欢迎关注瘋耔新浪微博:http://weibo.com/cpjphone
一.线性映射与非线性映射
1◑内存管理
①物理内存管理:
Linux内存最小管理单位为页(page),通常一页为4K。初始化时,linux会为每个物理内存也建立一个page的管理结构(切记是linux系统不是uboot,也就是物理内存的管理肯定是在linux系统上的),操作物理内存时实际上就是操作page页。某些设备会映射在物理内存地址外,这些地址会在使用时建立page结构。
②进程内存管理:
Linux进程通过vma进行管理,每个进程都有一个task_struct结构体进行维护,其中的mm_struct结构体管理这进程的所有内存。Mm_struct中维护者一个vma链表,其中的每一个vma节点对应着一段连续的进程内存。这里的连续是指在进程空间中连续,物理空间中不一定连续。如果使用malloc等申请一段内存,则内核会给进程增加vma节点。
2◑为何内核与进程空间不重合
进程:0~3G
内核:3G~4G
进程与内核合起来使用了4G的地址空间,而不是各自使用4G空间,获得的好处是进程进入内核是不需要切换页表,降低了进出内核的消耗。
在2.6内核中,所有进程的内核空间(3G~4G)都是共享的。
Linux启动后,第一个进程是init进程,它的页表与内核页表是一致的,系统中的其他所有进程都是init进程的儿子或后代。Linux中进程创建通过fork()实现,子进程的PGD与PTE是父进程的拷贝此时会把内核进程的页表拷贝到每个进程中。在各个进程的运行过程中,他们的页表可能会发生变化,比如发生缺页异常。如果是进程页表发生改变,则只要改变进程的页表项(0G~3G)就够了,如果是内核页表发生变化,则必须通知到所有进程改变各自维护的一份内核页表(3G~4G)。最简单的方法是每次内核页表改变后,遍历所有进程去改变他们维护的内核页表,显然效率很低。Linux内核通过page fault机制实现内核页表的一致。内核页表改变时,只改变init进程的内核页表。当进程访问该页时,会发生一个缺页异常,异常处理中通过init进程更新当前进程的内核页表。

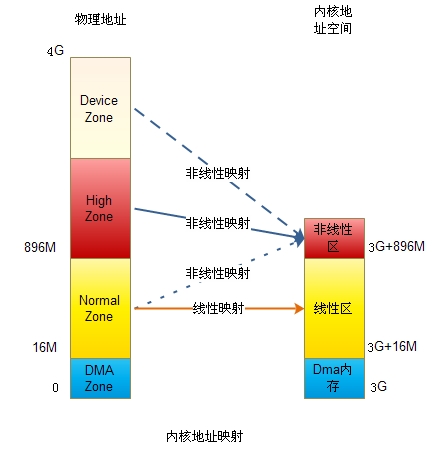
3 ◑非线性区域
非线性区与线性区是内核地址空间中的概念。
对于非线性区存在,可以做如下的解释。
Linux物理内存空间分为DMA内存区(DMA Zone)、低端内存区(Normal Zone)与高端内存区(Highmem Zone)三部分。DMA Zone通常很小,只有几十M。低端内存区与高端内存区的划分源于linux内核空间大小的限制。
Linux内核只有1G的空间,通常内核把物理内存与其地址空间做了线性映射,也就是一一映,这样可以提高内存访问速度。
当内存超过1G时,线性访问机制就不够用了,只能有1G的内存可以被映射,剩余的内存无法被内核使用。当然无法忍受。
为了解决这一问题,linux把内核分为线性区与非线性区两部分。线性区规定最大为896M,剩下的为非线性区。与线性区不同,非线性区不会提前进行内存映射,而是在使用时动态映射。线性区映射的物理内存成为低端内存,剩下的内存被称为高端内存。
假设物理内存为2G,则地段的896M为低端内存,通过线性映射给内核使用。其他的1128M内存为高端内存,可以被内核的非线性区使用。由于要使用128M非线性区来管理超过1G的高端内存,所以通常都不会映射,只有使用时才使kmap映射,使用完后要尽快用kunmap释放。
使用128M管理1G的内存是不是有点小马拉大车的感觉?其实不会,因为高端内存的大部分要进程使用。
