2019独角兽企业重金招聘Python工程师标准>>> 
搜索即找到跟搜索词句很相似的文本,例如在百度中搜索"人的名",结果如下
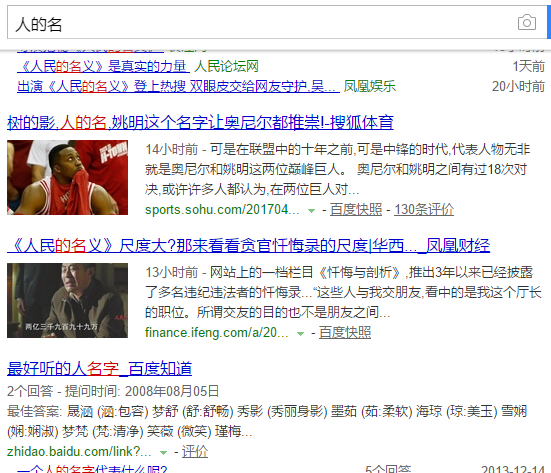
那么怎么评价两个文本之间的相似度呢?
余弦相似度 (cosine similiarity)
本文介绍基于VSM (Vector Space Model) 的 余弦相似度 算法来评价两个文本间的相识度。
余弦相似度,又称为余弦相似性。通过计算两个向量的夹角余弦值来评估他们的相似度。 -- 百度百科
两个空间向量之间的夹角越小,我们就认为这两个向量越吻合,cosθ 越大,当完全重合时 cosθ = 1
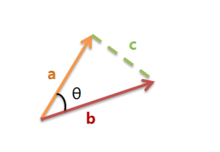
由余弦定律可知:(原谅我百度盗的公式图)
![]()
展开, 假设是n个维度一般化公式如下:
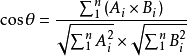
公式已经有了,我们需要将文本转化成可以计算的数据。
那么怎么把文本转化成向量呢?
文本向量化
使用词袋one-hot的方式,就是形成一个词的字典集,然后将文本中的词投射到词袋中,对应的位置用出现的频次填充,没有的填充零,例如有这么个词袋:
0 苹果
1 手机
2 魅族
3 非常
4 好用
5 美观
6 完美
7 小米
8 平板
9 薄每个词前面的数字表示序号(索引)
有四句话
A:苹果/手机/非常/美观
B:苹果/手机/非常/好用
C:小米/手机/非常/好用
D: 魅族/平板/非常/好用转化为向量
A: [1, 1, 0, 1, 0, 1, 0, 0, 0, 0]
B: [1, 1, 0, 1, 1, 0, 0, 0, 0, 0]
C: [0, 1, 0, 1, 1, 0, 0, 1, 0, 0]
D: [0, 0, 1, 1, 1, 0, 0, 0, 1, 0]转化完成,代入上面的公式计算:
B & A = 3/4 = 0.75
B & C = 3/4 = 0.75
B & D = 2/4 = 0.5从结果上看B跟AC都比较接近,但是跟D就相差很大。
但是,当你搜索B “苹果手机非常好用” 时,你可能更希望看到其他有关 “苹果手机” 的信息,因为这里的关键字是 “苹果”,那么怎么样才能把一些关键字的比重提高呢?换句话说怎么样把一些关键字识别出来进行重点关注。
TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。 -- 还是百度百科
TF: 一个词在文档中出现的频率 = 该词出现次数/文档中总词数IDF:log((文档库中总文档数+1)/(出现该词的文档数 + 1))TF描述的是一个词跟文档的相关度,一个文档中出现某个词越多说明该文档的主题跟该词有很大的关系;
IDF描述一个词的个性度(重要性),如果一个词在很多文档中出现说明该词是个“大众面”,如一大堆词都是一些公司名称,这时你说出两个字能非常好地定位到你需要的公司名字,那么你就要挑那个公司名字中核心的、独一无二的字,假如你挑 “公司” 这两个字那么等于没说,因为99%的名字中都含有 “公司” 两个字。
IDF原理来自【信息论】中 信息熵 (可以点击查看我另一篇关于 信息熵 的博客)
TF与IDF相乘以后得到的值为 TF-IDF,是衡量一个词对该文档的重要程度,该值越大表示重要性越大。
将上面的例子使用TF-IDF值作为向量的权重,取代之前的频次。
词袋IDF
0 苹果 2 IDF=0.737
1 手机 3 IDF=0.3219
2 魅族 1 IDF=1.3219
3 非常 4 IDF=0
4 好用 3 IDF=0.3219
5 美观 1 IDF=1.3219
6 完美 0 IDF=2.3219
7 小米 1 IDF=1.3219
8 平板 1 IDF=1.3219
9 薄 1 IDF=1.3219向量
A: [0.737, 0.3219, 0, 0, 0, 1.3219, 0, 0, 0, 0 ]
B: [0.737, 0.3219, 0, 0, 0.3219, 0, 0, 0, 0, 0 ]
C: [0, 0.3219, 0, 0, 0.3219, 0, 0, 1.3219, 0, 0 ]
D: [0, 0, 1.3219, 0, 0.3219, 0, 0, 0, 1.3219, 0 ]计算结果
B & A = 0.64678861/(1.547*0.866) = 0.48
B & C = 0.20723922/(0.866*1.398) = 0.17
B & D = 0.10361961/(0.866*1.90) = 0.06这样,B和A的相似得分最高,非常好地满足了我们的需求。
当然在实际使用时需要调整下计算公式,如加入词权重,文档权重等,还可以根据词出现的位置给予不一样的权重分值。
TF-IDF优点是计算比较快,有比较好的理论推导基础可信度非常高。
余弦相似度在实际使用时可以加入些优化使得计算更快,譬如预先计算好各个文档的 |d|,因为该值在文档形成时就已经确定,向量点乘计算时直接将两个向量的非零项相乘然后求和,不用挨个计算,因为实际中绝大多数项是零而且项数非常大,所以既耗时又白费。
下一篇准备写Lucene是怎么应用这个算法做搜索匹配的