postgresql 客户端_PostgreSQL在TPCC场景下的PK
1. 前言
谨以此篇,献给缺少TPCC调优技能包的人,希望看完此篇的pger能掌握一些基本的TPCC调优技能,让PostgreSQL能在越来越多的场景下PK赢其他数据库,创佳绩。2. TPCC简介
2.1. TPCC介绍
TPC-C 是一种衡量 OLTP 系统性能和可伸缩性的基准测试项目。它由一系列的 OLTP 工作流组成,包括查询,更新及队列式小批量事务在内的广泛数据库功能。它模拟了一个典型的 OLTP 应用环境中的活动,这些活动由一系列复杂的事务组成。TPC-C 工作流应该具备以下特性:
1.适当复杂的 OLTP 事务
2.在线和延迟事务执行模型
3.多用户
4.适当的系统和应用执行时间
5.大量的磁盘输入和输出
6.事务完整性(ACID)
7.随机的数据访问
8.数据库由各种大小,属性和关系的表组成
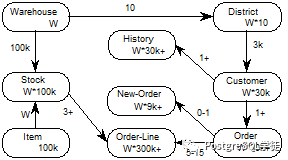
2.2. TPCC E-R 模型
TPC-C 模拟了一个比较有代表意义的 OLTP 应用环境:在线订单处理系统。假设有一个大型商品批发商,拥有 N 个位于不同区域的仓库,每个仓库负责为 10 个销售点供货,每个销售点有 3000 个客户,每个客户平均一个订单有 10 项产品。由于一个仓库中不可能存储公司所有的货物,有一些请求必须发往其它仓库,因此,数据库在逻辑上是分布的。N 是一个可变参数,测试者可以随意改变 N,以获得最佳测试效果。以下为ER模型。
TPC-C 输入数据流
TPC-C 系统需要处理的交易有以下五种:
1.New-Order:客户输入一笔新的订货交易
事务内容:对于任意一个客户端,从固定的仓库随机选取 5-15 件商品,创建新订单。其中 1%的订单要由假想的用户操作失败而回滚。
主要特点:中量级、读写频繁、要求响应快。
2.Payment:更新客户账户余额以反应其支付状况
事务内容:对于任意一个客户端,从固定的仓库随机选取一个辖区及其内用户,采用随机的金额支付一笔订单,并作相应历史纪录。
主要特点:轻量级,读写频繁,要求响应快。
3.Delivery:发货(批处理交易)
事务内容:对于任意一个客户端,随机选取一个发货包,更新被处理订单的用户余额,并把该订单从新订单中删除。
主要特点:1-10 个批量,读写频率低,较宽松的响应时间
4.Order-Status:查询客户最近交易的状态
事务内容:对于任意一个客户端,从固定的仓库随机选取一个辖区及其内用户,读取其最后一条订单,显示订单内每件商品的状态。
主要特点:中量级,只读频率低,要求响应快
5.Stock-Level:查询仓库库存状况,以便能够及时补货。
主要特点:重量级,只读频率低,较宽松的响应时间。
各个类型的交易在系统中所占的比例:
1.New-Order:45%
2.Payment:43%
3.Delivery:4%
4.Order-Status:4%
5.Stock-Level:4%
2.3. TPCC输出指标
TPC-C测试的结果主要有两个指标,即流量指标(Throughput,简称tpmC)和性价比(Price/Performance,简称Price/tpmC)。
1.流量指标(tpmC):描述了系统在执行 Payment,Order-Status,Delivery,Stock-level 这四种交易的同时,每分钟可以处理的New-Order交易的数量。流量指标值越大越好。tpm是 transactions per minute的简称;C指TPC中的C基准程序。它的定义是每分钟内系统处理的新订单个数。要注意的是,在处理新订单的同时,系统还要按上图的要求处理其它4类事务请求。从图1可以看出,新订单请求不可能超出全部事务请求的45%,因此,当一个系统的性能为1000tpmC时,它每分钟实际处理的请求数是2000多个。
2.性价比(Price/Performance,简称Price/tpmc):即测试系统的整体价格与流量指标的比值,在获得相同的tpmC值的情况下,价格越低越好。
3. TPCC测试流程
现在业界主要用BenchmarkSQL5.0来进行测试,4.1.1的版本也有,但现在不多见了。此处下载:https://sourceforge.net/projects/benchmarksql/files/benchmarksql/。
所以本篇以BenchmarkSQL5.0为例。
还需下载PostgreSQL的驱动,然后放入lib目录下,不过解压BenchmarkSQL后默认会有PostgreSQL的驱动:https://jdbc.postgresql.org/download.html。另外还需要下载ant,yum装就行了。装好之后,在此目录下执行一下ant
