一、进程:
Python的os模块封装了常见的系统调用,其中就包括fork。而fork是linux常用的产生子进程的方法,简言之是一个调用,两个返回。
在python中,以下的两个模块用于进程的使用。详细就不展开。
multiprocessing:跨平台版本的多进程模块。
Pool:进程池
Queue、Pipes:进程通信
二、线程:
严格意义上,python的多线程属于伪多线程,因为受限于GIL,python的多线程每次只能执行一个,按流水线方式执行所有任务。
threading:高级创建线程模块
threading.Lock(): lock.acquire()获取 lock.release()释放
三、ThreadLocal
定义全局变量,每个thread对他都有读写操作,但是该全局变量的属性值是每个thread的局部变量,不同thread中的局部变量不能互相修改。
计算密集型 vs. IO密集型
受限于GIL,python的多线程属于伪线程,即是每个cpu一次只能执行一个线程。
计算密集型:多进程
IO密集型:多线程,比如爬虫,时间多花费在io操作上
四、分布式进程
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。
服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
# taskmanager.py import random, time, Queue from multiprocessing.managers import BaseManager # 发送任务的队列: task_queue = Queue.Queue() # 接收结果的队列: result_queue = Queue.Queue() # 从BaseManager继承的QueueManager: class QueueManager(BaseManager): pass # 把两个Queue都注册到网络上, callable参数关联了Queue对象: QueueManager.register('get_task_queue', callable=lambda: task_queue) QueueManager.register('get_result_queue', callable=lambda: result_queue) # 绑定端口5000, 设置验证码'abc': manager = QueueManager(address=('', 5000), authkey='abc') # 启动Queue: manager.start() # 获得通过网络访问的Queue对象: task = manager.get_task_queue() result = manager.get_result_queue() # 放几个任务进去: for i in range(10): n = random.randint(0, 10000) print('Put task %d...' % n) task.put(n) # 从result队列读取结果: print('Try get results...') for i in range(10): r = result.get(timeout=10) print('Result: %s' % r) # 关闭: manager.shutdown()
本机上启动或另一台机子上启动:
# taskworker.py import time, sys, Queue from multiprocessing.managers import BaseManager # 创建类似的QueueManager: class QueueManager(BaseManager): pass # 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字: QueueManager.register('get_task_queue') QueueManager.register('get_result_queue') # 连接到服务器,也就是运行taskmanager.py的机器: server_addr = '127.0.0.1' print('Connect to server %s...' % server_addr) # 端口和验证码注意保持与taskmanager.py设置的完全一致: m = QueueManager(address=(server_addr, 5000), authkey='abc') # 从网络连接: m.connect() # 获取Queue的对象: task = m.get_task_queue() result = m.get_result_queue() # 从task队列取任务,并把结果写入result队列: for i in range(10): try: n = task.get(timeout=1) print('run task %d * %d...' % (n, n)) r = '%d * %d = %d' % (n, n, n*n) time.sleep(1) result.put(r) except Queue.Empty: print('task queue is empty.') # 处理结束: print('worker exit.')
工作如图:
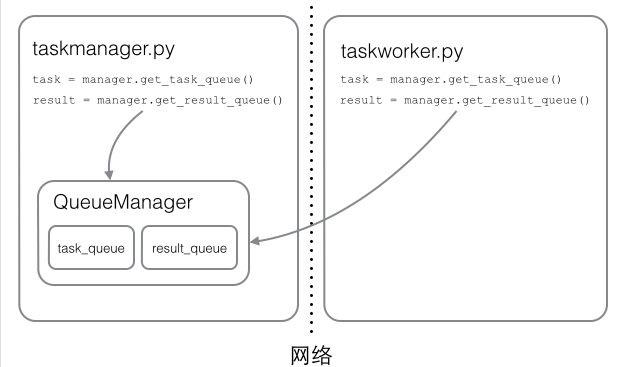
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件。
四、协程
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
第一最大的优势就是协程极高的执行效率。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
import time def consumer(): r = '' while True: n = yield r ## if not n: return print('[CONSUMER] Consuming %s...' % n) time.sleep(1) r = '200 OK' def produce(c): c.next() ##执行一次生成 n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) ##传给consumer,转进consumer的yield里面 print('[PRODUCER] Consumer return: %s' % r) c.close() if __name__=='__main__': c = consumer() ##生成器 produce(c)
[PRODUCER] Producing 1... [CONSUMER] Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 2... [CONSUMER] Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 3... [CONSUMER] Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 4... [CONSUMER] Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 5... [CONSUMER] Consuming 5... [PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
-
首先调用c.next()启动生成器;
-
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
-
consumer通过yield拿到消息,处理,又通过yield把结果传回;
-
produce拿到consumer处理的结果,继续生产下一条消息;
-
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。