1、UTF-8
它是一种变长的编码方式,它可以用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
它是一种变长的编码方式,它可以用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
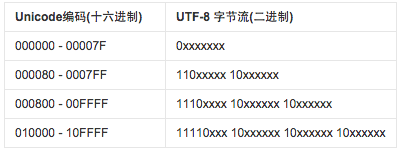
如图:UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。可以看出,比如对于英文字母a,UTF-8跟ASCII码的表示是一样的,所以UTF-8兼容ASCII码。
Tips1: UTF-8编码适用于网络数据传输,前缀码能让程序员很方便地用遍历的方法定位一段网络传输过来的字符串中出问题的字符,而不会影响到其他字符,保持能显示部分最大化,这对那些工作在较差网络环境下时很有利。而那些所有非前缀多字节编码在这种场合下最后的结果都是必须丢弃从出错点开始到结尾的所有编码,无论是GB码还是Unicode/UTF-16。
Tips2: UTF-8表示一个英文字符需要1个字节,而表示中文里我们常用到的汉字都需要3个字节。所以英文网站多是用UTF-8,而我们中文网站多是用GB码,我看腾讯、网易用的是GB2312。
2、UTF-16
它也是变长的,可以用2个字节或者4个字节来表示一个符号。Windows系统下的Unicode方式默认就是指UTF-16。
Tips1: Windows NT内核的字符表示为UTF-16 little endian。为什么呢?我自己的理解是:首先Unicode字符集全球通用,其次用UTF-8编码解码,我们的程序需要不断去处理那些前缀码的逻辑,效率较低。而对于UTF-16,大多数字符都可以用两个字节来表示,处理起来so easy。
3、UTF-32
是定长的,用4个字节表示一个符号,就空间而言,是非常没有效率的,使用也很少,就不讨论了。
4、文件用的哪种呢
要知道具体是哪种编码方式,需要判断文本开头的标志,下面是所有编码对应的开头标志:
开头标志 编码方式
EF BB BF UTF-8
FE FF UTF-16, little endian
FF FE UTF-16, big endian
FF FE 00 00 UTF-32, little endian.
00 00 FE FF UTF-32, big-endian.