“学”、“习”二合一:监督学习——支持向量机(SVM)入门
更多深度文章,请关注:https://yq.aliyun.com/cloud

当你正在处理文本分类问题,当你正在改进你的训练集,也许你已经尝试使用Naive Bayes。但是现在你对数据集分类有信心,并希望进一步了解整个数据集的特征。我想支持向量机(SVM):一种快速可靠的分类算法,可以在有限的数据量下帮你做的更好。
SVM算法背后的思想很简单,将其应用于自然语言分类并不需要大部分复杂的东西。
在继续之前,我们建议你首先阅读our guide to Naive Bayes classifiers(Naive Bayes分类器的解释),因为有关文本处理的许多事情也与此相关。
SVM如何工作?
支持向量机的基础知识及其工作原理可以通过一个简单的例子来理解。我们假设有两个类别:红色和蓝色,我们的数据有两个特征:x和y。我们想要一个分类器,给定一对(x,y)坐标,如果它是红色或蓝色,则在坐标轴上输出红点或者蓝点,我们将我们已经标记的训练数据绘制在坐标轴上:
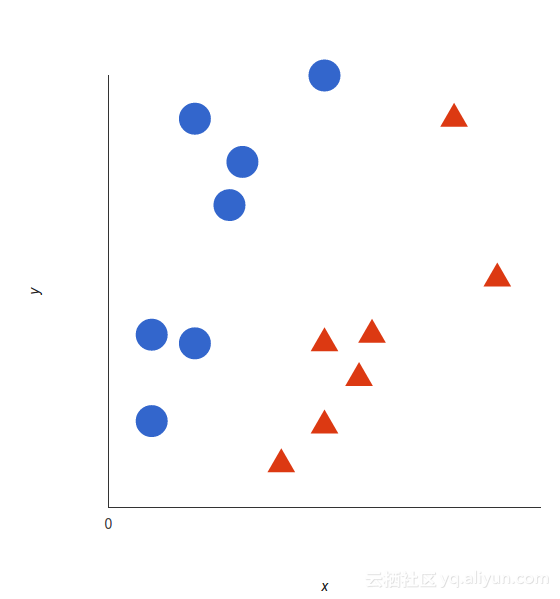
支持向量机采用这些数据点并输出最佳分类的超平面(其在二维中只是一条线)。这条线是决策边界:任何落在其一侧的东西,我们将分类为蓝色,另外一侧就是红色。
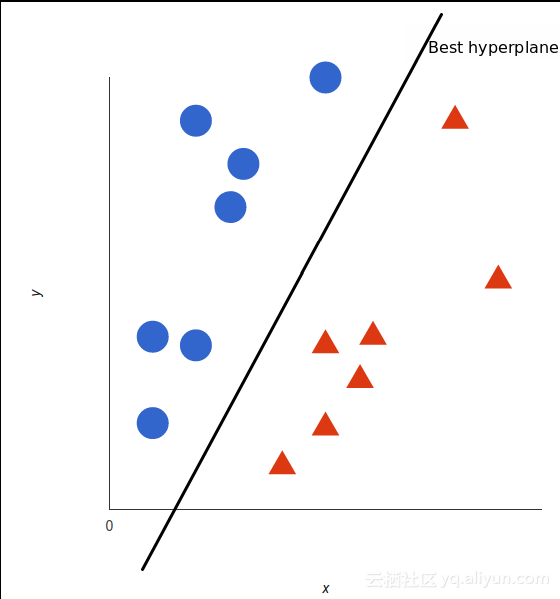
但是,什么是最优的超平面?对于SVM来说,如果训练数据可以无误差地被划分,并且每一类数据中距离超平面最近点和超平面之间的距离最大。超平面决定了我们对数据分类的准确度。
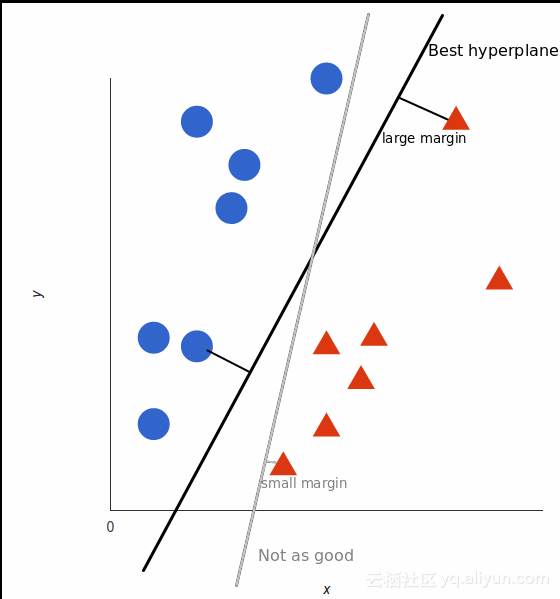
