如何使用MACS进行peak calling
MACS2是peak calling最常用的工具。
callpeak用法
这是MACS2的主要功能,因为MACS2的目的就是找peak,其他功能都是可有可无,唯独callpeak不可取代。最简单的用法就是
# 常规的peak calling
macs2 callpeak -t ChIP.bam -c Control.bam -f BAM -g hs -n test -B -q 0.01
# 较宽的peak calling
macs2 callpeak -t ChIP.bam -c Control.bam --broad -g hs --broad-cutoff 0.1
我们先来介绍这个案例里的参数。首先是常规的peak calling用到的参数
-
-t/--treatment FIELNAME和-c/--control FILENAME表示处理样本和对照样本输入。其中-t必须,很好理解,没有处理组你还找啥Peak。 -
-f/--format FORMAT用来声明输入的文件格式,目前MACS能够识别的格式有 "ELAND", "BED", "ELANDMULTI", "ELANDEXPORT", "ELANDMULTIPET" (双端测序), "SAM", "BAM", "BOWTIE", "BAMPE", "BEDPE". 除"BAMPE", "BEDPE"需要特别声明外,其他格式都可以用AUTO自动检测。 -
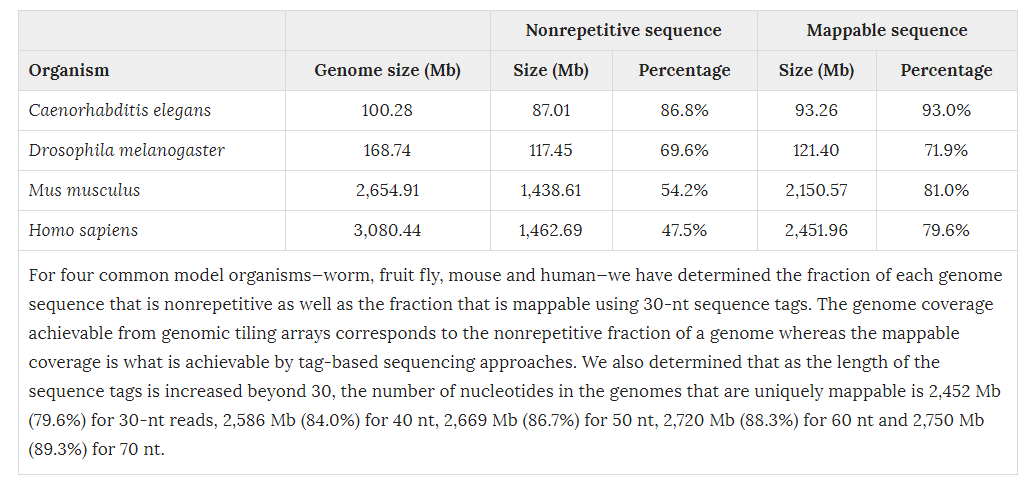
-g表示实际可比对的基因组大小。比如说人类是2.7e9,也就是2.7G,而实际人类基因组大概是3.2G左右。这是因为有些地方无法拼接,会用N代替,这部分区域大概是80%左右。拟南芥根据NCBI显示是119,667,750,那么实际能比对大概也就是1.0e8. NBT有一篇文章"PeakSeq enables systematic scoring of ChIP-seq experiments relative to controls"的表1就进行了统计。we
-
-n/--name表示实验的名字, 请取一个有意义的名字。 -
-B/--bdg: 以bedGraph格式存放fragment pileup, control lambda, -log10pvalue 和log10qvale.-
NAME_treat_pileup.bdg: 处理后数据 -
NAME_control_lambda.bdg: 对照的局部lambda值 -
NAME_treat_pvalue.bdg: 泊松检验的P值 -
NAME_treat_qvalue.bdg:Benjamini–Hochberg–Yekutieli处理后的Q值
-
-
-q: q值(最小的FDR)的阈值,默认0.05。可以根据结果进行修正。q值是p值经Benjamini–Hochberg–Yekutieli修正后的值。
一般常规是够用的,但是如果你需要看那些更加宽的peak,可以按照官方的建议使用如下参数
-
--broad: broad region最大长度是4d。其中d表示MACS的双峰模型两个peak的距离。结果会得到BED12格式文件,存放着附近高度附近的区域。由于要足够的宽,所以需要专门的参数进行统计学过滤。 -
--broad--cutoff: 用于过滤broad得到的peak,默认是q值,如果设置-p就用p值。
上面的基本参数可以用在最初的分析。根据基本的分析结果,可以有选择地使用下面的参数符合特定项目的需求。
比较基础的参数:
-