| -bash-4.2$ cd benchmarksql-5.0/-bash-4.2$ ls -ltotal 36-rwxr-xr-x 1 postgres postgres 1130 May 26 2016 build.xmldrwxr-xr-x 3 postgres postgres 4096 May 26 2016 doc-rwxr-xr-x 1 postgres postgres 6376 May 26 2016 HOW-TO-RUN.txtdrwxr-xr-x 5 postgres postgres 4096 May 26 2016 lib-rwxr-xr-x 1 postgres postgres 5318 May 26 2016 README.mddrwxr-xr-x 7 postgres postgres 4096 May 26 2016 rundrwxr-xr-x 6 postgres postgres 4096 May 26 2016 src-bash-4.2$ pwd/var/lib/pgsql/benchmarksql-5.0-bash-4.2$ antBuildfile: /var/lib/pgsql/benchmarksql-5.0/build.xml init: [mkdir] Created dir: /var/lib/pgsql/benchmarksql-5.0/build compile: [javac] Compiling 11 source files to /var/lib/pgsql/benchmarksql-5.0/build dist: [mkdir] Created dir: /var/lib/pgsql/benchmarksql-5.0/dist [jar] Building jar: /var/lib/pgsql/benchmarksql-5.0/dist/BenchmarkSQL-5.0.jar BUILD SUCCESSFULTotal time: 1 second |
| db=postgresdriver=org.postgresql.Driverconn=jdbc:postgresql://localhost:5432/postgresuser=benchmarksqlpassword=PWbmsql warehouses=1loadWorkers=4 terminals=1//To run specified transactions per terminal- runMins must equal zerorunTxnsPerTerminal=10//To run for specified minutes- runTxnsPerTerminal must equal zerorunMins=0//Number of total transactions per minutelimitTxnsPerMin=300 //Set to true to run in 4.x compatible mode. Set to false to use the//entire configured database evenly.terminalWarehouseFixed=true //The following five values must add up to 100//The default percentages of 45, 43, 4, 4 & 4 match the TPC-C specnewOrderWeight=45paymentWeight=43orderStatusWeight=4deliveryWeight=4stockLevelWeight=4 // Directory name to create for collecting detailed result data.// Comment this out to suppress.resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tSosCollectorScript=./misc/os_collector_linux.pyosCollectorInterval=1//osCollectorSSHAddr=user@dbhostosCollectorDevices=net_eth0 blk_sda |
| postgres=# create user bench_test with password '123456';CREATE ROLEpostgres=# create database benchmarksql owner bench_test;CREATE DATABASE db=postgresdriver=org.postgresql.Driverconn=jdbc:postgresql://localhost:5432/benchmarksqluser=bench_testpassword=123456 warehouses=100loadWorkers=32-bash-4.2$ ./runDatabaseBuild.sh props.pg |
| postgres=# select pg_size_pretty(pg_database_size('benchmarksql')); pg_size_pretty---------------- 10212 MB(1 row) |
| terminals=64runTxnsPerTerminal=0runMins=10limitTxnsPerMin=300 |
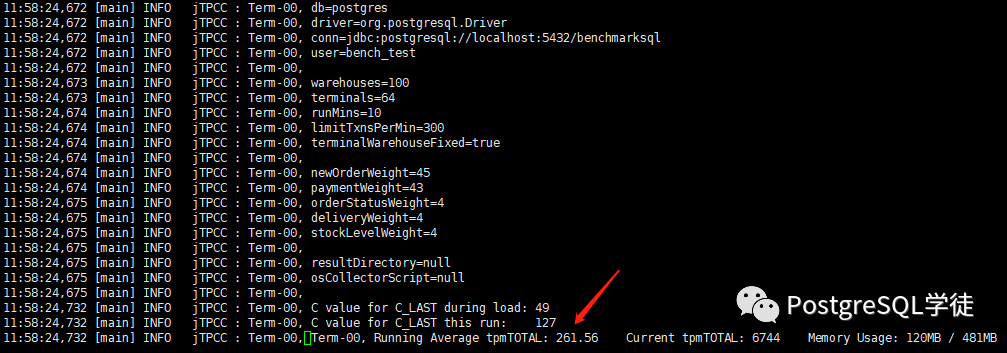
