正则表达式之egrep实战示例
基本正则表达式在egrep中的实战使用
那什么是基本正则表达式是什么呢?
其实呢,他就是一个语法啦!表达式么,就是表达自己需要的内容,让计算机去匹配你表达出内容的相关数据。这样描述很好理解吧.哈哈。
那基本正则表达式能为我们做点什么呢?
它可是很强大的东西,结合egrep使用能快速精准定位文件中你检索的内容。下面我会为大家娓娓道来。
首先,正则表达式中分为元字符和正常字符。
元字符:就是带特技的字符,用于表达控制和通配等功能,不是很好懂诶 那就待会结合实例来认识喽!
正常字符:这个就好理解了,顾名思义。自己猜吧
基本正则表达式元字符(注:这个是要死死记住的东西 要不没法组织语法)
下面先介绍字符匹配
“.”:看到了吗?就中间那个点,美式键盘的句号键, 它可以替代任何单个字符,注:是单个字符

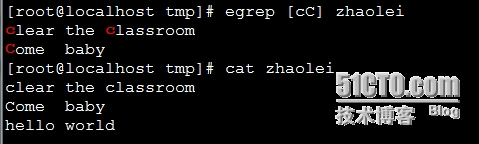{kind=link}

[^]:匹配非[^]内的任意字符

还可以这样取值
[0-9]同时可以这样[[:digit:]]表示取反就是[^0-9]或者[^[:digit]]

[a-z] 或者这样表达[[:lower:]]意思是一样的。

这样 [A-Z], 或者这样 [[:upper:]]

[[space:]]:空格

[[:punct;]]:标点

[0-9a-zA-Z] 或[[:alnum;]] :数字和字母

[a-zA-Z]或[[:alpha:]] :所有字母

以上是字符匹配 以下进入次数匹配 (注:前方高能)
次数匹配是对需要匹配字符后面提供的控制符,对控制符前字符生效,用于表达前面字符指定的次数。
* :任意长度,表示0次、1次或者多次:

.*:注意看*前面有个点,任意长度的任意字符

\?:0次或者1次:表示其左侧字符可有可无

\+:一次或多次;表示左侧字符至少出现一次

{n}:n次;表示其左侧字符精确出现n次 看不懂看示例

{m,n}:左侧m代表次数下限,至少m次;右侧n代表上限,至多n次 注意需要“”来引用了 看示例

需要注意的是 如果是只设上限左侧只需为0,但是如果只设下限的话是这样表达{m,}。

下面来讲位置锚定
^:锚定行首,白话就是告诉计算机 你要找的东西是在行首。万恶的专业术词 哈哈
$:锚定行尾
锚定单词:指非特殊字符如(!@#¥%……&*)……巴拉巴拉 你懂的啦!组成的连续字符串
这里用/etc/passwrod文件做示例
\<或者 \b:锚定词首,
\>或者\b:锚定词尾,


分组:()
分组模式中匹配的字符会被grep记忆,保存的记忆顺序是\1代表第一个()的值,\2代表第二个()取的值,可以通过\1、\2……来引用前面保存的值 看示例

转载于:https://blog.51cto.com/zha0lei/1627477