2019独角兽企业重金招聘Python工程师标准>>> 
作者 | 翟娜
大数据时代,数据的价值越来越被重视,企业从海量大数据中挖掘所需要的信息,用来驱动业务决策以获得更大的商业价值。
与此同时,出现了越来越多的大数据技术帮助企业进行大数据分析,例如 Apache Hadoop,Hive,Spark,Presto,Drill,以及今天我们即将介绍的 Apache Kylin 和 Apache Phoenix 项目等,都是使用 SQL 语言就可以分析大数据,极大地降低了大数据的使用门槛。
这些大数据技术提供 SQL 查询接口,不只是因为 SQL 学习成本低,同时也和 SQL 拥有丰富而强大的表达能力、能满足绝大多数的分析需求的特性有关系。
了解 Apache Kylin 和 Apache Phoenix 的同学都知道,它们都是使用 Apache HBase 做数据存储和查询,那么,同为 HBase 上的 SQL 引擎,它们之间有什么不同呢?下面我们将从这两个项目的介绍开始为大家做个深度解读和比较。
1、Apache Kylin
1.1Apache Kylin 介绍
Kylin 是一个分布式的大数据分析引擎,提供在 Hadoop 之上的 SQL 接口和多维分析能力(OLAP),可以做到在 TB 级的数据量上实现亚秒级的查询响应。
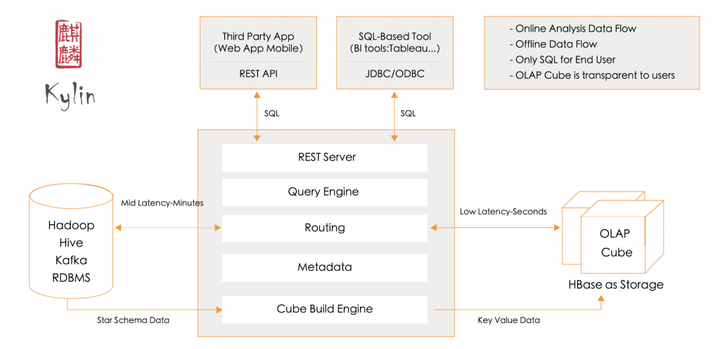
图1 Kylin 架构
上图是 Kylin 的架构图,从图中可以看出,Kylin 利用 MapReduce/Spark 将原始数据进行聚合计算,转成了 OLAP Cube 并加载到 HBase 中,以 Key-Value 的形式存储。Cube 按照时间范围划分为多个 segment,每个 segment 是一张 HBase 表,每张表会根据数据大小切分成多个 region。Kylin 选择 HBase 作为存储引擎,是因为 HBase 具有延迟低,容量大,使用广泛,API完备等特性,此外它的 Hadoop 接口完善,用户社区也十分活跃。
2、Apache Phoenix
2.1 Apache Phoenix 介绍
Phoenix 是一个 Hadoop 上的 OLTP 和业务数据分析引擎,为用户提供操作 HBase 的 SQL 接口,结合了具有完整 ACID 事务功能的标准 SQL 和 JDBC API,以及来自 NoSQL 的后期绑定,具有读取模式灵活的优点。
下图为 Phoenix 的架构图,从图中可以看出,Phoenix 分为 client 和 server,其中 client 又分为 thin(本质上是一个 JDBC 驱动,所依赖的第三方类较少)和非 thin (所依赖的第三方类较多)两种;server 是针对 thin client 而言的,为 standalone 模式,是由一台 Java 服务器组成,代表客户端管理 Phoenix 的连接,可以进行横向扩展,启动方式也很简单,通过 bin/queryserver.py start 即可。