12:08:39,896 [Thread-14] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 111.11 12:08:39,896 [Thread-14] INFO jTPCC : Term-00, Measured tpmTOTAL = 250.13 12:08:39,897 [Thread-14] INFO jTPCC : Term-00, Session Start = 2020-08-01 11:58:24 12:08:39,897 [Thread-14] INFO jTPCC : Term-00, Session End = 2020-08-01 12:08:39 12:08:39,897 [Thread-14] INFO jTPCC : Term-00, Transaction Count = 2563 |
| terminals=64runTxnsPerTerminal=0runMins=10limitTxnsPerMin=3000 |
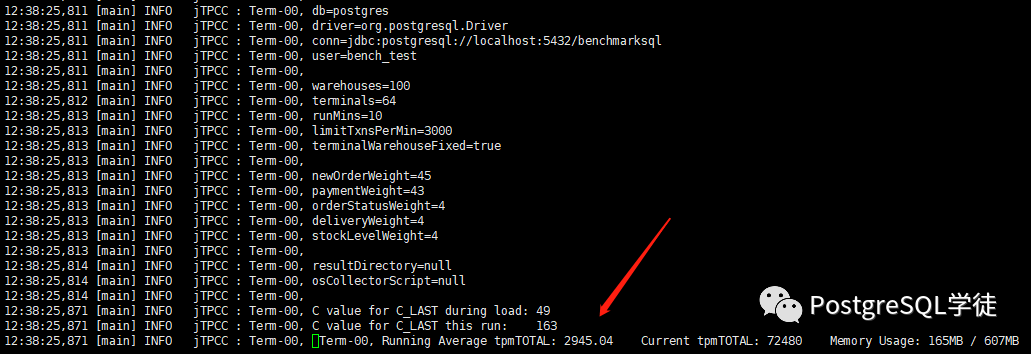
12:21:08,962 [Thread-16] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 1330.08 12:21:08,962 [Thread-16] INFO jTPCC : Term-00, Measured tpmTOTAL = 2939.3 12:21:08,962 [Thread-16] INFO jTPCC : Term-00, Session Start = 2020-08-01 12:11:06 12:21:08,962 [Thread-16] INFO jTPCC : Term-00, Session End = 2020-08-01 12:21:08 12:21:08,962 [Thread-16] INFO jTPCC : Term-00, Transaction Count = 29514 |
| terminals=64runTxnsPerTerminal=0runMins=10limitTxnsPerMin=50000 |
| 12:54:04,465 [Thread-40] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 10140.68 12:54:04,465 [Thread-40] INFO jTPCC : Term-00, Measured tpmTOTAL = 22510.6312:54:04,465 [Thread-40] INFO jTPCC : Term-00, Session Start = 2020-08-01 12:44:0412:54:04,465 [Thread-40] INFO jTPCC : Term-00, Session End = 2020-08-01 12:54:0412:54:04,465 [Thread-40] INFO jTPCC : Term-00, Transaction Count = 225159 |
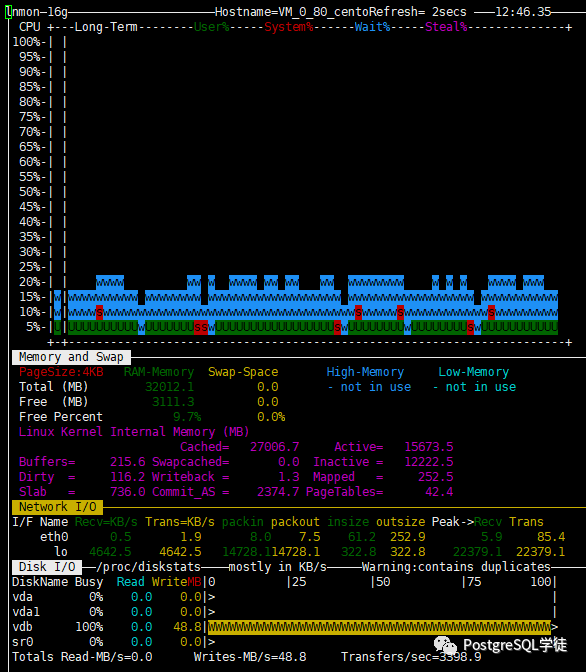
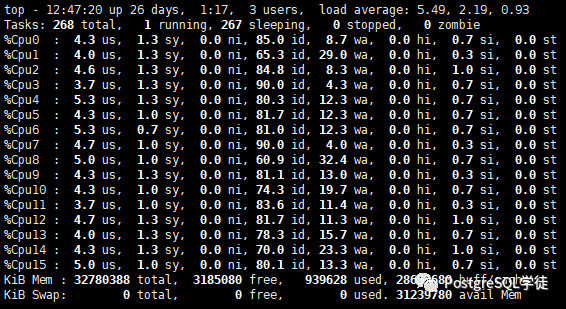
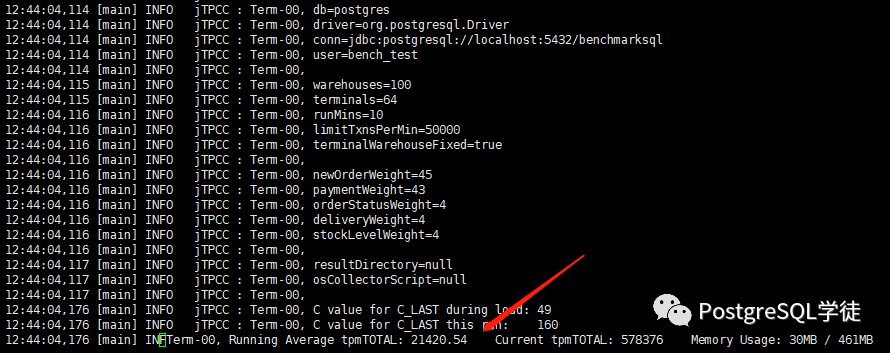
| terminals=64runTxnsPerTerminal=100runMins=0limitTxnsPerMin=50000 |
12:59:15,658 [Thread-46] INFO jTPCC : Term-00, 684 Memory Usage: 137MB / 607MB 12:59:15,658 [Thread-46] INFO jTPCC : Term-00, 12:59:15,658 [Thread-46] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 9723.3 12:59:15,659 [Thread-46] INFO jTPCC : Term-00, Measured tpmTOTAL = 21731.45 12:59:15,659 [Thread-46] INFO jTPCC : Term-00, Session Start = 2020-08-01 12:58:57 12:59:15,659 [Thread-46] INFO jTPCC : Term-00, Session End = 2020-08-01 12:59:15 12:59:15,659 [Thread-46] INFO jTPCC : Term-00, Transaction Count = 6400 |
4. TPCC调优
4.1. 数据库
4.1.1. IO调优
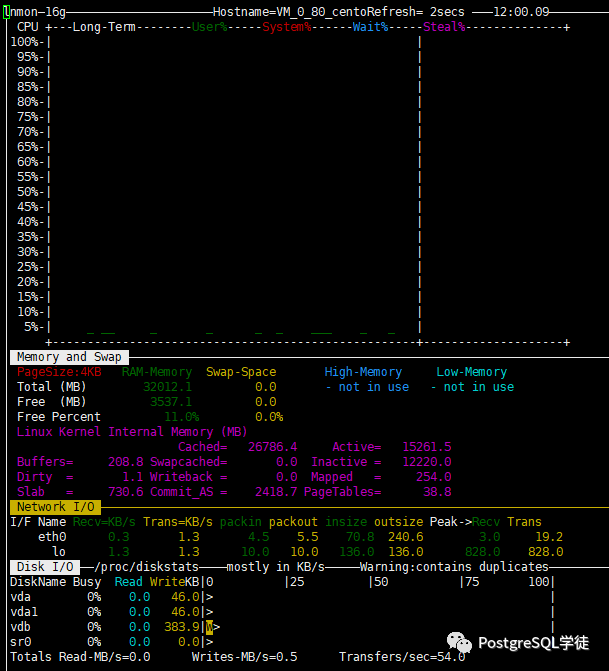
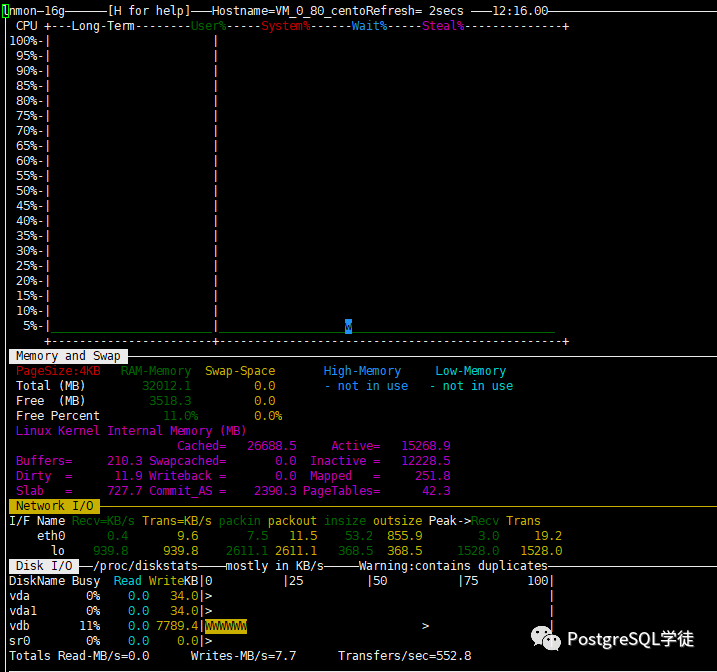
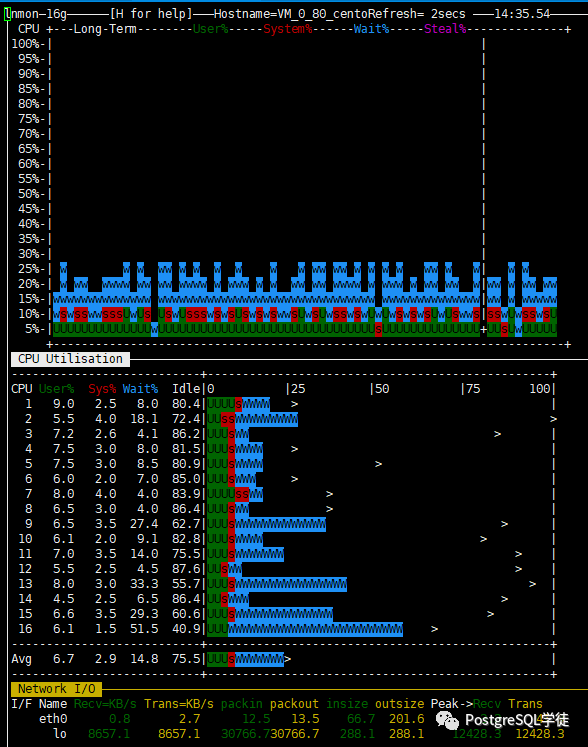
首先玩数据库的,就得懂数据库的各个参数,对症下药。前面也看到了,大量的iowait,说明磁盘比较挫,此处用 hdparm 简单测一下, 这个工具 有误差, 只是大概测一下,但也够用了,心里有个数,毕竟 比不上专业的测试工具如fio 。| [root@VM_0_80_centos data]# hdparm -tT --direct /dev/vdb /dev/vdb: Timing O_DIRECT cached reads: 274 MB in 2.06 seconds = 133.19 MB/sec Timing O_DIRECT disk reads: 376 MB in 3.00 seconds = 125.32 MB/sec |