你可以查看此视频教程,了解如何找到最佳超平面。
非线性数据
现在这个例子很简单,因为数据显然是线性分离的,我们可以画一条直线来分开红色和蓝色。可悲的是,通常情况并不简单。看看这种情况:
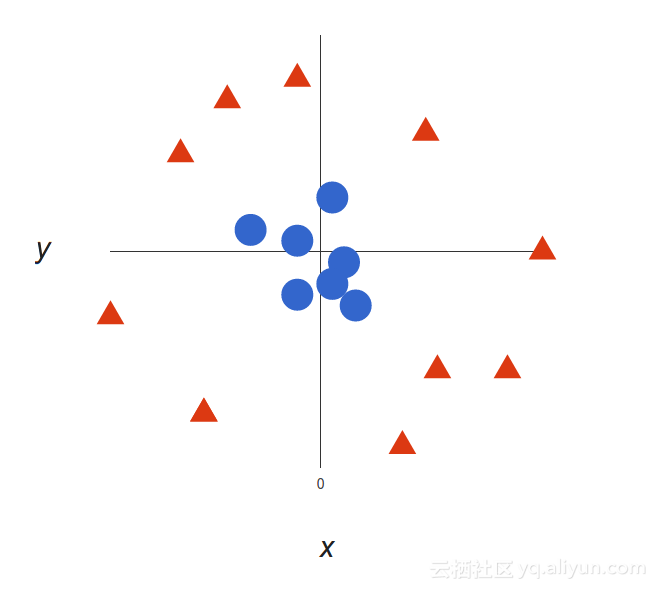
很清楚的可以看到这没有一个线性决策边界(一个直线分开两个类别)。然而,这些向量非常清楚地分离,看起来好像应该很容易分开它们。
所以这里是我们要做的:我们将添加第三维。到目前为止,我们有两个维度:x和y。我们创建一个新的维度z,我们创建它是因为它是一种方便的方式可以计算出来的:z = x2 + y2(你会注意到这是一个圆的方程式)。
这将给我们一个三维的空间。看一下这个空间,看起来像这样:
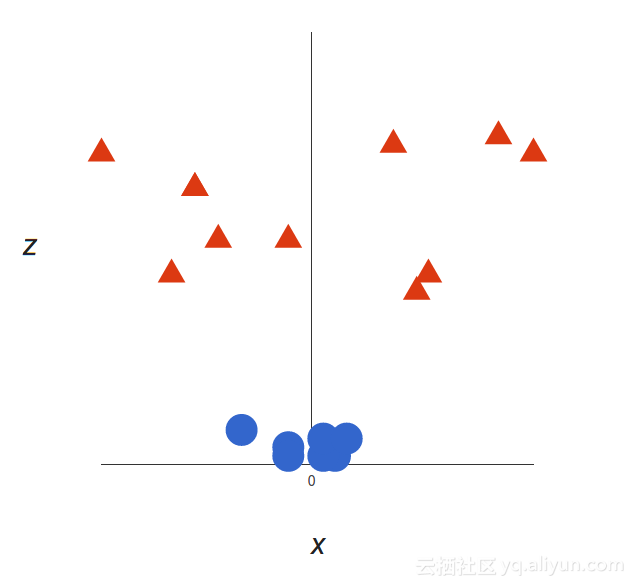
SVM可以做什么?让我们来看看:
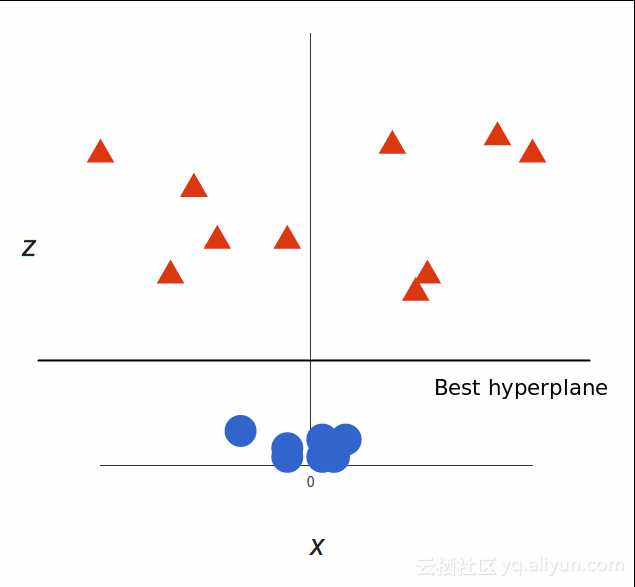
请注意,由于现在我们处于三维空间,超平面是在某一z(即z = 1)平行于x轴的平面。
我们将其映射回二维:
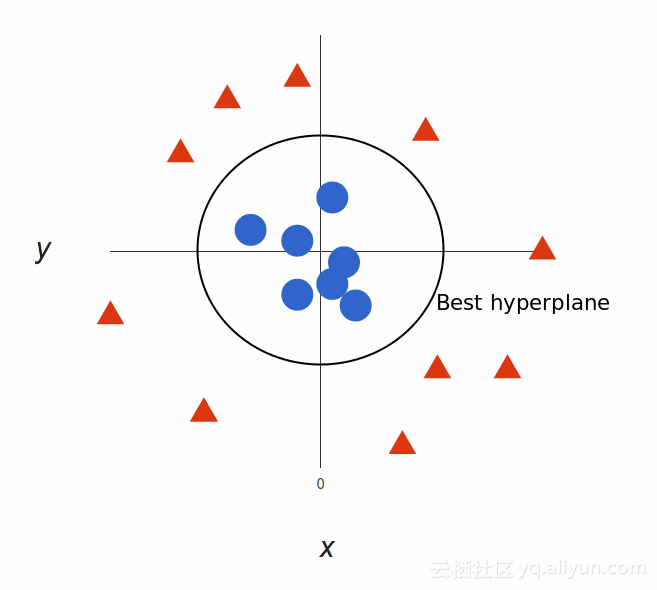
我们的决策边界是半径为1的圆周。
核技巧
在我们的例子中,我们找到了一种通过将我们的空间巧妙地映射到更高维度来分类非线性数据的方法。然而,事实证明,计算这种转换可能会带来很大的计算成本:可能有很多新的维度,每一个都可能涉及复杂的计算。数据集中的每个向量执行此操作都需要做很多工作,所以去找到一个更便宜的解决方案就变得非常重要了。
这是一个窍门:SVM不需要实际的向量来工作,它实际上可以通过它们之间的点积(Dot product)获得。这意味着我们可以回避昂贵的计算!
