【论文分享】LibAFL: A Framework to Build Modular and Reusable Fuzzers
1. 简介
AFL是软件安全测试领域的一个重要里程碑,使得fuzzing成为了一个主要的研究领域,并带动了大量的研究去提高fuzzing流水线上的各个方面。
许多研究是通过fork AFL的代码来进行实现的。虽然一开始看起来挺合适的,但是要把多种fork合并到一个fuzzer,需要大量的工程开销,阻碍了不同技术客观和公正的评估。严重碎片化的fuzzing的生态阻止了研究者组合多种技术来实现新的原型系统。
为了解决这个问题,这篇文章提出了LibAFL,一个框架来构建模块化和可重用的fuzzer。文章讨论了fuzzing中的不同模块,并将其映射到一个可扩展的框架中去。LibAFL允许研究者和工程师去扩展核心的fuzzer流水线,同时可以分享他们的模块,以便未来的评估。作为LibAFL的一部分,作者已经整合了20多个前人的工作,并且做了相当多的实验来显示我们框架在整合评估不同方法的有效性。作者希望这能够帮助fuzzing领域进步,同时为未来可比较性和可扩展的研究打下基础。
2.fuzzing的9个模块
input:程序的输入,或者从外部获取的数据,输入到系统中,影响了系统的行为。这样的数据就是输入。
作者将输入(Input)定义为程序输入的内部表示。举个简单的例子,程序的输入就是一个单字节数组。许多fuzzer直接存储并操作字节数组,并把结果传到目标程序。
然而,字节数组并不是输入的理想表示形式。就比如,如果目标程序希望接受一系列的系统调用的话,字节数组就不合适了。另外一种方式是把输入存储为抽象语法树(AST)的形式,这样可以保留语法信息。还有其他的工作是把输入处理为一序列的tokens或者语言的IR。
Corpus:输入的存储以及关联的元数据。不同的存储会影响fuzzer的能力,比如,corpus存在内存中,会使得fuzzer运行很快,但是同时也会很快消耗完内存。而存储在disk的corpus虽然也可以检查fuzzer的状态,但是会引入disk操作的开销。
主流的fuzzer都存在disk,但这个选择影响了并行fuzzing的扩展性,并且需要标准库来实现文件IO的操作。
在libafl的模型中,一个fuzzer至少需要两个单独的corpora,一个用来存储有趣的测试样例,作为fuzzer进化算法的组件。另一个用来存储solutions,也就是满足fuzzer目标的测试样例,例如导致程序崩溃的crash。
Scheduler:调度器是和corpus紧密连接的一个模块。这个模块主要是告诉fuzzer下一个要fuzz的测试样例。最原始的调度器的实现有FIFO(先进先出)或者随机选择。更复杂的调度去可能会使用一些概率算法或者应用其他的调度器到corpus的子集里去。
Stage:stage是一个组件,定义了从corpus操作测试样例的一个行为。通常来说,调度器选择了一个测试样例后,fuzzer会在每个阶段执行给定的输入。Stage是一个很广的实体,通常作为唤起变异器的组件(random,havoc stage in AFL)
另外一个很知名的stage是最小化的过程。他主要是把测试样例的大小弄小,同时不改变测试样例的覆盖率。
Observer:观察器从目标程序的执行中提供信息。比较知名的观察器就是覆盖率映射表。这个映射表包含了执行过的每一条边。这个信息不会被多次运行的时候保持不变,他是程序的动态属性。(AFL的bitmap)