对于物理内存为1G的内核,系统不会真的分配896M给线性空间,896M最大限制。下面是一个1.5G物理内存linux系统的真实分配情况,只有721M分配给了低端内存区,如果是1G的linxu系统,分配的就更少了。
MemTotal 1547MB
HighTotal 825MB
LowTotal 721MB
申请高端内存时,如果高端内存不够了,linux也会去低端内存区申请,反之则不行。
4 ◑linux管理之外的物理地址空间(other Addr)
理论上,32位系统可管理的物理地址空间为4G。x86架构多一些io空间。计算机系统中的每个设备都是要占用一定的物理地址空间的,如PCI设备,所以不会把4G都给内存,这也意味着32位系统无法支持4G内存。
对于这部分物理内存之外的物理地址空间,这段空间不知道应该怎么称呼,这里暂时称为Device Zone。
由于Device Zone没有被linux管理,也就不会为它建立page结构来管理,因此linux中使用该段内存时都是直接使用其物理地址,而使用物理内存则是通过向linux申请free page来实现。同样道理,这块肯定也不会映射到线性区,而是使用ioremap映射到非线性区域,或直接用mmap映射到进程空间。
二.内存申请
如果申请的内存是低端内存,因为低端内存一直都被映射在内核页表中,因此只需要一个page_address()函数就可以完成转换,也就是图中的线性映射。
如果申请的是高端内存,就没有这么简单了。
首先,如果可以在高端申请到足够的内存,需要先在非线性区映射,操作结束后在解除映射,我们可以使用kmap()与kunmap()解决这个问题。如果高端内存找不到足够的内存,则会在低端内存区分配一块,此时也该回调用kmap()与kunmap()函数,但内部实现时就只是调用page_address()获取地址,而不需要再映射到非线性区。
1◑进程空间内存分配
malloc/free:最常用的内存分配函数
valloc/free:分配的内存按页对齐
2◑内核空间内存分配
__get_free_pages/free_pages:分配制定页数的低端内存,不能分配在高端
Alloc_pages/__free_pages:分配izhiding页数的内存,可以是高端内存
Kmalloc/kfree:分配的内存物理上连续,只能在低端分配
Vmalloc/vfree:分配的内存在内核空间中连续,物理上无需连续。Vmalloc由于不需要屋里也连续,会造成TLB抖动,所以性能很差,一般只有在必须申请大块内存时才使用,如动态插入模块时。
三.地址转换
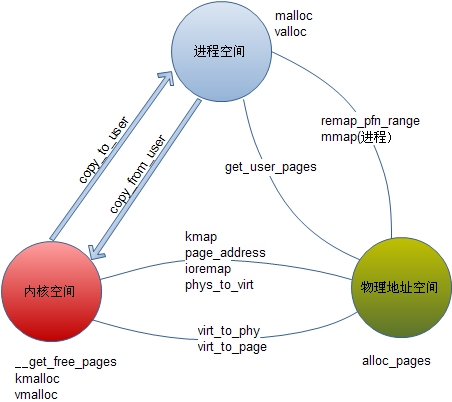
上图揭示了进程空间、内核空间与物理地址之间的转换关系。
在linux中,物理地址用page结构 表示,物理内存在初始化时已经生成了page结构管理,其他地址空间则需要生成page再进行管理(ioremap)。物理地址可以被映射到内核空间或进程空间,也可以从内核空间或进程用户空间解除物理地址(page)。
所有转换中,只有mmap可以在进程中使用,其他都是内核函数。即使使用mmap,其内部也是靠内核中使用remap_pfn_range实现的。所有地址空间转换都在内核中实现。
1◑进程空间与内核空间
copy_from_user //将用户空间的数据传送到内核空间, put_user -- Write a simple value into user space.
copy_to_user //从内核区中读取数据到用户区,get_user -- Get a simple variable from user space.
