随机森林原始论文_初识随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
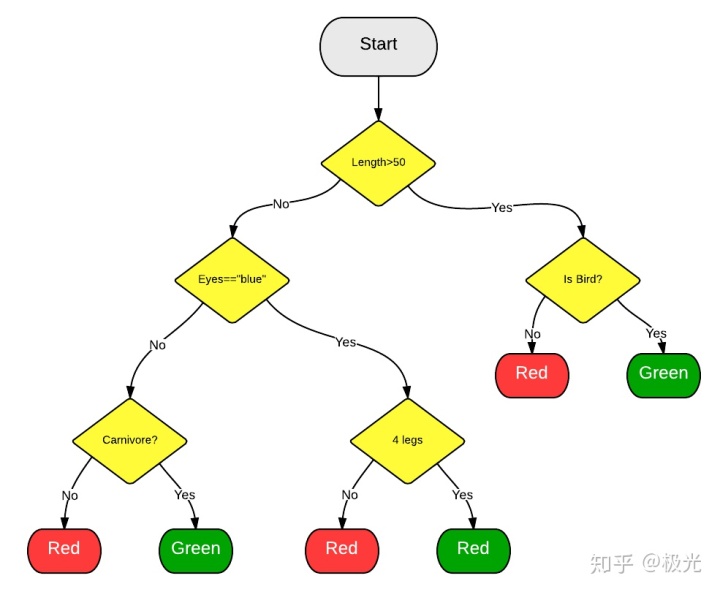
常见思路:
- 用N来表示训练用例(样本)的个数,M表示特征数目。
- 输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
- 从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
- 对于每一个节点,随机选择m个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这m个特征,计算其最佳的分裂方式。
- 每棵树都会完整成长而不会剪枝,这有可能在建完一棵正常树状分类器后会被采用。
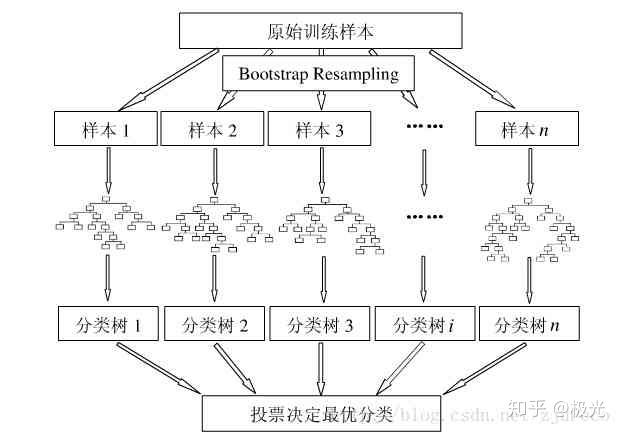
Bagging是并行式集成学习方法最典型的代表框架。其核心概念在于自助采样(Bootstrap Sampling),给定包含m个样本的数据集,有放回的随机抽取一个样本放入采样集中,经过m次采样,可得到一个和原始数据集一样大小的采样集。我们可以采样得到T个包含m个样本的采样集,然后基于每个采样集训练出一个基学习器,最后将这些基学习器进行组合。这便是Bagging的主要思想。Bagging与Boosting图示如下:
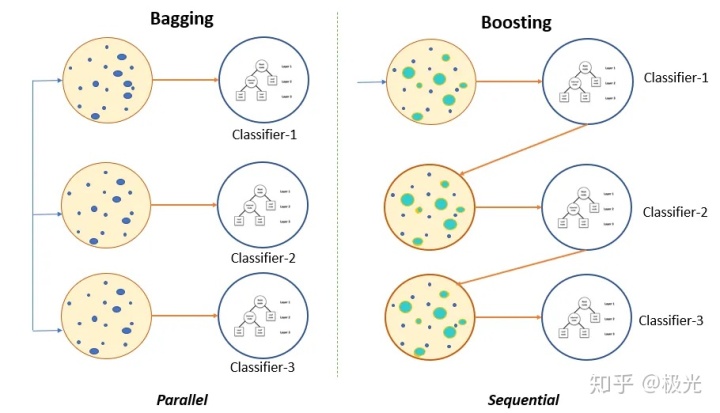
可以清楚的看到,Bagging是并行的框架,而Boosting则是序列框架(但也可以实现并行)。随机森林(Random Forest)就没有太多难以理解的地方了。所谓随机森林,就是有很多棵决策树构建起来的森林,因为构建过程中的随机性,故而称之为随机森林。随机森林算法是Bagging框架的一个典型代表。
使用numpy来手动实现一个随机森林算法。随机森林算法本身是实现思路我们是非常清晰的,但其原始构建需要大量搭建决策树的工作,比如定义树节点、构建基本决策树、在基本决策树基础上构建分类树和回归树等。
在此基础上,随机森林算法的构建主要包括随机选取样本、随机选取特征、构造森林并拟合其中的每棵树、基于每棵树的预测结果给出随机森林的预测结果。
import numpy as np
# 该模块为自定义模块,封装了构建决策树的基本方法
from ClassificationTree import *
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 树的棵数
n_estimators = 10
# 列抽样最大特征数
max_features = 15
# 生成模拟二分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1)
rng = np.random.RandomState(2)
X += 2 * rng.uniform(size=X.shape)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)定义第一个随机性,行抽样选取样本
在用模型拟合之前,尝试主成分分析(PCA)也是常见的做法。但是,为什么还要增加这一步呢?难道随机森林的目的不是帮助我们更轻松地理解特征重要性吗?
当我们分析随机森林模型的「特征重要性」时,PCA 会使每个「特征」的解释变得更加困难。但是 PCA 会进行降维操作,这可以减少随机森林要处理的特征数量,因此 PCA 可能有助于加快随机森林模型的训练速度。
请注意,计算成本高是随机森林的最大缺点之一(运行模型可能需要很长时间)。尤其是当你使用数百甚至上千个预测特征时,PCA 就变得非常重要。因此,如果只想简单地拥有最佳性能的模型,并且可以牺牲解释特征的重要性,那么 PCA 可能会很有用。
# 自助抽样选择训练数据子集
def bootstrap_sampling(X, y):
X_y = np.concatenate([X, y.reshape(-1,1)], axis=1)
np.random.shuffle(X_y)
n_samples = X.shape[0]
sampling_subsets = []