想象一下我们想要的新空间:
z = x 2 + y 2
弄清楚该空间中的点积(Dot product)是什么样的:
a·b = xa·xb+ ya·yb+ za·zb
a·b = xa·xb+ ya·yb+(xa2 + ya2)·(xb2 + yb2)
告诉SVM做它的事情,但要使用新的点积 - 我们称之为内核函数。
这是内核技巧,这使我们能够避开很多昂贵的计算。通常,内核是线性的,我们得到一个线性分类器。然而,通过使用非线性内核(如上所述),我们可以得到一个非线性分类器,且不用转换数据,我们只将数量积改变为我们想要的空间。
注意,内核技巧实际上不是SVM的一部分。它可以与其他线性分类器一起使用,如逻辑回归。支持向量机只负责找出决策边界。
SVM如何与自然语言分类一起使用?
我们可以在多维空间中对向量进行分类。但现在我们要将这个算法应用于文本分类,首先我们需要的是将一段文本转换为一个数字向量,以便我们可以运行SVM。换句话说,我们必须使用哪些功能才能使用SVM对文本进行分类?
最常见的答案是字频,就像我们在Naive Bayes一样。这意味着我们将一个文本视为一个单词,对于这个包中出现的每个单词,我们都能记录它出现的频率。
这种方法只是为了计算每个单词在文本中出现次数,并将其除以总字数。所以,在句子“All monkeys are primates but not all primates are monkeys”这个monkey有2/10 = 0.2的频率,and这个词,但有1/10 = 0.1的频率。
对于更高级的计算频率的替代方案,我们也可以使用TF-IDF(逆文档频率)。
现在我们已经做到了,我们的数据集中每个文本都被表示为具有数千(或数万)维度的向量,每一个都代表文本中的一个单词的频率。我们可以通过使用预处理技术来改善这一点,例如词干提取,删除停止词和使用N元文法n-gram。
选择一个核函数
现在我们有特征向量,唯一需要做的就是为我们的模型选择一个内核函数。每个问题都不同,内核功能取决于数据分布的外观。在我们的例子中,我们的数据是以同心圆排列的,所以我们选择了一个与这些数据分布外观匹配的内核。
考虑到这一点,自然语言处理最好用哪一种?我们需要一个非线性分类器吗?还是数据线性分离?事实证明,最好坚持线性内核。为什么?
回到我们的例子中,我们有两个特征。SVM在其他领域的一些实际用途可能会使用数十甚至数百个特征,而NLP分类器使用有成千上万的特征。这会出现新的问题:在其他情况下使用非线性内核可能是一个好主意,有这么多特征将最终使非线性内核过拟合数据。因此,最好只是坚持一个好的旧线性内核,在这些情况下它往往是表现最好的。
训练:
这些都准备好后,最后唯一要做的就是训练!我们必须使用我们的标签文本集,将它们转换为使用字频率的向量,并将它们送到算法,这将使用我们选择的内核函数,最后它生成一个模型。然后,当我们有一个我们想要分类的新的未标记的文本时,我们将其转换为一个向量,并将其转换为模型,这将输出文本的类别。
总结:
- 支持向量机允许您对可线性分离的数据进行分类。
- 如果它不是线性分离的,你可以使用内核技巧使其工作。
- 然而,对于文本分类,最好只是坚持线性内核。
与较新的算法(如神经网络)相比,它们具有两个主要优点:具有较高速度和更好的性能,数量有限(以千计)。这使得算法非常适合于文本分类问题,其中通常可以访问至多几千个标记样本的数据集。
本文由北邮@爱可可-爱生活推荐,阿里云云栖社区翻译。
文章原标题《An introduction to Support Vector Machines (SVM)》
作者:Bruno Stecanella,机器学习爱好者,译者:袁虎,审阅:李烽 主题曲哥哥
文章为简译,更为详细的内容,请查看原文