这两个函数不算是单纯的地址转换,他们完成的是进程空间与地址空间的数据拷贝,使用起来非常简单。
static ssize_t led_read(struct file *f, __user char *p, size_t size, loff_t *off) { if (copy_to_user(p, dev.mem, size)) { printk(KERN_ALERT”led: led_read Err.\n”); return -1; } printk(KERN_ALERT”led: led_read Ok: off = %d.\n”, off); return 0; } static ssize_t led_write(struct file *f, __user char *p, size_t size, loff_t *off) { if (copy_from_user(dev.mem, p, size)) { printk(KERN_ALERT”led: led_ write Err.\n”); return -1; } printk(KERN_ALERT”led: led_ write Ok: off = %d.\n”, off); return 0; }
2◑进程空间与物理地址
get_user_pages
该函数完成进程地址到物理地址的转换,要注意的是进程地址不一定是也对其的,但得到的物理地址是以page的形式给出,4k对齐,使用时要记得添加偏移量。下面是例程,。其中的current很有用,用于表示调用内核函数的进程,是一个task_struct结构体,其中的mm为该进程的内存管理结构,mm中的vmalist管理者进程vma链表。
static ssize_t led_read(struct file *f, __user char *p, size_t size, loff_t *off) { struct page *pg=NULL; char *addr; int loop, ret; down_read(¤t->mm->mmap_sem); ret = get_user_pages(current, current->mm, p, 1, 0, 1, &pg, NULL); up_read(¤t->mm->mmap_sem); addr = (char*)kmap(pg); if ((PAGE_SIZE-(unsigned long)p & 0xfff) < 8) { printk(KERN_ALERT”led: led_read size too small); return 0; } memcpy(addr + ((unsigned long)p & 0xfff), dev.mem, 8); kunmap(pg); printk(KERN_ALERT”led: led_read Ok: off = %d.\n”, off); return 0; }
remap_pfn_range
mmap
该函数完成物理地址到进程空间的映射,每个进程的地址空间用vma表示,所以就是把物理地址映射入vma。这里映射的物理地址一般都不会是内存,只有在linux管理之外的Device空间需要用制定物理地址的方式来进行映射,而一般的内存只要用kmalloc或malloc直接申请就可以了。
mmap是用户空间需要直接映射物理地址时调用的系统调用,其内部一般都通过remap_pfn_range实现。 mmap等于省去了kernel copy的工程,用物理地址直接到用户空间;
进程中调用:
caddr_t addr = mmap(NULL, PAGE_SIZE, PROT_WRITE, MAP_SHARED, f, paddr & PAGE_MASK);
内核中实现:
static int led_mmap(struct file *f, struct vm_area_struct *vma) { if (remap_pfn_range(vma, vma->start, (EPLD_BASE_ADDR + vma->vm_pgoff) >> PAGE_SHIFT, vma->vm_end – vma->vm_start, vma->vm_page_prot)) { printk(KERN_ALERT”led: led_mmap error.\n”); return –EAGAIN; } return 0; }
用户调用mmap后,在进入led_mmap之前,就已经为在进程空间申请号了进程地址空间,会存到一个新的vma结构体中,如果mmap第一个入参为NULL,则这块地址空间的起始地址有linux 自动分配,长度为第二个参数。led_mmap的入参vma就是之前分配的vma。
vm_pgoff 是前面mmap传入的paddr。EPLD_BASE_ADDR是设备基址如果为0,则vm_pgoff就是实际的物理地址。
3◑内核空间与物理地址
kmap
kmap实现物理内存到内核地址空间的映射,物理内存地址可以是低端内存区,也可以是高端内存区,如果是低端,作用与page_address相同。
ioremap
ioremap实现物理地址到内核空间的映射,所谓的物理地址一般是指非物理内存的地址空间,也就是不在linux管理下的物理地址空间。它可以把这一段映射到内核空间中的非线性空间。
page_address
简单的地址转换,只适用于线性区,实现page到内核地址空间的转换。
phy_to_virt
virt_to_page
virt_to_phy
几个简单的地址转化逆函数,只是用于线性区。
原文:http://www.cnblogs.com/Ph-one/p/4809714.html
载录:http://blog.chinaunix.net/uid-20528014-id-314322.html
----------------