for _ in range(n_estimators):
# 第一个随机性,行抽样
idx1 = np.random.choice(n_samples, n_samples, replace=True)
bootstrap_Xy = X_y[idx1, :]
bootstrap_X = bootstrap_Xy[:, :-1]
bootstrap_y = bootstrap_Xy[:, -1]
sampling_subsets.append([bootstrap_X, bootstrap_y])
return sampling_subsets然后基于分类树构建随机森林:
随机森林是由许多决策树组成的模型。这个模型不是简单地平均所有树(我们可以称之为“森林”)的预测,而是使用了两个关键概念,名字中的随机二字也是由此而来:
- 在构建树时对训练数据点进行随机抽样
- 分割节点时考虑特征的随机子集
trees = []
# 基于决策树构建森林
for _ in range(n_estimators):
tree = ClassificationTree(min_samples_split=2, min_impurity=0,
max_depth=3)
trees.append(tree)定义训练函数,对随机森林中每棵树进行拟合。
# 随机森林训练
def fit(X, y):
# 对森林中每棵树训练一个双随机抽样子集
n_features = X.shape[1]
sub_sets = bootstrap_sampling(X, y)
for i in range(n_estimators):
sub_X, sub_y = sub_sets[i]
# 第二个随机性,列抽样
idx2 = np.random.choice(n_features, max_features, replace=True)
sub_X = sub_X[:, idx2]
trees[i].fit(sub_X, sub_y)
trees[i].feature_indices = idx2
print('The {}th tree is trained done...'.format(i+1))
要理解和使用各种选项,有关如何计算它们的更多信息是有用的。 大多数选项取决于随机林生成的两个数据对象。
当通过替换采样绘制当前树的训练集时,大约三分之一的情况被遗漏在样本之外。 随着树木被添加到森林中,该oob(out-of-bag)数据用于获得对分类错误的运行无偏估计。 它还用于获得变量重要性的估计。
在构建每个树之后,所有数据都在树下运行,并且为每对案例计算邻近度。 如果两个案例占用相同的终端节点,则它们的接近度增加一。 在运行结束时,通过除以树的数量来标准化邻近度。 Proximities用于替换缺失数据,定位异常值,以及生成数据的低维视图。(论文里的东西就是如此的生涩,难懂)。
我们将上述过程进行封装,分别定义自助抽样方法、随机森林训练方法和预测方法。完整代码如下:
class RandomForest():
def __init__(self, n_estimators=100, min_samples_split=2, min_gain=0,
max_depth=float("inf"), max_features=None):
# 树的棵树
self.n_estimators = n_estimators
# 树最小分裂样本数
self.min_samples_split = min_samples_split
# 最小增益
self.min_gain = min_gain
# 树最大深度
self.max_depth = max_depth
# 所使用最大特征数
self.max_features = max_features
self.trees = []
# 基于决策树构建森林
for _ in range(self.n_estimators):
tree = ClassificationTree(min_samples_split=self.min_samples_split, min_impurity=self.min_gain,
max_depth=self.max_depth)
self.trees.append(tree)
# 自助抽样
def bootstrap_sampling(self, X, y):