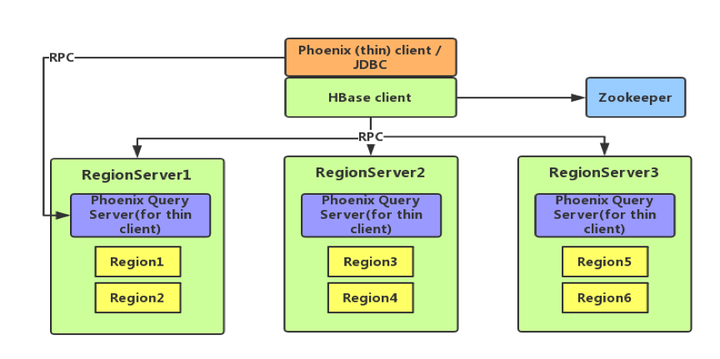
图2 Phoenix 架构图
接下来我们进行一个两者的对比。
3、Kylin 和 Phoenix 的对比
3.1 两者优缺点对比
我们先来看看 Kylin 和 Phoenix 各自的优点是什么。Kylin 的优点主要有以下几点:
1. 支持雪花/星型模型;
2. 亚秒级查询响应;
3. 支持 ANSI-SQL,可通过 ODBC,JDBC 以及 RESTful API 进行访问;
4. 支持百亿、千亿甚至万亿级别交互式分析;
5. 无缝与 BI 工具集成;
6. 支持增量刷新;
7. 既支持历史数据也支持流式数据;
8. 易用的管理页面和 API。
Phoenix 的优点则主要是以下几点:
1. 支持明细和聚合查询;
2. 支持 insert,update,delete 操作,其使用 upsert 来代替 insert 和 update;
3. 较好的利用 HBase 的优点,如 row timestamp,将其与 HBase 原生的 row timestamp 映射起来,有助于 Phoenix 利用 HBase 针对存储文件的时间范围提供的多种优化和 Phoenix 内置的各式各样的查询优化;
4. 支持多种函数:聚合、String、时间和日期、数字、数组、数学和其它函数;
5. 支持具有完整 ACID 语义的跨行及跨表事务;
6. 支持多租户;
7. 支持索引(二级索引),游标。
当然,Kylin 和 Phoenix 也都有一些还有待提升的不足之处,Kylin 的不足主要是体现在首先由于 Kylin 是一个分析引擎,只读,不支持 insert, update, delete 等 SQL 操作,用户修改数据的话需要重新批量导入(构建);其次,Kylin 用户需要预先建立模型后加载数据到 Cube 后才可进行查询;最后,使用 Kylin 的建模人员需要了解一定的数据仓库知识。
Phoenix 的不足则主要体现在:首先,其二级索引的使用有一定的限制,只有当查询中所有的列都在索引或覆盖索引中才生效且成本较高,在使用之前还需配置;其次,范围扫描的使用有一定的限制,只有当使用了不少于一个在主键约束中的先导列时才生效;最后,创建表时必须包含主键 ,对别名支持不友好。
3.2 HBase 表存储格式的对比
Kylin 将数据列区分成维度和度量:维度的顺序与 HBase 中的 Rowkey 建立关系从而将 Cube 数据存储,维度的值会被编码为字节,然后多个维度的值被拼接在一起组成 Rowkey,Rowkey 的格式为 Shard ID(2 字节)+ Cuboid ID(8 字节,标记有哪几个列)+ 维度值;度量的值会被序列化为字节数组,然后以 column 的方式存储;多个度量值可以放在同一个列簇中,也可以放在不同列簇中。如下图所示:
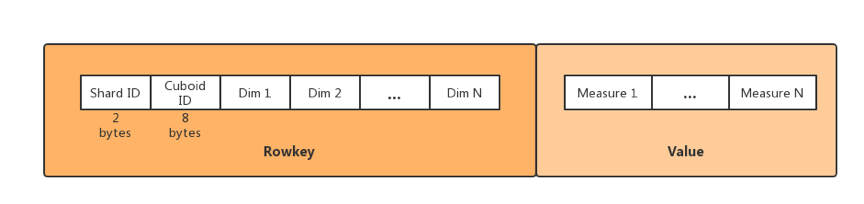
图3 Kylin 的 HBase Table 格式