Executor:主要负责执行目标程序。在作者的模型中,执行器不仅是如何执行目标程序,也包括所有执行过程中的非法操作。所以执行器负责告诉程序关于fuzz想要用的输入。
Feedback:反馈是用来区分程序的执行的输出是否有趣。理论上,这个信息用来确定对应的输入是否被加到corpus中。大多数情况下,feedback和observer是深度关联的。但是这两个是不同的概念。事实上,feedback通常处理多个观察器传来的信息来确定执行是否是有趣的。而有趣这个概念是很抽象的,通常可以理解为是否发现了新的东西(比如发现了新的边)。
识别有趣输入的过程在fuzzing中也有第二个重要目标,找到能够满足特定的属性的solution,比如目标程序中一个可观测到的crash。
Mutator:将一个输入或者多个输入变成新的输入。变异器可以组合多个其他的变异器,并且通常与一个特定的输入类型有关。在传统的fuzzer里,变异器包含许多位级别的操作,比如位翻转或者基本块交换。一个变异器也可以依据输入格式来变异。比如通过交换AST树上的一个节点来实现变异。
Generator:从scratch中生成一个新的输入。例如NAUTILUS使用基于语法的生成器创建初始的corpus和子树生成器作为它的语法变异器。
3. 框架结构
3.1 设计理念和顶层设计
LibAFL的目的是构建一种基于可重用组件和可靠、快速和可扩展的先进技术的模块化设计的新时代fuzzer。
libafl的框架基于三个关键原则:
-
Extensibility:允许用户交换第三章介绍的实体的不同实现,而不需要改动其他的部分。这样可以允许不同的技术融合到一起。
-
Portability:大多数的fuzzer是操作系统特定的。要不只能对unix程序,要不是windows。为了避免这个缺点,libafl以一种不依赖系统的方式来设计核心库。而且,为了最大化可移植性,实现了LibAFL的子集,包含了所有的核心组件,而不需要任何标准库的依赖。因此,可以让用户对bare-metal目标(比如嵌入式系统、内核)写fuzzer。
-
Scalability:设计的选择不能和fuzzer的多核运行的特性相矛盾。因为这点,libafl设计了一个基于事件的接口,能够在fuzzer之间相互通信。
libfuzzer虽然能够在不同的操作系统上用,但是不能不需要标准库来进行编译。AFL自身是基于disk进行IO通信,同时用了大量的系统调用,比如fork,导致其扩展到多核上的效果不好。其他扩展性更好的方案,比如HONGGFUZZ依然是基于系统调用来控制目标并且在多个并行的线程中保留一个共享的状态。
为了创建一个fuzzing的框架,能够满足上面的三个目标,围绕三个核心库设计了LibAFL。
-
LibAFl Core是主要的库,包含fuzzing的组件和他们相应的组件。这个库的大部分都依赖于Rust core+alloc,因此,可以在没有标准库的情况下运行。
-
LibAFL Targets包含了在目标程序里的代码。比如用来追踪覆盖率的运行时的库。
-
LibAFL CC提供了函数来写编译器的wrapper,方便用户来进行插桩。
除了这三个核心库,也包含插桩后端提供API来让libafl可以应用到不同的执行引擎,比如QEMU和Frida。
3.2 核心库
libafl的核心架构如下图所示:

大部分的组件都是和前面的实体是一对一映射的关系。有三个多出来的组件是:State、Fuzzer和Events Manager。
每个组件都映射为一个Rust的泛型特征,运行它和其他不同的组件进行组合。