-s/--tsize: 二代测序读长,MACS会用前面10个序列进行推测。 -
--outdir: 输出文件夹 -
--verbose 0/1/2/3: 输出信息的详细度。如果是0就表示不想看到屏幕有输出。 -
-p/--pvalue: 使用P值,而不是q值,也就是说用未多重矫正的p值进行筛选。 -
--to-large: 默认是把大样本缩小和小样本一样小,设置该参数则是把小样本放大成大样本一样大。
和MACS模型构建相关的参数。正如MACS的名字所示, Model-based Analysis of ChIP-seq, 它需要先建立模型然后分析。那么问题来了,建立什么模型?模型的目的是什么?这里的模型指的是双峰模型,建立双模模型的目的是为了更好的将原始reads朝3'偏移,更好的表示蛋白和DNA的作用位置。这里还要多问一句为什么要偏倚。
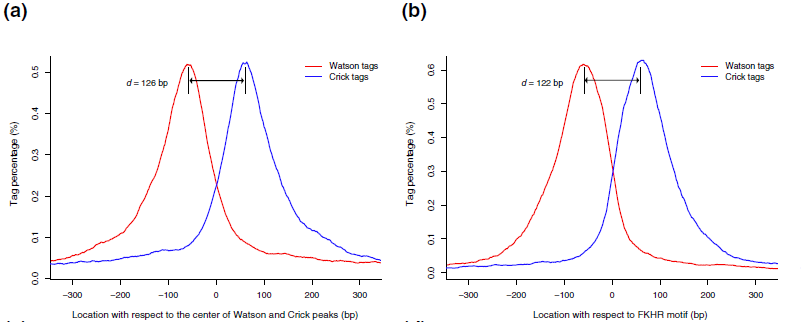
这就需要从实验建库说起。ChIP-seq目标是找到蛋白和DNA的作用位置,所以先要让蛋白和DNA进行交联,之后用超声打碎,再用抗体把与蛋白结合的DNA收集起来测序。在MACS发表的2008年,那个时候的测序大多都以单端50bp为主,而超声破碎的片段肯定大于50 bp(这可以通过电泳图来了解),也就是说最开始的SE50数据比对到参考基因组之后,得到的峰图并没有真实反映出原来的文库情况。但由于比对到基因组正负链的概率是相似的,那么就会形成两个峰(如下图),为了更好的还原出最来的文库片段,就先建立了双峰模型,以两峰距离d的一半作为偏倚长度。
如果你的数据是SE50或者SE100,为了更准确地找peak,你需要建立双峰模型,你可能要调整--bw, --mfold, --fix-bimodal, --shift, --extsize。 但是对于双端测序而言,它本身测的就是文库的两端,因此建立模型没有必要,偏倚也没有必要,你 只需要 设置参数--nomodel。
-
--bw: 这个参数仅仅当你知道ChIP实验中超声打断后的条带长度时才可能需要设置。用来构建双峰模型。 -
--nomodel: 这个参数说明不需要MACS去构建模型,也就是说下面的参数除了--shift, --extsize外都会被无视。 -
--extsize: MACS使用这个参数将read以5'-> 3'衍生至等长片段。比如说你知道你的转录因子的结合区域是200bp,那么参数就是--extsize 200。当且仅当--nomodel和--fix-bimodal设置使用。 -
--shift: 这个参数是绝对的偏移值,会先于--extsize前对read进行整体移动。MACS会通过建模的方式自动计算出read需要偏移的距离,除非你对自己的数据非常了解,或者前期研究都表明结合中心在read后面的那个位置上,你才能比较放心的用这个这个参数了。正数表示从5'往3'偏移延长到片段中心,如果是负数则是3'往5'偏移延长到片段中心。作者给了几个例子:- 如果是ChIP-seq数据,设置·--shift 0`
- 如果是
DNase-Seq数据:read来自于两个核小体中间,你想把测序read往两边延长用来平滑pileup信号,并且希望用来平滑的窗口是200bp,那么使用`--nomodel --shift -100 --extsize 200'. - 如果是
nucleosome-seq数据:因为一个核小体大概有147bp DNA缠绕,于是就需要用半个核小体长度进行堆积(pipleup)用于小波分析。参数为--nomodel --shift 37 --extsize 73.