Phoenix 在列名与 HBase 列限定符之间引入了一个间接层,将 HBase 非关系型形式转换成关系型数据模型,在创建表时默认会将 PK 与 HBase 中表的 Rowkey 映射起来,PK 支持多字段组合,剩下的列可以根据需求进行选择,列簇如果未显式定义,则会被忽略,Qualifier 会转换成表的字段名。如下图所示:
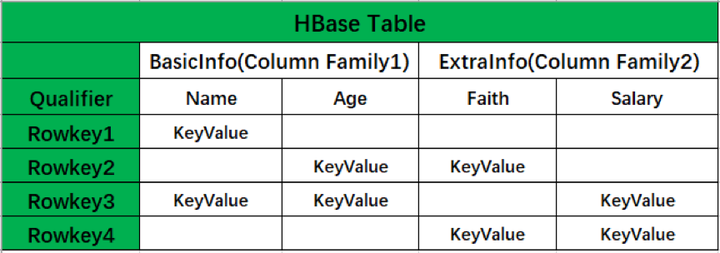
图4 Phoenix 数据模型
3.3 查询方式对比
Kylin 查询时会将 SQL 通过 Apache Calcite 进行解析和优化,转化成对 HBase 的 RPC 访问。Kylin 会将计算逻辑下压到 HBase Region Server 中使用 Coprocessor 并行运行,每个 RS 返回过滤聚合后的数据给 Kylin 节点,Kylin 做最后的处理后返回给客户端。因为大量的计算在 Cube 生成的时候已经完成,因此 Kylin 的查询效率非常高,通常在毫秒到秒级。
Kylin 在 Insight 页面提供 SQL 查询窗口;也能够通过 REST API 发送请求的方式进行查询;还能够快速的与其他 BI 工具集成并使用 BI 工具自带的方式进行查询。
Phoenix 直接使用 HBase API,以及协处理器和自定义过滤器,从而使得查询的效率更好。对于查询,Phoenix 可以根据 region 的边界进行分块并在客户端并行运行以减少延迟。聚合操作将在服务器端的协处理器中完成(这点与 Kylin 类似),返回到客户端的数据量是进行过压缩的,而不是全部返回。
Phoenix 是通过命令行的方式进行查询(既可以输入单条 SQL 语句,也可以执行 SQL 文件);也可以通过界面进行查询,但需额外安装 Squirrel。
3.4 查询优化方式对比
Kylin 查询优化方法比较多样,既有逻辑层的维度减枝优化(层级,必须,联合,推导等),编码优化,rowkey 优化等,也有存储层的优化,如按某个维度切 shard,region 大小划分优化,segment 自动合并等,具体可以参考 Kylin 的文档。用户可以根据自己的数据特征、性能需求使用不同的策略,从而在空间和时间之间找到一个平衡点。
为了使得查询效率更高,Phoenix 可以在表上加索引,不同的索引有不同的适用场景:全局索引适用于大量读取的场景,且要求查询中引用的所有列都包含在索引中;本地索引适用于大量写入,空间有限的场景。索引会将数据的值进行拷贝,额外增加了开销,且使用二级索引还需在 HBase 的配置文件中进行相应配置。数据总不会是完美分布的,HBase 顺序写入时(行键单调递增)可能会导致热点问题,这时可以通过加盐操作来解决,Phoenix 可以为 key 自动加盐。
从上述内容可以看出:
1)Kylin 和 Phoenix 虽然同为 Hadoop/HBase 上的 SQL 引擎,两者的定位不同,一个是 OLAP,另一个是 OLTP,服务于不同的场景;
