.input_n
self.hidden_cells = [1.0] * self.hidden_n
self.output_cells = [1.0] * self.output_n
#init weight 初始化权重 此处初始化为0,两层之间每个节点两两之间都有个权重,w12,w13,w23如此,所以是二维的
self.input_weights = make_matrix(self.input_n,self.hidden_n)
self.output_weights = make_matrix(self.hidden_n, self.output_n)
#然后随机给个权重值
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2,0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = rand(-2.0, 2.0)
#初始化矩阵,横轴是输入节点数,竖轴是隐含层节点数
self.input_correction = make_matrix(self.input_n, self.hidden_n)
self.output_correction = make_matrix(self.hidden_n, self.output_n)
#预测方法 predict,输出为预测值
def predict(self,inputs):
# activate input layer 输入层做一次转化,n个样本,是【0,n-1】
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
#计算隐含层的输出,是每个节点和隐藏层节点之间的加权和,然后做一次激活函数的限制输出 到下一层
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total = 0.0
total += self.input_cells[i] * self.input_weights[i][j] ##此处为何是先i再j,以隐含层节点做大循环,输入样本为小循环,是为了每一个隐藏节点计算一个输出值,传输到下一层
self.hidden_cells[j] = sigmoid(total) #此节点的输出是前一层所有输入点和到该点之间的权值加权和
# activate output layer 输出层同理 此处是三层神经网络
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
return self.output_cells[:] #最后输出层的结果返回
#反向传播方法,调用一次预测,根据结果反向传播层层往前,再权重,再前向预测,最终返回结果,并和实际结果比较返回误差
def back_propagate(self,case,label,learn,correct):
#对输入的样本做预测
self.predict(case)
# get output layer error
output_deltas = [0.0] * self.output_n
for o in range(self.output_n):
error = label[o] - self.output_cells[o] #误差:正确结果与预测结果的差值
output_deltas[o] = sigmod_derivate(self.output_cells[o]) * error #将输出结果限定在sigmoid函数范围内,并求导,然后乘以误差,这是损失函数吗?
# get hidden layer error 得到隐含层的误差
hidden_deltas = [0.0] * self.hidden_n
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o] #误差也是累计,往前反馈,后一层的折扣限定输出,乘以两层之间的权重,累加作为多个输出样本累计的误差
hidden_deltas[h] = sigmod_derivate(self.hidden_cells[h]) * error#误差乘以隐含层的值作为隐含层激活后的结果
# update output weights 更新权重
for h in range(self.hidden_n):
for o in range(self.output_n):
change = output_deltas[o] * self.hidden_cells[h]
#调整权重:上一层每个节点的权重是学习参数*变化+矫正率
self.output_weights[h][o] += learn * change + correct * self.output_correction[h][o]
# update input weights
for i in range(self.input_n):
for h in range(self.hidden_n):
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct * self.input_correction[i][h]
self.input_correction[i][h] = change
# get global error
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o]) ** 2 #误差=
return error
def train(self, cases, labels, limit=10000, learn=0.05, correct=0.1):
for i in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn, correct)
一些知识点
- 分类器
机器学习的分类可以分为有监督分类,无监督分类。有监督分类是已经有参照标准结果,告诉机器输入和正确输出,让机器自己学习规则。无监督分类,是直接给机器一堆数据,让机器自己总结规则,划分主题,聚类等都是无监督。 - 激活函数
为了将无穷范围内的数据映射到一个有限范围。常用的激活函数有tan函数和sigmoid函数。后者是一个缓慢阶跃函数,同时严格对称,可以作为一个阈值划分两区域做分类的依据。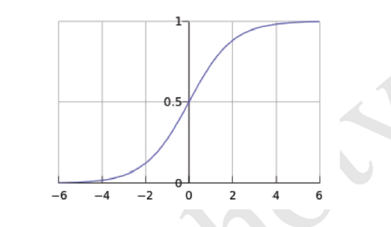
- 梯度下降法
梯度指的是数值的变化量。也就是函数求导。梯度反映了曲线的变化方向。梯度的反向,就是函数的下降方向了。运用梯度最低的地方,作为函数的最小值是可以理解的。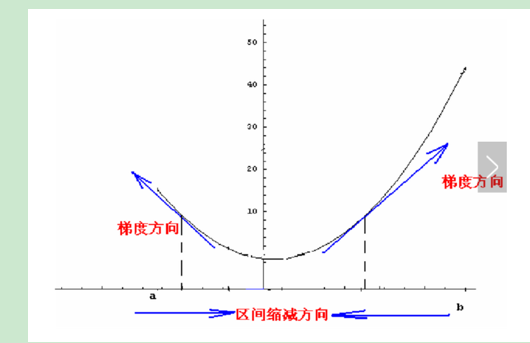
- 损失函数
如何表征预测值与实际值之间的差异,可以用一个损失函数的概念。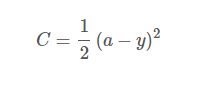
如上y是正确输出,a是预测结果值。
到此发现写一个技术博客真心累啊,难怪那些都是大牛才写的。过程中是读懂理解别人的介绍自己再输出出来,期间涵盖点点很容易说散,或者说累了不想说。然而以后要多一些这样的梳理。高大上的博客自己才有兴趣培养和看。
接下来计划hmm梳理,nlp梳理,crf梳理,svm梳理。每一块都是一大筐。