线性规划算法源码_老马识途之线性规划

机器学习无疑是当前非常火爆的话题,无论你是做后端,客户端还是前端,或多或少都听说过,并且其应用场景也非常多,作为技术男我们也非常想将各种听到烂大街的机器学习算法用于我们的工作场景中,于是找了看了各种算法的相关介绍,连实现的源码库都各种各样现成的,顿时信心满满,觉得可以放手大干一场,但是当遇到具体问题的时候,就两眼一抹黑,机器学习算法虽然多,但是不知道该用哪一个算法来解决这类问题呀,于是乎还得一个算法一个算法的去做深入的学习了解。
今天学习线性规划算法,主要从以下几个方面入手:
- 线性回归的定义
- 线性回归的应用场景
- 实际案例:使用线性回归预测股票价格
线性回归的定义
线性规划(Linear Regression)是利用线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
其数学表达式为:
线性回归应用场景
首先,线性回归是用于解决取值是连续性的问题,即其值是一个范围,而非分类问题(固定值是哪几个);其次,线性回归既可用于大数据场景,也可用于数据量比较小的场景,对数据量无特定要求;最后,当决定一个场景是否适合使用线性回归时,还需要对当前已有数据集的趋势进行判断,是否适合使用线性规划,对于数据维度比较小的数据集判断比较好的方式就是图形化,如:

像这种趋势的数据,就比较适合用线性规划,而对于点分布极不均匀,且无规律的数据集,则不适合用线性规划,效果不好。
使用线性回归预测股票价格
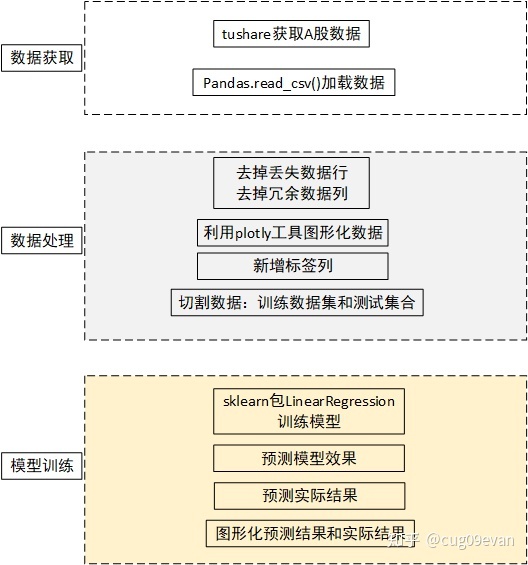
当我们需要对股票价格进行预测时,主要有以下几个步骤:
- 获取股票对应的数据
- 对数据进行分析处理
- 使用线性规划模型对数据进行预测
具体代码如下:
- 首先可以使用tushare获取某只股票的交易历史数据,如果你还没有安装, 可以使用 pip install tushare 安装tushare python包
import tushare as ts
# 000001为平安银行股票代码
df = ts.get_hist_data('000001')
df.to_csv('000001.csv')- 读取下载的数据,并查看数据格式
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime as dt
df = pd.read_csv('./000001.csv')
print(np.shape(df))
df.head()结果如下所示:

可以看到读取的数据集是一个611行,14列的数据。数据读取出来过后需要对数据进行分析。
- 由于股票数据是和日期比较相关的,因此考虑将数据集中的日期转化为date格式,然后作为数据的index
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df.tail()数据结果为:
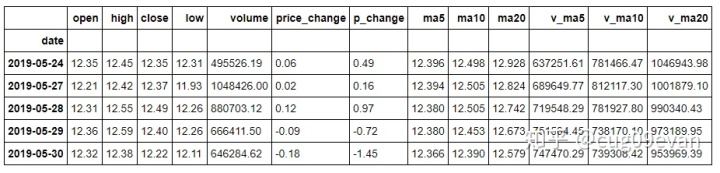
可以看到处理过后的数据,date这一行需要过滤掉
df.dropna(axis=0, inplace=True)
df.isna().sum()去掉有数据为Nan的行,然后统计所有列中数据为空的数量:

可以看到数据中已经没有空行了。
- 打印出数据集的一些主要信息,比如股票数据是从那一天开始的,到那一天等
min_date = df.index.min()
max_date = df.index.max()
print('First date is ', min_date)
print('Last date is ', max_date)
print(max_date - min_date)- 既然是需要对数据进行分析,那么我们首先应该将数据图形化,以方便我们查看数据的走势,来看看可以针对数据做哪些方面的预测。针对股票数据,我们就画出ohlc K线图
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
init_notebook_mode()
import plotly.plotly as py
import plotly.graph_objs as go
trace = go.Ohlc(x=df.index, open=df['open'], high=df['high'], low=df['low'], close=df['close'])
data = [trace]
iplot(data, filename='simple_ohlc')画出来的图行效果如下所示:

可以看到其实股票的长期趋势是没有什么特别的规律的,那如果看短期趋势会不会有什么规律呢,我们将ohlc图的局部放大来看:

看局部数据,我们猜测能不能通过历史数据来预测出来未来几天股票的收盘价的涨跌呢?如果能预测这种数据,那也是可以赚钱钱的呀,那我们就通过线性规划来预测一次试一试。
- 通过线性规划预测,那么首先就需要给数据集增加标签这一列,由于我们预测的是收盘价,那么是完全可以给历史数据进行打标的,假设我们需要预测未来5天的股价,具体做法如下:
num = 5
df['label'] = df['close'].shift(-num) #预测值
print(df.shape)通过将收盘价close的值偏移5位赋值给新增列label就可以完成对历史数据的打标
- 针对数据集中的数据,我们发现其实有几列是属于冗余列,可以根据其它数据计算出来,因此需要去除掉'label', 'price_change', 'p_change'这几列,以免影响线性模型的建模,生成新的数据集Data
Data = df.drop(['label', 'price_change', 'p_change'],axis=1)
Data.tail()- 生成自变量的数据集X和因变量数据集y,并查看两个向量的行数是否相等
# 将Data数据结构改成数组形式,方便计算
X = Data.values
# 对数据进行预处理
X = preprocessing.scale(X)
X = X[:-num]
df.dropna(inplace=True)
Target = df.label
y = Target.values
print(np.shape(X), np.shape(y))- 将上面生成的数据集X和y切割成训练集合测试集
X_train, y_train = X[0:550, :], y[0:550]
X_test, y_test = X[550:, -51:], y[550:606]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)由于此次数据集中总共是606条数据,因此考虑将其中550条数据切割成训练集
- 使用线性模型对数据集进行评估
lr = LinearRegression()
lr.fit(X_train, y_train)
# 使用绝对系数R^2评估模型
lr.score(X_test, y_test)评估的结果是0.04930040648385503,效果看起来不是很好,不过仅仅只是为了学习线性规划,随意我们用这个模型来真正的预测一下未来5天的真实结果
- 对具体的数据进行预测
# 对具体数据做预测
X_predict = X[-num:]
forecast = lr.predict(X_predict)
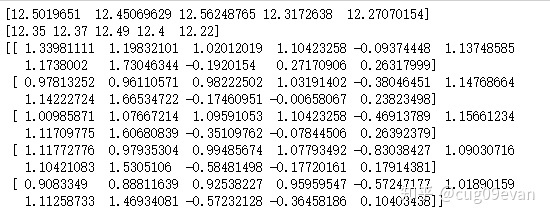
print(forecast) # 打印预测值
print(y[-num:]) # 打印实际值
print(X_predict) # 打印预测的五天数据的自变量结果为:
- 光看数据很难看出趋势,因此考虑将预测数据和实际数据画到图上面来进行对比
# 画出2019-05-13到2019-05-14,一共5天的收盘价
trange = pd.date_range('2019-05-13', periods=num, freq='d')
# 计算预测值的dataframe
predict_df = pd.DataFrame(forecast, index=trange)
predict_df.columns = ['forecast']
# 将预测值添加到原始dataframe
df= pd.read_csv('./000001.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df_concat = pd.concat([df, predict_df], axis=1)
df_concat = df_concat[df_concat.index.isin(predict_df.index)]
df_concat.tail(num)
# 画出预测值和实际值
df_concat['close'].plot(color='green', linewidth=1)
df_concat['forecast'].plot(color='red', linewidth=3)
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()画出来的结果如下:
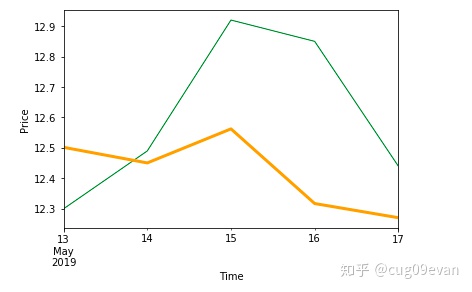
可以看出来预测的效果,至于好坏,可以自己评判一下,但是不要真的根据这个算法预测股票然后去买哟。
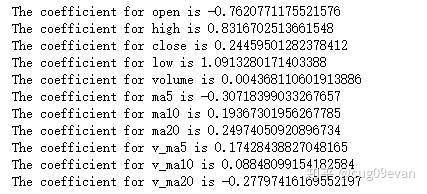
- 最后我们可以打印出模型中每个因变量的前的系数
for idx, col_name in enumerate(['open', 'high', 'close', 'low', 'volume', 'ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20']):
print("The coefficient for {} is {}".format(col_name, lr.coef_[idx]))打印出来的结果为