checkpoint_timeout# 系统自动执行checkpoint之间的最大时间间隔。系统默认值是5分钟,这个值可以在压测过程中调大,尽量避免执行checkpoint争抢IO max_wal_size# 写满多少个WAL时执行checkpoint,也是同理,这个值可以在压测过程中调大,尽量避免执行checkpoint争抢IO min_wal_size# 只要wal日志目录使用空间小于该值,那么旧的wal日志就会循环使用而不是进行删除。这个参数是为了确保足够的wal空间预留给突发情况,比如大的跑批操作。 checkpoint_completion_target# 分散检查点,默认为0.5,即表示每个checkpoint需要在checkpoints间隔时间的50%内完成,然后立马进行fsync,fsync执行是很快的(为了平滑fsync,以防尖锐的IO请求,PostgreSQL9.6以后加了checkpoint_flush_after、wal_writer_flush_after、bgwriter_flush_after和backend_flush_after这些参数来缓解)看如下一个场景。
|
| bgwriter_delay# background writer每次扫描之间的时间间隔,也就是刷shared buffer脏页的进程调度间隔,尽量高频调度,减少用户进程申请不到内存而需要主动刷脏页的可能(导致RT升高) bgwriter_lru_maxpages# 一次最多刷多少脏页 bgwriter_lru_multiplier# 写出至多bgwriter_lru_multiplier * N个脏页,并且不超过bgwriter_lru_maxpages值的限制。其中N是最近一段时间在两次BgWriter运行期间系统新申请的缓冲区页数。后台写进程根据最近服务进程需要的buffer数量乘上这个比率估算出下次服务进程需要的buffer数量,再使用后台写进程刷脏页面,使缓冲区能使用的干净页面达到这个估计值 bgwriter_flush_after# 每当bgwriter写入的字节数超过bgwriter_flush_after时,就会强制OS从page cache中写出。这样做将限制page cache中脏数据量,从而减少在检查点末尾发出fsync或操作系统在后台大批量写回数据时出现停顿的可能性 |
| autovacuum# 自动清理进程,在压测期间,可以关闭,减少IO争抢 vacuum_cost_limit、vacuum_cost_delay# 在vacuum和analyze命令的执行过程中,系统维护着一个内部计数器来跟踪各种被执行的I/O操作的估算开销。当累计的代价达到一个阈值vacuum_cost_limit,执行这些操作的进程将按照vacuum_cost_delay所指定的休眠一小段时间。然后它将重置计数器并继续执行,这些代价则由vacuum_cost_page_hit、vacuum_cost_page_miss和vacuum_cost_page_dirty指定,在压测期间关闭autovacuum就好了,对于一般场景下vacuum的调优就太多了,此处不多说。 |
| fsync# 关闭fsync。本该持久化同步写的(例如checkpoint,wal write)变成了异步,可能丢数据,同时会导致数据库的数据不一致,极度危险。任何时候都不建议关闭fsync,假如为了追求极限,并且能确保数据库不出现问题,那就关掉吧 |
| synchronous_commit# synchronous_commit参数默认为ON,表示事务提交为同步方式。事务提交时,对应的XLOG日志必须马上刷新回磁盘事务才能返回成功,synchronous_commit参数为OFF,则为异步方式。事务提交时,立刻返回用户成功,同时更新asyncXactLSN。关闭synchronous_commit。数据库崩溃时不会导致数据丢失。仅当操作系统崩溃时才会有数据丢失的风险,风险多大取决于以下参数。wal_writer_delay=10ms # 每隔 10 ms ,主动持久化wal buffer到DISK(持久化存储)、wal_writer_flush_after=1MB # 每隔1MB WAL,主动持久化wal buffer到DISK(持久化存储)以上设置,操作系统崩溃时数据库最多丢30ms (wal_writer_delay * 3)日志。但是不会导致数据库状态不一致(事务原子性、事务先后),可以确保没有提交的事务被完全回滚、已提交的事务保证完整。另外需要注意的是,不管synchronous_commit为何值,所有的对数据块的变更操作在write到磁盘前,一定是确保这个变更产生的REDO会先写到XLOG,并保证XLOG已落盘。对于我这么挫的磁盘,关闭这个参数应该可以提升不少 |
| # Add settings for extensions heresynchronous_commit=offcheckpoint_timeout=30mincheckpoint_completion_target=0.9max_wal_size=64GBmin_wal_size=8GBautovacuum=offfull_page_writes=onbgwriter_delay=10msbgwriter_lru_maxpages = 1000bgwriter_lru_multiplier = 10.0 |
