2019独角兽企业重金招聘Python工程师标准>>> 
背景
MapReduce是一个有吸引力的框架,因为他允许我们将涉及计算文档相似度的数量积分解为独立的乘法和加法形式,这种形式适合多个机器的高效读取处理。
目标问题
计算大量文档集合中两两文档相似度。
遇到的问题
采集是一个许多问题都共有的任务。
对于适合随机读取内存的文档采集,解决方案比较简单。
随着采集大小的不断增长,然而,我们最终需要借助硬盘存储,此时,根据硬盘读取模式调整计算顺序成了一个挑战。
文档采集数量的进一步增长将会最终使得系统有必要通过多个处理器分担计算任务,此时,进程间通信变成了第二个潜在瓶颈,仅次于必须要优化的计算顺序。
解决
虽然特定的并行处理架构可以设计一个合适的实现方法,
但MapReduce架构(Dean和Ghemawat 2004年编写)提供了一个应对这些挑战更有吸引力的解决方案。【本文以后用的也是后者】
介绍MapReduce架构

图1阐述了MapReduce架构:“mapper”应用到每一个输入记录,其生成的每个结果被“reducer”聚合到一起。
成对文档相似度算法
我们的工作关注大量文档相似度的衡量,可用单词权重的数量积来表达。
包含特定单词的文档列表,其单词也一定包含在倒排索引的记录之中。因此,通过处理所有的记录,我们可以通过将单词贡献值加到一起计算整个成对相似矩阵。
算法1规范了这个想法。

我们为成对文档相似度问题提出了一个有效的解决方案,可以表示为两个独立MapReduce工作(图2),分为两个独立的MapReduce工作:索引和成对相似度

实验评估
为我们实现对称变化OkapiBM25(Olsson和Oard提出于2007年)作为相似度函数。我们使用AQUAINT-2新闻专线文本收集,包括906k文档,总共接近2.5GB。单词都是经过预处理的。
为了测试我们技术的可扩展性,我们从整个集合中取百分之10,20,25,50,67,75,80,90和100的子集合作为样本。

图3显示了两两文件相似阶段,不同大小集合下系统运行时间。整个集合的计算大概需要两个小时。
从经验出发,我们发现随着集合大小呈线性增长,这个一个非常让人满意的性能。
【不知道图3中R2=0.997是什么?】
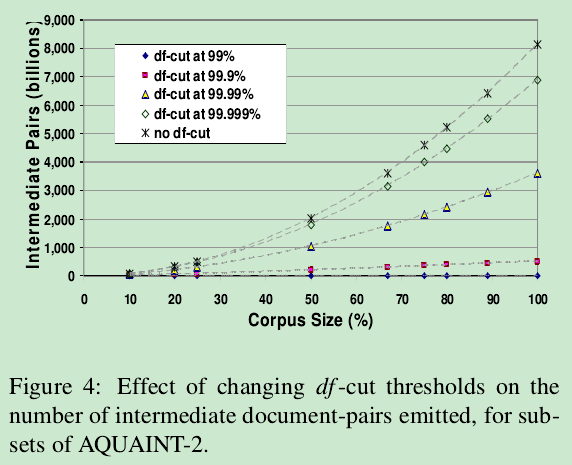
【图例表示原集合内容砍剩下99%,99.9%,99.99%等情况,差别挺小的,不知中间pairs的个数差别怎么这么大,单位居然用billions】
讨论
本章目标:为我们的算法复杂度提出一个分析模型
在我们的例子中,消除顶部1%的单词将文档对的数量减少了几个数量级。
Zipf's law分析
简单地说,Zipf发现一个词在一个有相当长度的语篇中的等级序号(该词在按出现次数排列的词表中的位置,他称之为rank,简称r)与该词的出现次数(他称为frequency,简称f)的乘积几乎是一个常数(constant,简称C)。用公式表示,就是r × f = C。例如,他根据M. L. Hanley(1937)中有关James Joyce Ulysses的用词数据,从中抽取了第10、20等序号的词,其序号(r)与在书中的出现次数(f)的乘积分别如下表的III栏。除了最后三个数字出入稍大一点,其他的都在26,000左右。而且,Zipf发现常数C乘以10跟该书的实际总词数260,430很接近,如IV栏所示。
I
Rank
(r)
II
Frequency
(f)
III
Product of I and II
(r × f = C)
IV
Theoretical Length ofUlysses
(C × 10)
10
2,653
26,530
265,300
20
1,311
26,220
262,200
30
926
27,780
277,800
40
717
28,680
286,800
50
556
26,500
278,000
100
265
26,500
265,000
200
133
26,600
266,000
300
84
25,200
252,000
400
62
24,800
248,000
500
50
25,000
250,000
1,000
26
26,000
260,000
2,000
12
24,000
240,000
3,000
8
24,000
240,000
4,000
6
24,000
240,000
5,000
5
25,000
250,000
10,000
2
20,000
200,000
20,000
1
20,000
200,000
29,899
1
29,899
298,990
【来自维基百科的解释】
Zipf's law /ˈzɪf/, an empirical law formulated using mathematical statistics, refers to the fact that many types of data studied in the physical and social sciences can be approximated with a Zipfian distribution, one of a family of related discrete power law probability distributions. 【一种离散概率分布】
The law is named after the American linguist George Kingsley Zipf (1902–1950), who first proposed it (Zipf 1935, 1949), though the French stenographer Jean-Baptiste Estoup (1868–1950) appears to have noticed the regularity before Zipf.[1] It was also noted in 1913 by German physicist Felix Auerbach[2] (1856–1933).
设置df-cut的意义
移除有意义的单词比如“arthritis”和“Cornell”,还有几乎没有意义的单词比如“sleek”和“frail”。但是新闻故事中相关单词的重复使用是非常常见的,
我们或许希望减少许多应用中移除这些低熵单词带来的相反影响。
效率VS效果的折衷
如图4所解释,将df-cut放宽到99.9%仍然会导致中间存储需求的线性增长(至少在这个区域)【6】。本质上说,优化df-cut是效率VS效果的折衷,会在具体应用中混合两者达到最优。