http://spaces.ac.cn/archives/3924/
关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
关于双向LSTM,理解的思路是:双向LSTM是LSTM的改进版,LSTM是RNN的改进版。因此,首先需要理解RNN。
笔者曾在拙作《从Boosting学习到神经网络:看山是山?》说到过,模型的输出结果,事实上也是一种特征,也可以作为模型的输入来用,RNN正是这样的网络结构。普通的多层神经网络,是一个输入到输出的单向传播过程。如果涉及到高维输入,也可以这样做,但节点太多,不容易训练,也容易过拟合。比如图像输入是1000x1000的,难以直接处理,这就有了CNN;又或者1000词的句子,每个词用100维的词向量,那么输入维度也不小,这时候,解决这个问题的一个方案是RNN(CNN也可以用,但RNN更适合用于序列问题。)。
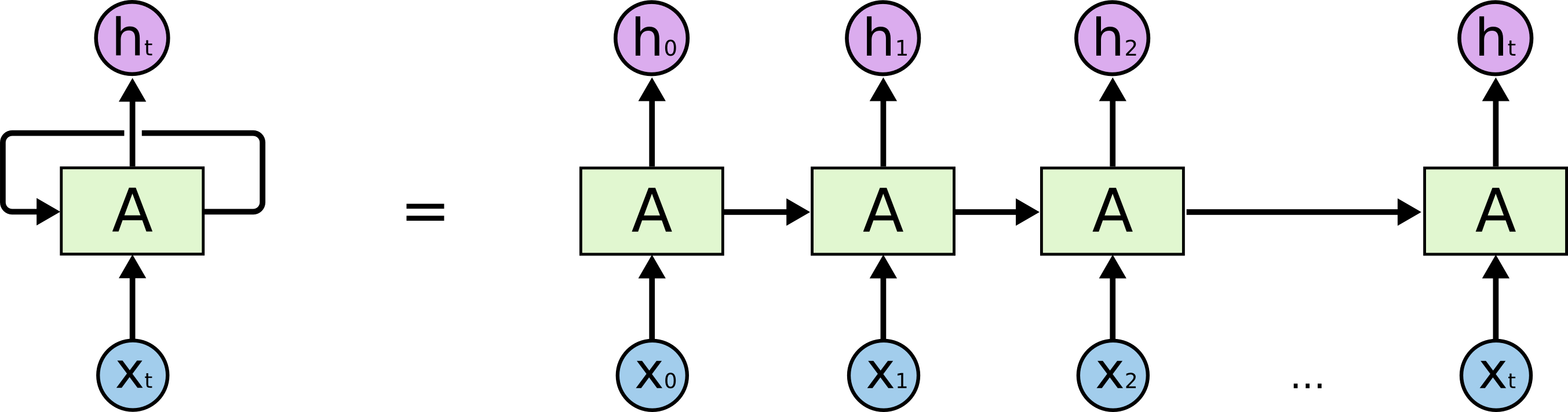
RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。
LSTM对RNN做了改进,使得能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要,但是对于分词这个任务来说是不妥的,因为句子各个字应该是平权的。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。
在分词任务中的应用
关于深度学习与分词,很早就有人尝试过了,比如下列文章:
http://blog.csdn.net/itplus/article/details/13616045
https://github.com/xccds/chinese_wordseg_keras
http://www.leiphone.com/news/201608/IWvc75oJglAIsDvJ.html
这些文章中,不管是用简单的神经网络还是LSTM,它们的做法都跟传统模型是一样的,都是通过上下文来预测当前字的标签,这里的上下文是固定窗口的,比如用前后5个字加上当前字来预测当前字的标签。这种做法没有什么不妥之处,但仅仅是把以往估计概率的方法,如HMM、ME、CRF等,换为了神经网络而已,整个框架是没变的,本质上还是n-gram模型。而有了LSTM,LSTM本身可以做序列到序列(seq2seq)的输出,因此,为什么不直接输出原始句子的序列呢?这样不就真正利用了全文信息了吗?这就是本文的尝试。
LSTM可以根据输入序列输出一个序列,这个序列考虑了上下文的联系,因此,可以给每个输出序列接一个softmax分类器,来预测每个标签的概率。基于这个序列到序列的思路,我们就可以直接预测句子的标签。
Keras实现
事不宜迟,动手最重要。词向量维度用了128,句子长度截断为32(抛弃了多于32字的样本,这部分样本很少,事实上,用逗号、句号等天然分隔符分开后,句子很少有多于32字的。)。这次我用了5tag,在原来的4tag的基础上,加上了一个x标签,用来表示不够32字的部分,比如句子是20字的,那么第21~32个标签均为x。
在数据方面,我用了Bakeoff 2005的语料中微软亚洲研究院(Microsoft Research)提供的部分。代码如下,如果有什么不清晰的地方,欢迎留言。
# -*- coding:utf-8 -*-
import re
import numpy as np import pandas as pd s = open('msr_train.txt').read().decode('gbk') s = s.split('\r\n') def clean(s): #整理一下数据,有些不规范的地方 if u'“/s' not in s: return s.replace(u' ”/s', '') elif u'”/s' not in s: return s.replace(u'“/s ', '') elif u'‘/s' not in s: return s.replace(u' ’/s', '') elif u'’/s' not in s: return s.replace(u'‘/s ', '') else: return s s = u''.join(map(clean, s)) s = re.split(u'[,。!?、]/[bems]', s) data = [] #生成训练样本 label = [] def get_xy(s): s = re.findall('(.)/(.)', s) if s: s = np.array(s) return list(s[:,0]), list(s[:,1]) for i in s: x = get_xy(i) if x: data.append(x[0]) label.append(x[1]) d = pd.DataFrame(index=range(len(data))) d['data'] = data d['label'] = label d = d[d['data'].apply(len) <= maxlen] d.index = range(len(d)) tag = pd.Series({'s':0, 'b':1, 'm':2, 'e':3, 'x':4}) chars = [] #统计所有字,跟每个字编号 for i in data: chars.extend(i) chars = pd.Series(chars).value_counts() chars[:] = range(1, len(chars)+1) #生成适合模型输入的格式