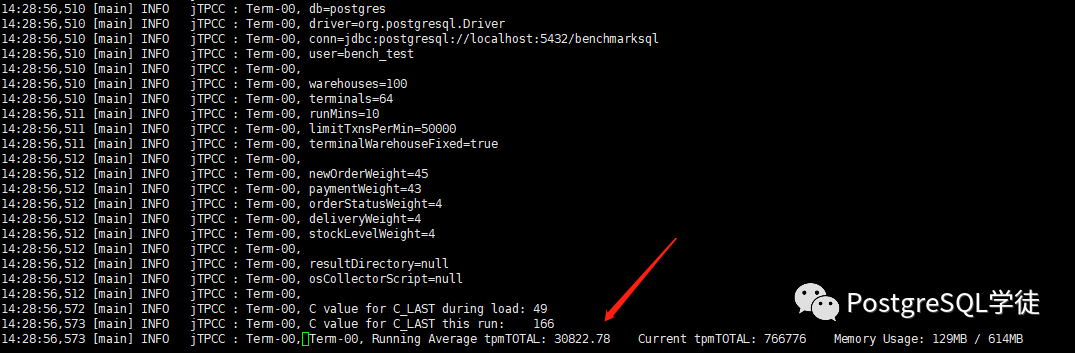
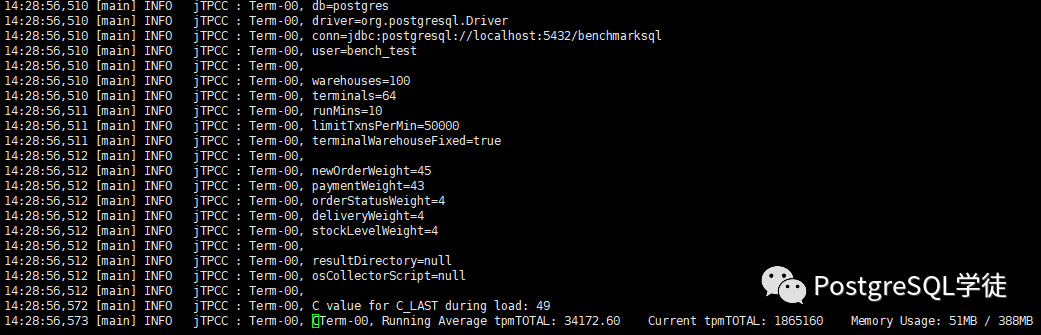
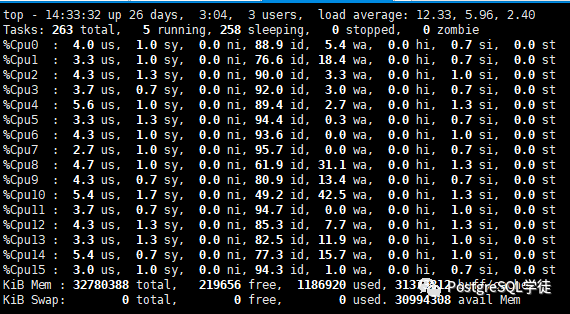
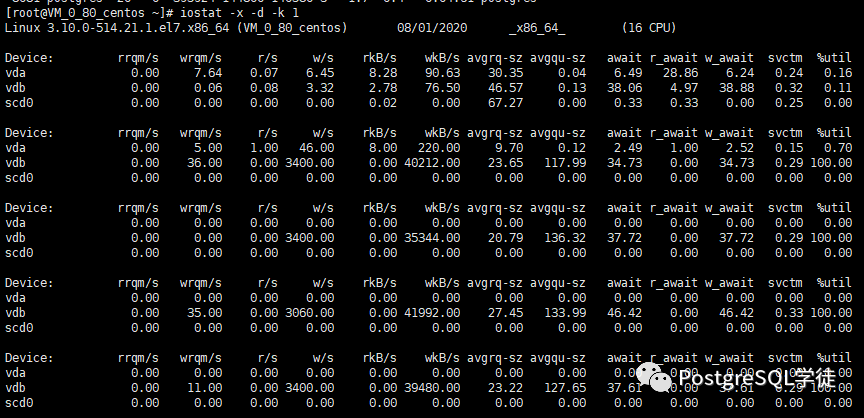
14:38:56,857 [Thread-41] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 15803.6 14:38:56,857 [Thread-41] INFO jTPCC : Term-00, Measured tpmTOTAL = 35178.32 14:38:56,857 [Thread-41] INFO jTPCC : Term-00, Session Start = 2020-08-01 14:28:56 14:38:56,857 [Thread-41] INFO jTPCC : Term-00, Session End = 2020-08-01 14:38:56 14:38:56,857 [Thread-41] INFO jTPCC : Term-00, Transaction Count = 351869 |
4.1.2. 内存调优
好在调整 PostgreSQL的内存参数不多,我们最主要调的就是shared_buffers| shared_buffers# shared_buffers在普通场景下建议设置为内存的25%,不超过40%;在TPCC的场景下尽可能设大一点,减少双缓存的影响。根据warehouse数量及内存进行调整,调整原则尽量将数据都放入内存中,尽量使用数据库的内存,减少双缓存的影响。1个warehouse 100MB,1000的话就是100GB,那么shared_buffers可以设置尽可能大,比如90、100GB都是可以的。 |
| work_mem# min 64kB,减少外部文件排序的可能,提高效率,注意work_mem一般设置8MB就足够大了,800GB的服务器假如在平均300+ 连接下,work_mem = 32MB很快就会导致内存溢出,数据库进程被kill,此处设置为16MB仅是针对TPCC场景,可以根据实际环境调低一点。 maintenance_work_mem# 加速建立索引,一般可以按每1GB内存设置为50MB来设置 effective_cache_size# 可用的OS cache + 数据库的cache,值越大,越倾向于走索引扫描。对于专门的数据库服务器,可以设置为100%的内存,系统并不会根据这个值来真实地分配那么多内存,但是规划器会根据这个值来判断系统能否提供查询执行过程中所需的内存。 huge_page# Linux中,内存页默认是4k。当内存很大时,如果页很小,整体性能就会变差。PostgreSQL中只支持Linux的HugePage(在BSD中有Super Page,在Window中有Large Page)。启用了huge_pages后,相应的内存页表就会变小,进而会提高内存管理的性能。使用大页面会减少开销,特别是当我们配置了比较大的shared_buffer的时候。简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销 |
| # Add settings for extensions heresynchronous_commit=offcheckpoint_timeout=30mincheckpoint_completion_target=0.9max_wal_size=64GBmin_wal_size=8GBautovacuum=offfull_page_writes=onbgwriter_delay=10msbgwriter_lru_maxpages = 1000bgwriter_lru_multiplier = 10.0shared_buffers=16GBwork_mem=16MBmaintenance_work_mem=1GBeffective_cache_size=25GB#huge_pages=on此处huge_pages设为on会报错,我的服务器内存不够了 |
15:05:02,569 [Thread-52] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 22656.34 15:05:02,570 [Thread-52] INFO jTPCC : Term-00, Measured tpmTOTAL = 50455.8 15:05:02,570 [Thread-52] INFO jTPCC : Term-00, Session Start = 2020-08-01 14:55:02 15:05:02,570 [Thread-52] INFO jTPCC : Term-00, Session End = 2020-08-01 15:05:02 15:05:02,570 [Thread-52] INFO jTPCC : Term-00, Transaction Count = 504663 |