-
-m/--mfold: 构建双峰模型时使用,默认是[5,50],表示选择那些倍数变化在5~10之间的富集区域。如果找不到100个区域构建模型,并且你还设置了--fix-bimodal时,它就会用--extsize参数继续分析 -
--nolambda: 设置这个参数就意味着不用MACS推荐的动态lambda,而是使用背景lambda作为local lambda,也就是不考虑染色质结构等造成的局部偏误。 -
--slocal, --llocal: 这两个参数也是MACS用来计算动态lambda会用到,分别计算1kb内lambda(slocal)和10kb的lambda(llocal),目标是处理类似于开放染色质区域的效应。注,如果这两个参数太小,输入数据中的尖峰(sharp spike)就可能干掉显著性的peak。
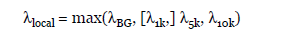
谨慎使用的参数:
-
--down-sample:如果你的电脑性能比较差,或者样本特别大,你希望快点看到一个差不多的结果,可以使用这个参数。MACS会对数据进行随机抽样,所以每次的结果会不太一样。如果结果是要发文章,不要用这个参数得到的结果。 -
--keep-dup: 保留重复。默认MACS(auto)会使用二项分布估计每个位置上是否存在重复(默认是1,也就是每个位置上出现一个read的概率最大)。如果你前期已经去重,那就使用all省了这一步.
callpeak结果文件说明
callpeak会得到如下文件:
- NAME_peaks.xls: 以表格形式存放peak信息,虽然后缀是xls,但其实能用文本编辑器打开,和bed格式类似,但是以1为基,而bed文件是以0为基.也就是说xls的坐标都要减一才是bed文件的坐标
- NAME_peaks.narrowPeak NAME_peaks.broadPeak 类似。后面4列表示为, integer score for display, fold-change,-log10pvalue,-log10qvalue,relative summit position to peak start。内容和NAME_peaks.xls基本一致,适合用于导入R进行分析。
- NAME_summits.bed:记录每个peak的peak summits,话句话说就是记录极值点的位置。MACS建议用该文件寻找结合位点的motif。能够直接载入UCSC browser,用其他软件分析时需要去掉第一行。
- NAME_peaks.gappedPeak: 格式为BED12+3,里面存放broad region和narrow peaks。
- NAME_model.r,能通过
$ Rscript NAME_model.r作图,得到是基于你提供数据的peak模型。 - .bdg文件能够用UCSC genome browser转换成更小的bigWig文件。
其他有用的子命令
bdgcmp使用*_treat_pileup.bdg和*_control_lambda.bdg计算得分轨(score track)
bdgpeakcall使用 *_treat_pvalue.bdg 或bdgcmp得到的结果或begGraph文件进行peak calling.bdgbroadcall差不多也是这样子。
bdgdiff能用来分析4个bedgraph文件,得到treatment1 vs control1, treatment2 vs control2, treatment1 vs control2, treament2 vs control1的得分。
filterdup:过滤重复,结果是BED文件
predictd:从比对文件中估计文库大小或d
randsample: 随机抽样
pileup:以给延伸大小去堆积(pileup)比对得到的reads。这一步不会有去重和测序深度标准化,你需要预先做这些工作。
推荐阅读
- BED格式: MACS2结果就有很多的BED格式,需要知道每一种BED格式目有啥不同。
- MACS文章: 看了这篇文章才能知道工具里面的参数的意义。
- BEDtools: 处理BED文件和Range数据神器,据说出来的时候号称可以替代10个生信分析师。