X_y = np.concatenate([X, y.reshape(-1,1)], axis=1)
np.random.shuffle(X_y)
n_samples = X.shape[0]
sampling_subsets = []
for _ in range(self.n_estimators):
# 第一个随机性,行抽样
idx1 = np.random.choice(n_samples, n_samples, replace=True)
bootstrap_Xy = X_y[idx1, :]
bootstrap_X = bootstrap_Xy[:, :-1]
bootstrap_y = bootstrap_Xy[:, -1]
sampling_subsets.append([bootstrap_X, bootstrap_y])
return sampling_subsets
# 随机森林训练
def fit(self, X, y):
# 对森林中每棵树训练一个双随机抽样子集
sub_sets = self.bootstrap_sampling(X, y)
n_features = X.shape[1]
# 设置max_feature
if self.max_features == None:
self.max_features = int(np.sqrt(n_features))
for i in range(self.n_estimators):
# 第二个随机性,列抽样
sub_X, sub_y = sub_sets[i]
idx2 = np.random.choice(n_features, self.max_features, replace=True)
sub_X = sub_X[:, idx2]
self.trees[i].fit(sub_X, sub_y)
# 保存每次列抽样的列索引,方便预测时每棵树调用
self.trees[i].feature_indices = idx2
print('The {}th tree is trained done...'.format(i+1))
# 随机森林预测
def predict(self, X):
y_preds = []
for i in range(self.n_estimators):
idx = self.trees[i].feature_indices
sub_X = X[:, idx]
y_pred = self.trees[i].predict(sub_X)
y_preds.append(y_pred)
y_preds = np.array(y_preds).T
res = []
for j in y_preds:
res.append(np.bincount(j.astype('int')).argmax())
return res
基于上述随机森林算法封装来对模拟数据集进行训练并验证:
rf = RandomForest(n_estimators=10, max_features=15)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
print(accuracy_score(y_test, y_pred))sklearn也为我们提供了随机森林算法的api,我们也尝试一下与numpy手写的进行效果对比:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(max_depth=3, random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))优点:
- 在当前的很多数据集上,相对其他算法有着很大的优势,表现良好。
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择(因为特征子集是随机选择的)。
- 在训练完后,它能够给出哪些feature比较重要。
- 训练速度快,容易做成并行化方法(训练时树与树之间是相互独立的)。
- 在训练过程中,能够检测到feature间的互相影响。
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。