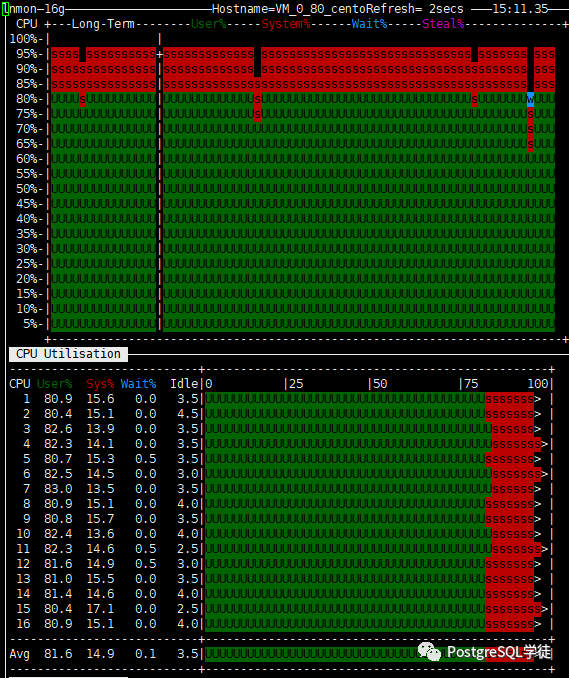
15:17:47,317 [Thread-56] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 180732.76 15:17:47,317 [Thread-56] INFO jTPCC : Term-00, Measured tpmTOTAL = 401612.19 15:17:47,317 [Thread-56] INFO jTPCC : Term-00, Session Start = 2020-08-01 15:07:47 15:17:47,317 [Thread-56] INFO jTPCC : Term-00, Session End = 2020-08-01 15:17:47 15:17:47,317 [Thread-56] INFO jTPCC : Term-00, Transaction Count = 4016295 |
4.2. 硬件
既然数据库层面这么多调优的地方,那服务器层面肯定也有很多调优的地方了。光调调数据库就可以提升那么多,那么调一下硬件岂不是还可以更快?实操一下。4.2.1. 使用大页
在Linux中,内存页默认是4k。当内存很大时,如果页很小,整体性能就会变差。PostgreSQL中只支持Linux的HugePage(在BSD中有Super Page,在Window中有Large Page)。启用了huge_pages后,相应的内存页表就会变小,进而会提高内存管理的性能。使用大页面会减少开销,特别是当我们配置了比较大的shared_buffer的时候。简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销! Linux的HugePage大小从2MB到1Gb不等;默认是2MB,大小在系统启动的时候设置。 基于如下脚本的运行结果,我们可以设置配置相应的HugePage的大小。 #!/bin/bash PGDATA="/var/lib/pgsql/12/data" pid=`head -1 $PGDATA/postmaster.pid` echo "Pid: $pid" peak=`grep ^VmPeak /proc/$pid/status | awk '{ print $2 }'` echo "VmPeak: $peak kB" hps=`grep ^Hugepagesize /proc/meminfo | awk '{ print $2 }'` echo "Hugepagesize: $hps kB" hp=$((peak/hps)) echo Set Huge Pages: $hp sysctl -w vm.nr_hugepages= $hp 这种配置一般针对于数据库服务器,就是只跑了个PostgreSQL,如果还有其他应用程序也需要大页,则需要合理设置。 |
4.2.2. 禁用NUMA
SMP 是Symmetric Multi-Processing的意思,对称多处理器,一种多核结构,认为这些核是完全同构的,任务可以随便在任一个核上跑。 UMA是Uniform Memory Access,统一内存访问,是指所有处理器一致的共享全部物理内存。 NUMA是Non-Uniform Memory Access的意思,非统一内存访问,指处理器访问物理内存的时间依赖于该内存所在的物理位置。即在多处理器架构下,CPU访问共享内存的时间要比访问本地内存所需的时间长的多。 NUMA是一种CPU的硬件架构。NUMA相对的是SMP,SMP中所有CPU争用一个总线来访问内存;而NUMA称作非对称性内存访问:简单来说是,每个CPU有自己的Memory Zone内存空间,访问自己的很快,访问别人的慢。 NUMA的内存分配策略默认是localalloc(还有preferred、membind、interleave),即从本地node分配,如果本地node分配不了,根据系统参数:vm.zone_reclaim_mode,决定是否从其他node分配内存: 取0,系统倾向于从其他node分配内存 取1,系统倾向于从本地节点回收Cache 当系统中有多个Node,且zone_reclaim_mode=1时;可能内存不能完全利用起来,如果你对内存的使用,更偏向于cache的应用而不是数据局部性的应用,那么建议取0; 在PostgreSQL中,我们通常取0,并且会在bios中将numa关闭: grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="numa=off" |
4.2.3. 关闭透明大页
