stream distinct去重_会了这些 Stream 操作,再学 Flink 真的简单的不得了
点击上方“zhisheng”,选择“设为星标”
做积极的人,而不是积极废人

作者:坚持就是胜利
juejin.im/post/5d5e2616f265da03b638b28a
简介
java8也出来好久了,接口默认方法,lambda表达式,函数式接口,Date API等特性还是有必要去了解一下。比如在项目中经常用到集合,遍历集合可以试下lambda表达式,经常还要对集合进行过滤和排序,Stream就派上用场了。用习惯了,不得不说真的很好用。
Stream作为java8的新特性,基于lambda表达式,是对集合对象功能的增强,它专注于对集合对象进行各种高效、便利的聚合操作或者大批量的数据操作,提高了编程效率和代码可读性。
Stream的原理:将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上处理,包括过滤筛选、去重、排序、聚合等。元素流在管道中经过中间操作的处理,最后由最终操作得到前面处理的结果。
集合有两种方式生成流:
stream() − 为集合创建串行流
parallelStream() - 为集合创建并行流
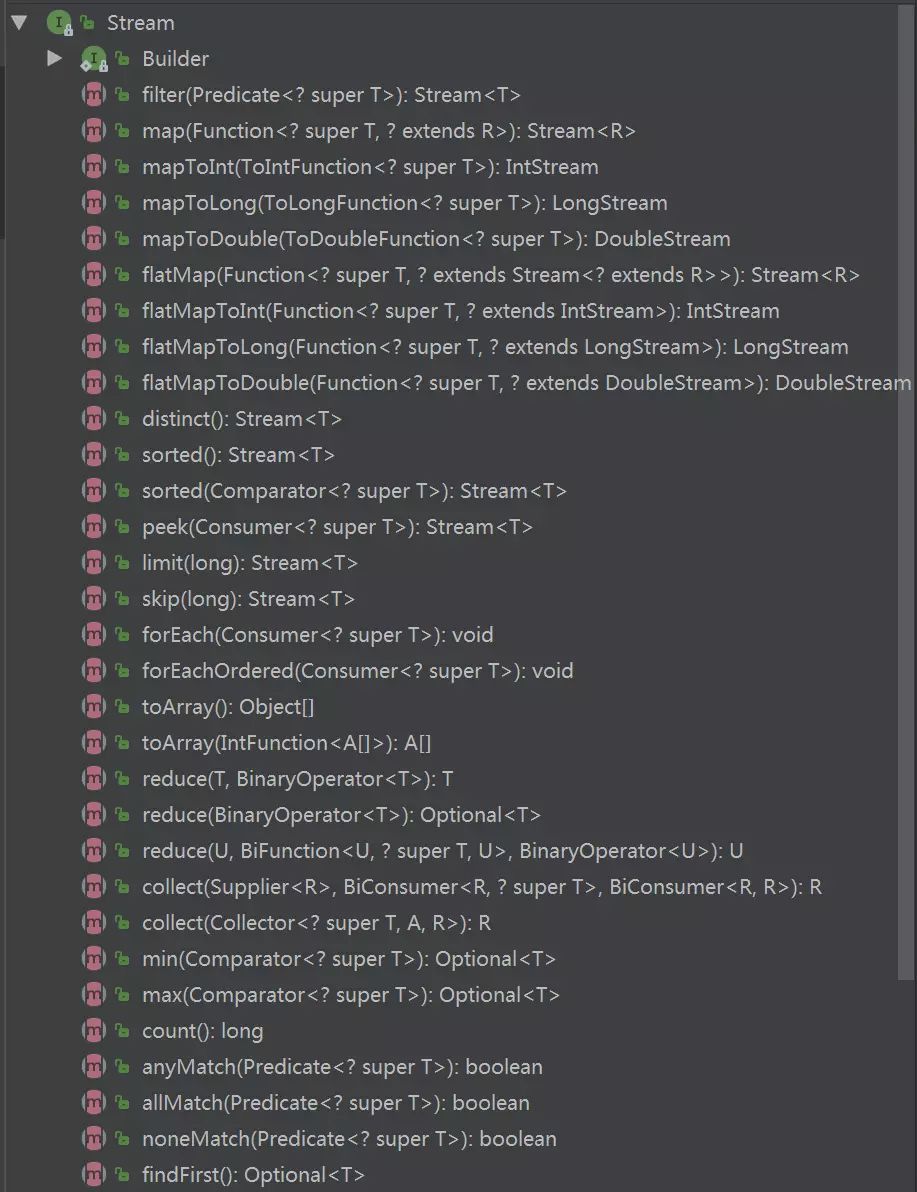
上图中是Stream类的类结构图,里面包含了大部分的中间和终止操作。
中间操作主要有以下方法(此类型方法返回的都是Stream):map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
终止操作主要有以下方法:forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
举例说明
首先为了说明Stream对对象集合的操作,新建一个Student类(学生类),覆写了equals()和hashCode()方法
public class Student {
private Long id;
private String name;
private int age;
private String address;
public Student() {}
public Student(Long id, String name, int age, String address) {
this.id = id;
this.name = name;
this.age = age;
this.address = address;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(id, student.id) &&
Objects.equals(name, student.name) &&
Objects.equals(address, student.address);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age, address);
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}
filter(筛选)
public static void main(String [] args) {
Student s1 = new Student(1L, "肖战", 15, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);List streamStudents = testFilter(students);
streamStudents.forEach(System.out::println);
}/**
* 集合的筛选
* @param students
* @return
*/private static List testFilter(List students) {//筛选年龄大于15岁的学生// return students.stream().filter(s -> s.getAge()>15).collect(Collectors.toList());//筛选住在浙江省的学生return students.stream().filter(s ->"浙江".equals(s.getAddress())).collect(Collectors.toList());
}运行结果:

这里我们创建了四个学生,经过filter的筛选,筛选出地址是浙江的学生集合。
map(转换)
public static void main(String [] args) {
Student s1 = new Student(1L, "肖战", 15, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
testMap(students);
}/**
* 集合转换
* @param students
* @return
*/private static void testMap(List students) {//在地址前面加上部分信息,只获取地址输出
List addresses = students.stream().map(s ->"住址:"+s.getAddress()).collect(Collectors.toList());
addresses.forEach(a ->System.out.println(a));
}运行结果

map就是将对应的元素按照给定的方法进行转换。
distinct(去重)
public static void main(String [] args) {
testDistinct1();
}
/**
* 集合去重(基本类型)
*/
private static void testDistinct1() {
//简单字符串的去重
List list = Arrays.asList("111","222","333","111","222");list.stream().distinct().forEach(System.out::println);
}运行结果:

public static void main(String [] args) {
testDistinct2();
}
/**
* 集合去重(引用对象)
*/
private static void testDistinct2() {
//引用对象的去重,引用对象要实现hashCode和equal方法,否则去重无效
Student s1 = new Student(1L, "肖战", 15, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
Student s5 = new Student(1L, "肖战", 15, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
students.add(s5);
students.stream().distinct().forEach(System.out::println);
}运行结果:

可以看出,两个重复的“肖战”同学进行了去重,这不仅因为使用了distinct()方法,而且因为Student对象重写了equals和hashCode()方法,否则去重是无效的。
sorted(排序)
public static void main(String [] args) {
testSort1();
}
/**
* 集合排序(默认排序)
*/
private static void testSort1() {
List list = Arrays.asList("333","222","111");list.stream().sorted().forEach(System.out::println);
}运行结果:

public static void main(String [] args) {
testSort2();
}
/**
* 集合排序(指定排序规则)
*/
private static void testSort2() {
Student s1 = new Student(1L, "肖战", 15, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
students.stream()
.sorted((stu1,stu2) ->Long.compare(stu2.getId(), stu1.getId()))
.sorted((stu1,stu2) -> Integer.compare(stu2.getAge(),stu1.getAge()))
.forEach(System.out::println);
}运行结果:

上面指定排序规则,先按照学生的id进行降序排序,再按照年龄进行降序排序
limit(限制返回个数)
public static void main(String [] args) {
testLimit();
}
/**
* 集合limit,返回前几个元素
*/
private static void testLimit() {
List list = Arrays.asList("333","222","111");list.stream().limit(2).forEach(System.out::println);
}运行结果:

skip(删除元素)
public static void main(String [] args) {
testSkip();
}
/**
* 集合skip,删除前n个元素
*/
private static void testSkip() {
List list = Arrays.asList("333","222","111");list.stream().skip(2).forEach(System.out::println);
}运行结果:

reduce(聚合)
public static void main(String [] args) {
testReduce();
}
/**
* 集合reduce,将集合中每个元素聚合成一条数据
*/
private static void testReduce() {
List list = Arrays.asList("欢","迎","你");
String appendStr = list.stream().reduce("北京",(a,b) -> a+b);
System.out.println(appendStr);
}运行结果:

min(求最小值)
public static void main(String [] args) {
testMin();
}
/**
* 求集合中元素的最小值
*/
private static void testMin() {
Student s1 = new Student(1L, "肖战", 14, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
Student minS = students.stream().min((stu1,stu2) ->Integer.compare(stu1.getAge(),stu2.getAge())).get();
System.out.println(minS.toString());
}运行结果:

上面是求所有学生中年龄最小的一个,max同理,求最大值。
anyMatch/allMatch/noneMatch(匹配)
public static void main(String [] args) {
testMatch();
}
private static void testMatch() {
Student s1 = new Student(1L, "肖战", 15, "浙江");
Student s2 = new Student(2L, "王一博", 15, "湖北");
Student s3 = new Student(3L, "杨紫", 17, "北京");
Student s4 = new Student(4L, "李现", 17, "浙江");
List students = new ArrayList<>();
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
Boolean anyMatch = students.stream().anyMatch(s ->"湖北".equals(s.getAddress()));if (anyMatch) {
System.out.println("有湖北人");
}
Boolean allMatch = students.stream().allMatch(s -> s.getAge()>=15);if (allMatch) {
System.out.println("所有学生都满15周岁");
}
Boolean noneMatch = students.stream().noneMatch(s -> "杨洋".equals(s.getName()));if (noneMatch) {
System.out.println("没有叫杨洋的同学");
}
}运行结果:

anyMatch:Stream 中任意一个元素符合传入的 predicate,返回 true
allMatch:Stream 中全部元素符合传入的 predicate,返回 true
noneMatch:Stream 中没有一个元素符合传入的 predicate,返回 true
总结
上面介绍了Stream常用的一些方法,虽然对集合的遍历和操作可以用以前常规的方式,但是当业务逻辑复杂的时候,你会发现代码量很多,可读性很差,明明一行代码解决的事情,你却写了好几行。试试lambda表达式,试试Stream,你会有不一样的体验。
END
关注我

公众号(zhisheng)里回复 面经、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章
Flink 实战
1、《从0到1学习Flink》—— Apache Flink 介绍2、《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门3、《从0到1学习Flink》—— Flink 配置文件详解4、《从0到1学习Flink》—— Data Source 介绍5、《从0到1学习Flink》—— 如何自定义 Data Source ?6、《从0到1学习Flink》—— Data Sink 介绍7、《从0到1学习Flink》—— 如何自定义 Data Sink ?8、《从0到1学习Flink》—— Flink Data transformation(转换)9、《从0到1学习Flink》—— 介绍 Flink 中的 Stream Windows10、《从0到1学习Flink》—— Flink 中的几种 Time 详解11、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 ElasticSearch12、《从0到1学习Flink》—— Flink 项目如何运行?13、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 Kafka14、《从0到1学习Flink》—— Flink JobManager 高可用性配置15、《从0到1学习Flink》—— Flink parallelism 和 Slot 介绍16、《从0到1学习Flink》—— Flink 读取 Kafka 数据批量写入到 MySQL17、《从0到1学习Flink》—— Flink 读取 Kafka 数据写入到 RabbitMQ18、《从0到1学习Flink》—— 你上传的 jar 包藏到哪里去了19、大数据“重磅炸弹”——实时计算框架 Flink
20、《Flink 源码解析》—— 源码编译运行
21、为什么说流处理即未来?
22、OPPO数据中台之基石:基于Flink SQL构建实数据仓库
23、流计算框架 Flink 与 Storm 的性能对比
24、Flink状态管理和容错机制介绍
25、原理解析 | Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
26、Apache Flink 是如何管理好内存的?
27、《从0到1学习Flink》——Flink 中这样管理配置,你知道?
28、《从0到1学习Flink》——Flink 不可以连续 Split(分流)?
29、Flink 从0到1学习—— 分享四本 Flink 的书和二十多篇 Paper 论文
30、360深度实践:Flink与Storm协议级对比
31、Apache Flink 1.9 重大特性提前解读
32、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
33、美团点评基于 Flink 的实时数仓建设实践
34、Flink 灵魂两百问,这谁顶得住?
35、一文搞懂 Flink 的 Exactly Once 和 At Least Once
36、你公司到底需不需要引入实时计算引擎?
37、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
Flink 源码解析
知识星球里面可以看到下面文章
 喜欢就点个"在看"呗^_^
喜欢就点个"在看"呗^_^