2)Phoenix 更多的是适用于以往关系型数据库的相关操作,当查询语句是点查找和小范围扫描时,Phoenix 可以比较好地满足,而它不太适合大量 scan 类型的 OLAP 查询,或查询的模式较为灵活的场景;
3)Kylin 是一个只读型的分析引擎,不适合细粒度修改数据,但适合做海量数据的交互式在线分析,通常跟数据仓库以及 BI 工具结合使用,目标用户为业务分析人员。
下面我们做一个简单的性能测试,因为 Kylin 不支持数据写入,因此我们不得不测试数据的查询性能,使用相同 HBase 集群和数据集。
3.5 性能对比
我们准备的测试环境为 CDH 5.15.1,1个 Master,7个 Region Server,每个节点 8 核心 58G 内存,使用 Star Schema Benchmark 数据进行测试。其中单表 Lineorder 表数据量为 3 千万,大小为 8.70 GB。Phoenix 导入时间: 7mins 9sec, Kylin 导入时间: 32mins 8sec。多表 Lineorder 数据量 750 万,大小为 10 GB。具体的 SQL 语句参见Github。
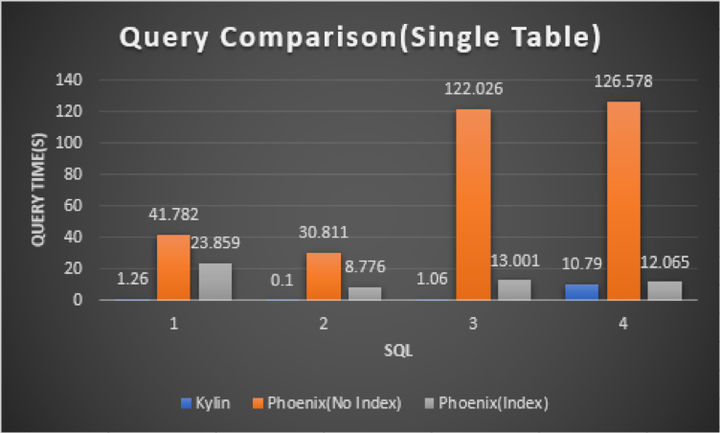
图5 单表对比图
图 5 是一个单表查询场景的分析,从上我们可以看出, 针对于一张表的查询,Phoenix 查询的耗时是 Kylin 的几十甚至是几百倍,加入索引后,Phoenix 的查询速度有了较为显著的提升,但仍然是 Kylin 的十几倍甚至几十倍,因此单表查询 Kylin 具有明显优势。
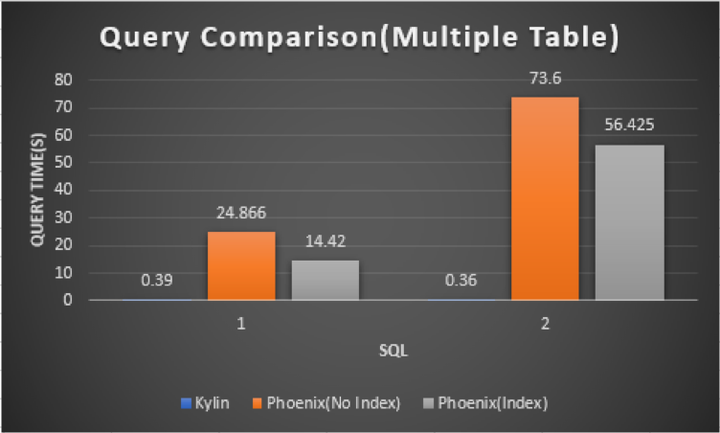
图6 多表对比图
图6是一个多表 join 查询的场景,从上图可以看出,对于多表 join 的情况,Kylin 查询依旧非常快,因为 join 在 Cube 构建阶段已经完成了;Phoenix 加入索引后时间并没有较为显著的减少,耗时仍然是 Kylin 的几十倍甚至几百倍。
因此,无论是单表还是多表查询,Kylin 查询的时间都远远小于 Phoenix,当然这是因为有了预计算的原因。
4、总结
简单来看,Apache Phoenix 与Apache Kylin 似乎都是 Hadoop/HBase 上的 SQL 引擎,实际上它们服务于不同的目的,Phoenix 适用于频繁写但读取少的事务型场景,Kylin 则适合写少读多的分析型场景;在 OLTP 的场景中,Phoenix 具有低延迟、高并发、事务性等优点;在 OLAP 的场景下,Kylin 更具有优势。用户应该根据自身的实际情况,选择合适的引擎。
5、参考
1. http://kylin.apache.org/
2. http://phoenix.apache.org
3. https://github.com/apache/phoenix
4.https://www.slidestalk.com/s/Track22_Apach153449959792451
5. https://www.jianshu.com/p/91decdd7fc5d