二次开发python_Python二次开发在行保后处理中的应用续
上文讲到Python二次开发在行保后处理中的应用。
链接:Python二次开发在行保后处理中的应用
当时编写时没有考虑到后处理效率的问题。比如一个项目中单次结果处理需要123个点的结果,则需要按顺序执行meta进行结果后处理,每次运行meta提取结果的时间约为5s左右。则顺序进行所有结果提取的时间约为615s,大概10分钟左右。这个效率过于低下。
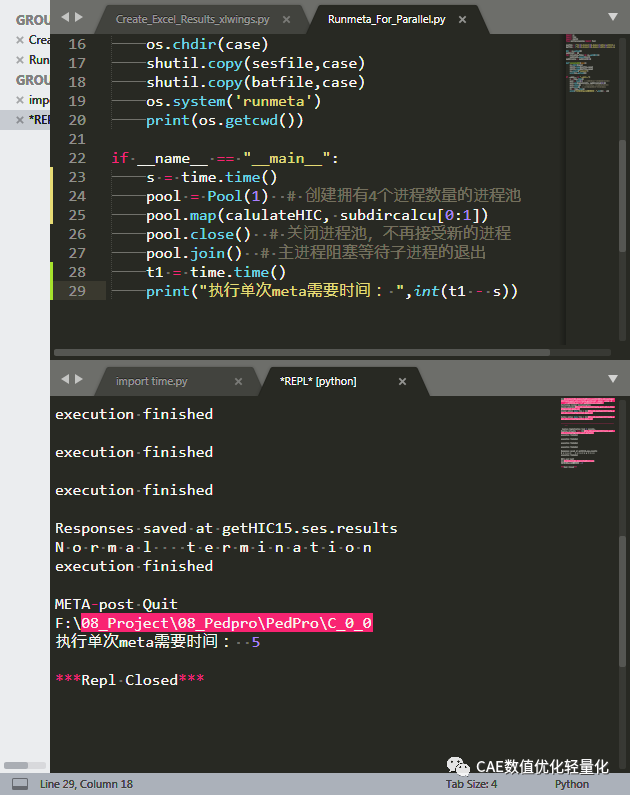
因此对脚本进行优化,需要用到Python的多进程管理包multiprocessing。
import osimport timeimport shutilfrom multiprocessing import Poolsesfile = r'F:\08_Project\08_Pedpro\PedPro\getHIC15.ses'batfile = r'F:\08_Project\08_Pedpro\PedPro\runmeta.bat'dir = os.getcwd()subdirall = []for root,dirs,files in os.walk(dir): subdirall.append(root)subdircalcu = subdirall[1:]def calulateHIC(case): os.chdir(case) shutil.copy(sesfile,case) shutil.copy(batfile,case) os.system('runmeta') print(os.getcwd())if __name__ == "__main__": pool = Pool(4) # 创建拥有4个进程数量的进程池 pool.map(calulateHIC, subdircalcu) pool.close() # 关闭进程池,不再接受新的进程 pool.join() # 主进程阻塞等待子进程的退出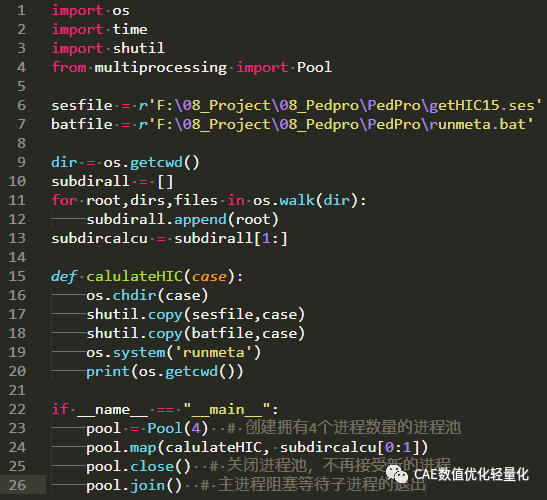
import osimport timeimport shutilimport xlwings as xwresultsfile = r'F:\08_Project\08_Pedpro\TS\TotalHIC.xlsx'app = xw.App(visible=True,add_book=False)wb = app.books.add()wb.save(resultsfile)wb = app.books.open(resultsfile)sht = wb.sheets[0] # or wb.sheets["sheet1"]time.sleep(1)for i , num in enumerate(range(14,-1,-1),start=2): sht.range("A"+ str(i)).value = "R" + str(num)for i , character in enumerate([chr(i) for i in range(86,65,-1)],start=-10): sht.range(character + "1").value = "C" + str(i)for i in range(2,17): for j in range(2,23): sht.range((i,j)).color = (166, 166, 166)sht.range('A1:V16').row_height =28sht.range('A1:V16').column_width =5list1 = []for i, num in enumerate(range(14,-1,-1),start=1): list1.append("R" + str(num))rowdict = dict(zip(list1,range(2,17,1)))list3 = []for i , character in enumerate([chr(i) for i in range(86,65,-1)],start=-10): list3.append("C" + str(i))columdict = dict(zip(list3,[chr(i) for i in range(86,65,-1)]))fill_red = (255, 0, 0)fill_brown = (151, 72, 6)fill_orange = (244, 119, 16)fill_yellow = (255, 255, 0)fill_green = (0, 176, 80)dir = os.getcwd()subdirall = []for root,dirs,files in os.walk(dir): #print('root_dir:',root) subdirall.append(root)subdircalcu = subdirall[1:]#print(subdircalcu)for i , case in enumerate(subdircalcu,start=1):# print(i) os.chdir(case) with open('getHIC15.ses.results','r') as g: for line in g.readlines(): if "HIC15" in line: HIC15 = line.split(',')[2] position = case.split("\\")[-1] c_position = position.split("_")[1] r_position = position.split("_")[2] r_posit = "R" + str(abs(int(r_position))) if int(r_position) >= 0: c_posit = "C" + c_position else: c_posit = "C-" + c_position sht.range(columdict[c_posit] + str(rowdict[r_posit])).value = round(float(HIC15)) if float(HIC15) >= 1700: sht.range(columdict[c_posit] + str(rowdict[r_posit])).color = fill_red elif float(HIC15) >= 1350 and float(HIC15) < 1700: sht.range(columdict[c_posit] + str(rowdict[r_posit])).color = fill_brown elif float(HIC15) >= 1000 and float(HIC15) < 1350: sht.range(columdict[c_posit] + str(rowdict[r_posit])).color = fill_orange elif float(HIC15) >= 650 and float(HIC15) < 1000: sht.range(columdict[c_posit] + str(rowdict[r_posit])).color = fill_yellow else: sht.range(columdict[c_posit] + str(rowdict[r_posit])).color = fill_green g.close() print(os.getcwd()) time.sleep(0.025)wb.save()wb.close()app.quit()