Zero-cost Abstraction Extensibility的代价是引入抽象,通常会影响性能。由于性能对于fuzzing的影响很大,libafl的设计是一种灵活的抽象,而且不会在运行时引入很大的开销。
在初期的测试阶段,libafl的作者没有选择传统的面向对象的模式,而是使用泛型特征。所以使用rust语言的设计,来让编译器做进一步的优化。
选择Rust的两个原因:
-
编译器优化友好
-
相当内联
State 是所有合法数据在的地方。所有进化算法的数据都存在state里,比如执行的次数,伪随机数,语料库。
由于一些类型的反馈也需要保存状态,比如覆盖率。因此,libafl引入了FeedbackState组件来连接State和Feedback。feedback状态的实例包含在状态里,并且在fuzzing过程的开始就生成了。
找个地方放置fuzzer的数据主要是利用Rust的序列化的特性。序列化和去序列化一个状态,能够让基于libafl的fuzer在内部的某个特定状态停止和重启。
Fuzzer是一个定义fuzzer能做什么的容器。它包含feedback,objectives,scheduler,以及其他可能改变fuzzer状态的操作。这些来自fuzzer的过程被隔开了,为的是遵守Rust语言的借用规则。遵守借用规则是以防一些操作同时改变了fuzzer和state。
fuzzer的主要功能:
-
FuzzOne:一个测试样例要如何处理
-
InputEvaluation:如何评估一个新的输入
EventManager:创建和处理事件的一个接口,可以用来实现多核fuzzer或者单纯的日志记录。
MetadataSystem:fuzzing算法经常需要一个测试样例的其他数据,或者fuzzer的全部状态。因此,libafl需要提供一种方式来扩展测试样例的数据和在状态里的数据。
为了提供这种扩展能力,同时保证简单和性能,libafl设计了一个元数据系统。同时,测试样例和状态保留了一个映射表,作为这个元数据的扩展容器。这样的话,不同但是相关的模块可以操作同一个元数据,并且可以忽视其他模块对元数据的处理。这是libafl唯一引入的一点运行开销的地方,主要是由于映射表的查询导致的。
Composable Feedbacks 。一个fuzzer可能需要组合多种feedbacks来评估给定的输入有多有趣。libafl里通过使用逻辑运算符来组合feedback。比如,要对crash进行去重的话,并且收集两种反馈,一个是认为导致崩溃的输入是有趣的,另一个是触发了一个新的栈的路径。这种情形下,可以通过使用逻辑运算符AND来组合这两种反馈,从而实现crash的去重。
Monitor。最后一个fuzzer的组件是监控器。它的功能主要是保留触发事件的数据以及展示给用户。
3.3 插桩后端
libafl也可以很容易地导入其他的插桩后端,比如二进制翻译器,或者一个简单的编译插桩的pass。默认情况下,libafl提供了额外的库来与一些知名的插桩后端相联,比如LLVM,SanitizerCoverage,Qemu usermode和Frida。
除了上面这几个,还提供了concolic execution。因此也整合了SymCC和SymQEMU。
目前已部分支持TinyInst去对windows,macOS的程序进行插桩,以及NYX这个hypervisor级别的快照fuzzing。
4 应用与实验
实验部分主要针对四个问题进行评估:
-
roadblocks bypassing
-
structure-aware fuzzing
-
corpus scheduling