透明大页允许大页(Huge Page)做动态的分配,而不是系统启动后就分配好。透明大页在有些应用场景会出现异常,运行时动态分配内存,而运行时的内存分配会有延误,系统也会在你不执行的情况下,将4kb的page换成大页,可能会导致数据库崩溃等不可控的错误。根据Oracle MOS DOC:1557478.1,透明大页导致了很多的问题,而且会导致意外的节点重启并导致RAC出现性能问题。建议关闭,Oracle、Mongodb、Redis等服务都建议关闭这个特性。 查看透明大页的系统配置命令如下: [xiongcancan@localhost data]$ cat /sys/kernel/mm/transparent_hugepage/enabled [always] madvise never 上面中括号包围的值就是当前值,关闭透明大页的方法如下: [root@localhost ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled [root@localhost ~]# cat /sys/kernel/mm/transparent_hugepage/enabled always madvise [never] 永久禁用透明大页可以通过编辑/etc/ec.local,加入如下: if test -f /sys/kernel/mm/transparent_hugepage/enabled;then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag;then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi |
| [root@VM_0_80_centos ~]# cat /sys/kernel/mm/transparent_hugepage/enabled[always] madvise never[root@VM_0_80_centos ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled[root@VM_0_80_centos ~]# cat /sys/kernel/mm/transparent_hugepage/enabledalways madvise [never] |
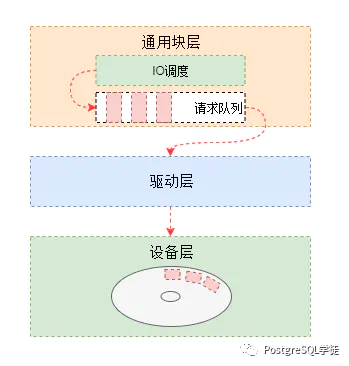
4.2.4. 调整磁盘IO调度策略为deadline
除了硬盘能力好坏,IO的调度策略也有影响,Linux的IO调度器称为evelator(电梯),坐过电梯都知道,电梯的算法是:电梯总是从一个方向,把人送到有需要的最高的位置,然后反过来,把人送到有需要的最低一个位置。这样效率是最高的,因为电梯不用根据先后顺序,不断调整方向,走更多的冤枉路。主要分为3种 1) noop实现了一个简单的fifo队列,它像电梯的工作主法一样对i/o请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质,noop倾向饿死读而利于写,noop对于闪存设备,ram,嵌入式系统是最好的选择。大白话来说就叫no operation,就是不调度的算法,有什么请求都直接写下去。这通常用于两种情形:你的磁盘是比如SSD那样的内存存储设备,根本不需要调度,往下写就对了。第二种情形是你的磁盘比较高级,自带调度器,OS不需要自作聪明,有什么请求直接往下扔就好了。这两种情况就应该选noop算法。 2) cfq是默认的调度策略,顾名思义,绝对公平算法,completely fair queuing,它是一个复杂的调度策略,按进程创建多个队列,试图保持对多个进程的公平,cfq试图均匀地分布对i/o带宽的访问,避免进程被饿死并实现较低的延迟。 3) deadine核心在于保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。deadline是一个改良的电梯算法,基本上和电梯算法一样,但加了一条,如果部分请求等太久了(deadline到了,默认读请求500ms,写请求5s),电梯就要立即给我掉头,先处理这个请求。
PostgreSQL种建议使用deadline。 查看当前I/O调度策略 cat /sys/block/{DEVICE-NAME}/queue/scheduler 临时修改 echo deadline > /sys/block/{DEVICE-NAME}/queue/scheduler 永久修改 vim /rc.d/rc.local echo deadline > /sys/block/{DEVICE-NAME}/queue/scheduler |
| [root@VM_0_80_centos ~]# cat /sys/block/vdb/queue/schedulernone[root@VM_0_80_centos ~]# echo deadline > /sys/block/vdb/queue/scheduler[root@VM_0_80_centos ~]# cat /sys/block/vdb/queue/schedulerdeadline |
4.2.5. 块设备预读
blockdev --setra 16384 /dev/dfa blockdev --setra 16384 /dev/dfb blockdev --setra 16384 /dev/dfc blockdev --setra 16384 /dev/dm-0 |
4.2.6. 内核参数
