io和nio的区别
背景
传统的socket IO中,需要为每个连接创建一个线程,当并发的连接数量非常巨大时,线程所占用的栈内存和CPU线程切换的开销将非常巨大。使用NIO,不再需要为每个线程创建单独的线程,可以用一个含有限数量线程的线程池,甚至一个线程来为任意数量的连接服务。由于线程数量小于连接数量,所以每个线程进行IO操作时就不能阻塞,如果阻塞的话,有些连接就得不到处理,NIO提供了这种非阻塞的能力。 小量的线程如何同时为大量连接服务呢,答案就是就绪选择。这就好比到餐厅吃饭,每来一桌客人,都有一个服务员专门为你服务,从你到餐厅到结帐走人,这样方式的好处是服务质量好,一对一的服务,VIP啊,可是缺点也很明显,成本高,如果餐厅生意好,同时来100桌客人,就需要100个服务员,那老板发工资的时候得心痛死了,这就是传统的一个连接一个线程的方式。 老板是什么人啊,精着呢。这老板就得捉摸怎么能用10个服务员同时为100桌客人服务呢,老板就发现,服务员在为客人服务的过程中并不是一直都忙着,客人点完菜,上完菜,吃着的这段时间,服务员就闲下来了,可是这个服务员还是被这桌客人占用着,不能为别的客人服务,用华为领导的话说,就是工作不饱满。那怎么把这段闲着的时间利用起来呢。这餐厅老板就想了一个办法,让一个服务员(前台)专门负责收集客人的需求,登记下来,比如有客人进来了、客人点菜了,客人要结帐了,都先记录下来按顺序排好。每个服务员到这里领一个需求,比如点菜,就拿着菜单帮客人点菜去了。点好菜以后,服务员马上回来,领取下一个需求,继续为别人客人服务去了。这种方式服务质量就不如一对一的服务了,当客人数据很多的时候可能需要等待。但好处也很明显,由于在客人正吃饭着的时候服务员不用闲着了,服务员这个时间内可以为其他客人服务了,原来10个服务员最多同时为10桌客人服务,现在可能为50桌,60客人服务了。 这种服务方式跟传统的区别有两个: 1、增加了一个角色,要有一个专门负责收集客人需求的人。NIO里对应的就是Selector。 2、由阻塞服务方式改为非阻塞服务了,客人吃着的时候服务员不用一直侯在客人旁边了。传统的IO操作,比如read(),当没有数据可读的时候,线程一直阻塞被占用,直到数据到来。NIO中没有数据可读时,read()会立即返回0,线程不会阻塞。 NIO中,客户端创建一个连接后,先要将连接注册到Selector,相当于客人进入餐厅后,告诉前台你要用餐,前台会告诉你你的桌号是几号,然后你就可能到那张桌子坐下了,SelectionKey就是桌号。当某一桌需要服务时,前台就记录哪一桌需要什么服务,比如1号桌要点菜,2号桌要结帐,服务员从前台取一条记录,根据记录提供服务,完了再来取下一条。这样服务的时间就被最有效的利用起来了。 内容来自 :http://blog.csdn.net/zhouhl_cn/article/details/6568119
一、概念
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
二、NIO和IO的主要区别
下表总结了Java IO和NIO之间的主要区别:
| IO | NIO |
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
1、面向流与面向缓冲
Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2、阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3、选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
4、NIO的三大特性:
1、分散与聚集读取
2、文件锁定功能
3、网络异步IO
1.分散与聚集读取
要了解分散与聚集的读取,我们首先应该先了解一下磁盘的I/O,那么磁盘的I/O是以一种什么方式输入输出的呢?
当进程请求 I/O 操作的时候,它执行一个系统调用,将控制权移交给内核。底层函数 open( )、read( )、write( )和 close( )要做的无非就是建立和执行适当的系统调用。当内核以这种方式被调用,它随即采取任何必要步骤,找到进程所需数据,并把数据传送到用户空间内的指定缓冲区。内核试图对数据进行高速缓存或预读取,因此进程所需数据可能已经在内核空间里了。如果是这样,该数据只需简单地拷贝出来即可。如果数据不在内核空间,则进程被挂起,内核着手把数据读进 内存。
那么为什么不直接让磁盘控制器把数据送到用户空间的缓冲区呢? 首先, 硬件通常不能直接访问用户空间。其次,像磁盘这样基于块存储的硬件设备操作的是固定大小的数据块,而用户进程请求的可能是任意大小的或非对齐的数据块。在数据往来于用户空间与存储设备的过程中,内核负责数据的分解、再组合工作,因此充当着中间人的角色。
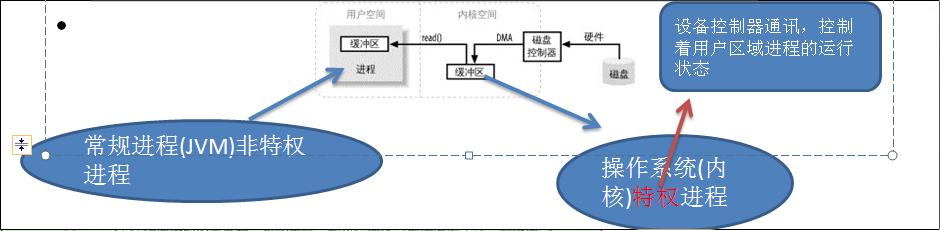
分散/聚集 I/O 是使用多个而不是单个缓冲区来保存数据的读写方法。
一个分散的读取就像一个常规通道读取,只不过它是将数据读到一个缓冲区数组中而不是读到单个缓冲区中。同样地,一个聚集写入是向缓冲区数组而不是向单个缓冲区写入数据。 进程只需一个系统调用,就能把一连串缓冲区地址传递给操作系统。然后,内核就可以顺序填充或排干多个缓冲区,读的时候就把数据发散到多个用户空间缓冲区,写的时候再从多个缓冲区把数据汇聚起来
如何实现:通道可以有选择地实现两个新的接口: ScatteringByteChannel 和 GatheringByteChannel。
一个 ScatteringByteChannel 是一个具有两个附加读方法的通道:
long read( ByteBuffer[] dsts );long read( ByteBuffer[] dsts, int offset, int length );
一个 GatheringByteChannel是一个具有两个附加写方法的通道:
long write( ByteBuffer[] srcs );long write( ByteBuffer[] srcs, int offset, int length );
2.文件锁定功能
3.网络异步IO
同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO
•阻塞(线程被挂起)IO:
socket 的阻塞模式意味着必须要做完IO 操作(包括错误)才会返回。
•非阻塞(线程不会被挂起)IO:
非阻塞模式下无论操作是否完成都会立刻返回,需要通过其他方式来判断具体操作是否成功。
•同步IO:
IO操作将导致请求进程阻塞,直到IO操作完成。
•异步IO:
IO操作不导致请求进程阻塞
•两者的区别就在于synchronous IO做”IO operation”(真实的IO操作)的时候会将process阻塞。
•阻塞和非阻塞就是进程的两种状态。
•同步和异步是只跟IO操作过程中进程的状态变化有关
•同步=/=阻塞,异步= /=非阻塞
•IO模型(5种之多):阻塞IO,非阻塞IO,IO复用,信号驱动IO,异步IO
•以linux 网络IO的read举例,介绍这些IO模型,其中整个过程涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,经历两个阶段:
1 等待数据准备
2 将数据从内核拷贝到进程中
•同步IO,需要用户进程主动将存放在内核缓冲区中的数据拷贝到用户进程中。
•异步IO,内核会自动将数据从内核缓冲区拷贝到用户缓冲区,然后再通知用户。