-
energy assignment
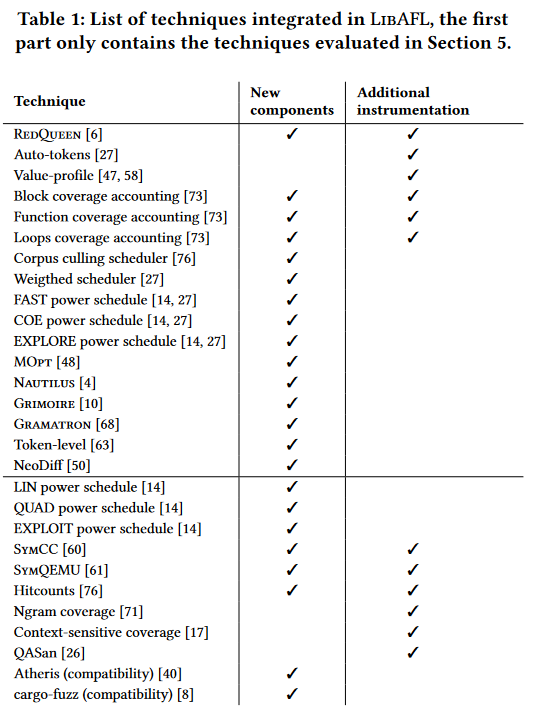
主要是看libafl在这四个问题上的表现效果。下面的表格列举了目前libafl支持的一些特性。
4.1 Bypassing Roadblocks
bypassing roadblocks指的是通过绕过很难求解的约束来增加代码覆盖率。比如,多字节比较对于通过随机的遗传变异是很难绕过的。因为解空间很大,盲目地猜测是不切实际的。Libafl提供了几种现有的技术来绕过这些roadblocks。
-
value-profile(libfuzzer):通过最大化两个指令的操作数的匹配的位来求解比较指令
-
cmplog(AFL++):通过找到并替换input-to-state values。对比较指令和将两个指针作为参数的函数进行插桩。并且在运行时记录相关的值到映射表。然后变异器匹配输入的模式,并用比较指令另一个操作数的值替代输入。
-
autotokens(AFL++):从比较指令中提取tokens,从函数中提取立即数,编码到二进制的段里。然后把这些token放在状态的元数据字典里,然后在变异器使用这些tokens。由于这种方法不引入开销,所以将这种方法作为baseline。
最后的实验结果是cmplog(95.94)>value_profile_complog(95.03) > plain(94.65) > value_profile(90.13)。
4.2 Structure-aware Fuzzing
基于遗传算法的变异器对于一些结构化的输入表现不好。针对这个问题,一种解决方法是让fuzzer意识到输入的格式。Libafl也提供了几种现有的技术,来处理结构化的输入。
-
NAUTILUS:一种基于语法的覆盖率导向的fuzzer。他的核心思想是在语法树上进行变异。
-
GRAMATRON:利用一种grammar-to-automata的转换方法来实现高效的变异器。
-
GRIMOIRE:使用那些会增加覆盖率的部分输入作为tokens来构建树形的输入,并且做grammar-like的变异。他原本是对JavaScript语言进行fuzz的,但是libafl的实现是通用的,并且可以用到任何语言。
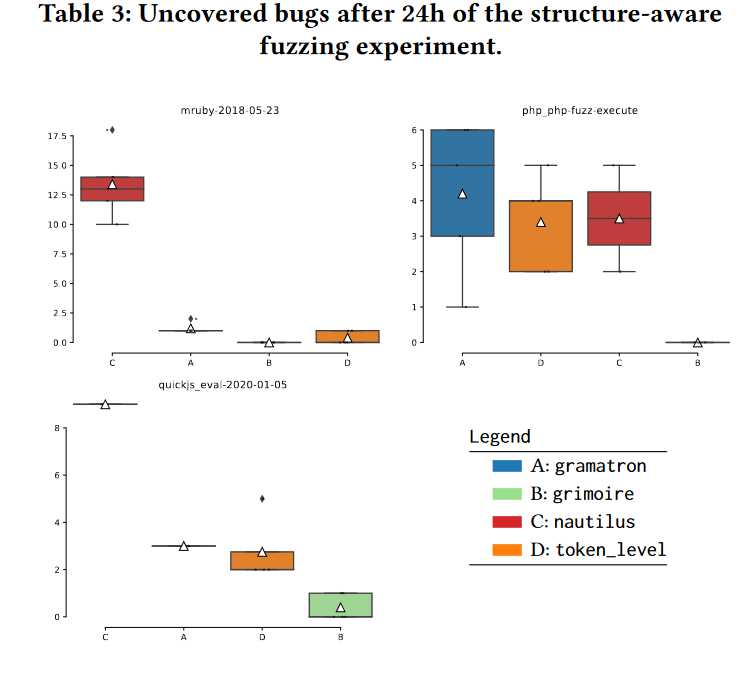
评估这些方法的指标为未覆盖的bug的数目。因为这类fuzzer的有效性并不依赖于代码覆盖率。
实验结果如下,grimoire的表现效果最好。
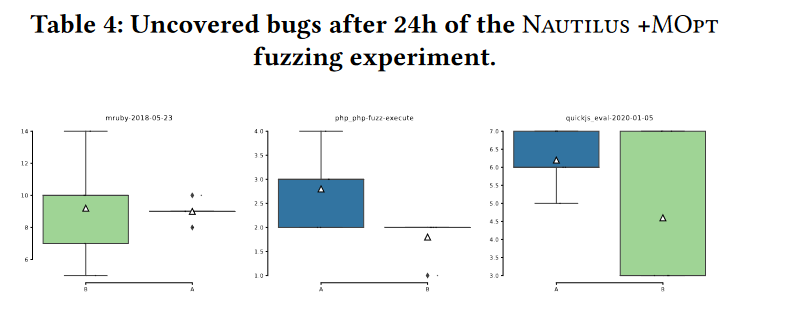
除此之外,作者还将前面实验表现不好的nautius与一个不相关的技术MOPT结合,来看二者结合的效果,实验如下图所示。总体来说,MOPT的效果与目标程序有很大的关系。
4.3 Corpus Scheduling
从语料库中选择哪一个测试样例来用是许多研究的重点。最简单的是随机选择或者FIFO队列。libafl提供了这两种方法,也包括其他的调度器。
-
MinimizerScheduler(AFL):基于执行速度和输入的长度,同时保持最大的覆盖率来选择种子。
-
weighted(AFL++):基于概率进行抽样,概率的分数使用各种指标,包括执行的时间,覆盖率映射表的大小。
-
accounting(TORTOISEFUZZ):使用三种安全影响指标来选择输入,基本块和函数粒度级别的内存操作,loop back edges(回到循环的边)的数目。