上面的调整完了之后,再调整一下内核参数,根据实际情况来调1、/etc/sysctl.conf kernel.shmmax # 最大单个共享内存段大小 (建议为内存一半), >9.2的版本已大幅降低共享内存的使用,单位为字节。 kernel.shmmni # 一共能生成多少共享内存段,每个PostgreSQL数据库集群至少2个共享内存段 kernel.shmall # 所有共享内存段相加大小限制 (建议内存的80%),单位为页。 fs.file-max # 系统级别的能够打开的文件句柄的数量 fs.aio-max-nr # 此参数限制并发未完成的异步请求数目 vm.swappiness # 交换分区 net.core.rmem_max # The maximum receive socket buffer size in bytes net.core.wmem_max # The maximum send socket buffer size in bytes. net.core.rmem_default # The default setting of the socket receive buffer in bytes. net.core.wmem_default # The default setting (in bytes) of the socket send buffer. net.ipv4.ip_local_port_range # 本地自动分配的TCP UDP端口号范围 kernel.sem # 信号量 vm.dirty_background_ratio/vm.dirty_background_bytes # 内存中允许存在的脏页比率或者具体值。达到该值,后台刷盘。取决于外存读写速度的不同,通常将vm.dirty_background_ratio设置为5,而vm.dirty_background_bytes设置为读写速度的25%。 vm.dirty_ratio/vm.dirty_bytes # 用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。前台刷盘会阻塞读写,一般vm.dirty_ratio设置的比vm.dirty_background_ratio大,设置该值确保系统不会再内存中保留过多数据,避免丢失。 vm.dirty_expire_centisecs # 脏页在内存中保留的最大时间。 vm.dirty_writeback_centisecs # 刷盘进程(pdflush/flush/kdmflush)周期性启动的时间 2、/etc/security/limits.conf postgres hard nofile 65536 postgres soft nofile 65536 # 修改数据库属主用户单个进程能够打开的最大文件句柄数量(socket连接也算在里面) postgres soft nproc 65536 postgres hard nproc 65536 # 修改数据库用户的最大processes数量 postgres soft core ulimited postgres hard core ulimited # 修改数据库用户生成core文件的限制大小 |
| 16:19:48,117 [Thread-47] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 193150.8416:19:48,117 [Thread-47] INFO jTPCC : Term-00, Measured tpmTOTAL = 428785.7516:19:48,117 [Thread-47] INFO jTPCC : Term-00, Session Start = 2020-08-01 16:14:4716:19:48,117 [Thread-47] INFO jTPCC : Term-00, Session End = 2020-08-01 16:19:4816:19:48,118 [Thread-47] INFO jTPCC : Term-00, Transaction Count = 2144964 |
4.3. 其他调优手段
其他调优手段就不算常规的了,比如: 1、 使用pg_prewarm和pg_fincore提前将数据进行预热,缓存在shared_buffers中或者page cache中; 2、 提前扩好某些表,因为extend block会使用到exclusive lock; 3、 内核层面,可以优化LWLock,比如 向wal buffer中写wal record需要竞争的锁,如果把synchronous_commit关闭,这个锁的竞争会更加激烈;还有分区锁,默认128 4、 Blocksize设为32K,某一程度上减少可能的IO密集,以及频繁的extend block 5、 调整表的fillfactor,利用起HOT,减少IO 6、 网卡绑定、进程绑定等(在鲲鹏服务器上会有不错的提升) 7、 假如有多的盘,可以设置temp_tablespace等来分盘,将临时数据分开至不同盘上 8、 ... 所以可以看到,调优的手段多种多样,如何把NewOrders调到更高才是我们的最终目的。5. 结尾
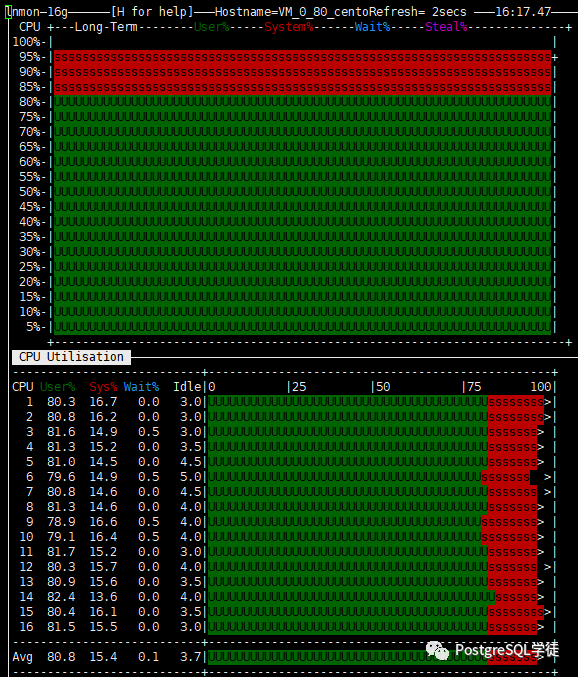
写了将近一万字, 肝了两天, 估计各位看官老爷也看累了,初衷还是 为了 看了 此篇 能有所收获, 从 最开始NewOrders = 200 ,一步步调优至 接近20W, 本身TPCC调优和压测就是一件循环往复的事情。 之所以分享出来,不仅仅是希望更多的人能学会TPCC调优,自己也从头到尾温故了一遍,温故而知新。 唠句题外话,昨晚测试的时候,发现CPU利用率始终100%,BenchmarkSQL都还没压呢就100%了,一看原来是中病毒了,挨了个挖矿病毒,所以 对于服务器 设一个复杂点的密码和安全组也至关重要啊!