实验结果:weighted>minimizer>accounting>rand
并且这几个差别不是很大。尽管有相当多的研究在做这个问题。
作者认为可能是libafl的吞吐量很大,导致是在这些程序上运行的很快,因此就看不出差别。
4.4 Energy Assignment
能量分配主要是回答一个输入需要变异多少次生成一个测试样例的问题。最原始的方法是使用一个常数值。最常见的简单的方法是根据时间间隔来分配一个随机值。libafl提供了这种方法,名为plain。AFLFast工作里提出了六种不同的算法:exploit,explore,coe,fast,lin和quad。
实验结果:explore>fast>plain>coe
同样,他们的区别很小。
4.5 通用的bit-level Fuzzer
这部分就把前面的四个问题里最好的技术整合到一起,和其他成熟的fuzzer(AFL++,Honggfuzz,libfuzzer)进行评估。
总体上效果要优于现有的fuzzer。
具体的实验结果在该网址可以看到:https://www.fuzzbench.com/reports/experimental/2022-04-11-libafl/index.html
4.6 Differential Fuzzing
作者为了证明libafl不止可以用于构建基于覆盖率导向的模糊测试。亲身用两天,900行代码复现了NeoDiff。这是一个对比的模糊测试,面向的是以太坊虚拟机。
NeoDiff,原本是基于python写的,会去比较基于同样的输入比较两个以太坊虚拟机的执行结果。具体来说,它使用了状态哈希的方法。就是将寄存器的值,内存和栈上每个指令的概率抽样进行哈希。它使用的反馈是类型哈希(type hash),操作码的哈希以及每个指令在栈上前两个东西的类型。任何输入产生了新的类型哈希,就会被加入到语料库中。
并且,作者拿基于libafl复现的NeoDIFF与原始版本对比实验结果,发现libafl的效果要比原本的好很多。作者认为是语言实现上的问题,rust实现要比python实现的好很多。
4.7第三方应用
libafl已经被很多新用户使用了。这些用户之前没有使用这些框架的经验。
-
TLSPUFFIN:结合fuzzing和模型测试,实现了对TLS协议的fuzzer。
-
TARTIFLETTE:基于KVM的快照fuzzer。提供了一种新的执行器,通过系统调用模拟和覆盖率追踪的插桩来将Linux ELF当作是VM进行运行。
-
NANAFZZ:检查竞态条件的漏洞的fuzzer。
5 局限性
没有包含Link Time Optimization pass来构建程序的控制流图,导致不支持大部分的定向模糊测试。
libafl提供了强大的concolic tracing的API,可以用来扩展SymCC和SymQEMU来过滤约束和符号路径通信。目前,libafl使用Z3来生成新的测试样例。然而传统的concolic fuzzer的缺陷,这个框架也不能解决。主要原因是:
-
求解器时间开销和资源开销都很大。
-
fuzzer和concolic结合的并不好。即使当一个求解器生成了复杂约束的测试样例,也很难让fuzzer去变异生成的测试样例,而不去破坏求解出来表达式的合法性。
最后是关于这篇论文的一些链接:
-
libafl的github仓库:https://github.com/AFLplusplus/LibAFL
-
论文地址:https://www.eurecom.fr/publication/6973/download/sec-publi-6973.pdf