Java基础【理解版】
目录
Java中基本数据类型有哪些
Integer 和 int的区别
自动装箱和自动拆箱的原理
Integer和int的深入对比:
聊一聊static和JVM?
static关键字的作用?
final关键字的作用?
synchronized关键字的作用?
String和StringBuilder和StringBuffer区别?
String a = "aa" 和 String a = new String("aa") 创建字符串的区别
== 和 equals 的区别是什么
equals和hashCode的区别?
为什么重写了hashcode方法还需要重写equals方法?
final 和 finally 和 finalize 的区别
Java是如何实现跨平台的?
JDK 、JRE、JVM 有什么区别和联系?
面向对象和面向过程的区别
1:面向过程【微观】
2:面向对象【宏观】
3:区别和联系
面向对象四大特性
方法重写和重载
为什么构造方法不能被重写?
普通类和抽象类
为什么要使用抽象类?
接口和抽象类
接口和抽象类除了在语法上的区别还有在语义上的区别
IO流
你知道BIO,NIO,AIO么?
Java 中四大基础流
读文本用什么流,读图片用什么流
字符流和字节流有什么区别
BufferedInputStream(缓冲字节输入流) 用到什么设计模式
怎么实现一张图片拷贝
怎么实现文本拷贝
Java中基本数据类型有哪些
byte,short,int,long,float,double,boolean,char.
byte:8位,最大存储数据量是255,存放的数据范围是-128~127之间。
short:16位,
int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
float:32位,
double:64位,
boolean:只有true和false两个取值。
char:16位,存储Unicode码,用单引号赋值。eg:'a';
Integer 和 int的区别
int是基本数据类型,变量中直接存放数值,变量初始化时值是0,将数据存放在常量池中。
Integer是引用数据类型(是一个类,可以进行new),变量中存放的是该对象的引用地址,变量初始化时值时*null,将数据存放在堆内存中 【开发中都是用的包装类-基本类型不是类,不能new出来,因此不具备面对对象的功能,无法调用方法。】**
Integer是int类型的包装类,将int封装成Integer,符合java面向对象的特性,可以使用各种方法比如和其他数据类型间的转换。
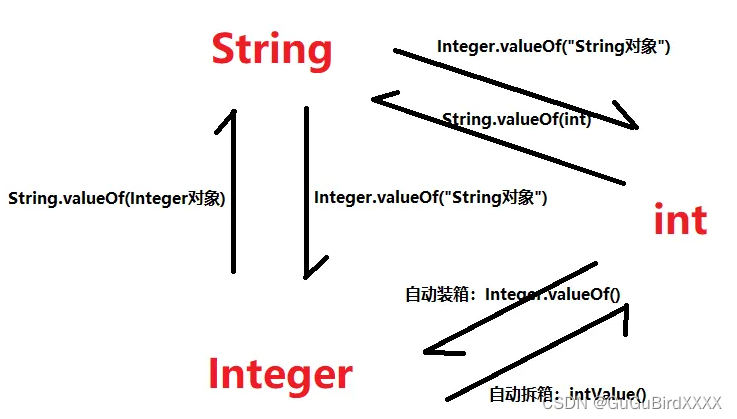
自动装箱和自动拆箱的原理
自动装箱时就是将编译器将基本数据类型调用valueOf()方法转换成包装类对象。
自动拆箱就是编译器将包装类调用IntValue(),doubleValue()方法转换成基本数据类型。
Integer和int的深入对比:
-
两个通过new生成的Integer对象,由于在堆中地址不同,所以永远不相等【因为是final修饰的,每次都会创建一个新的对象。】
-
int和Integer比较时,只要数值相等,结果就相等,因为包装类和基本数据类型比较时,会自动拆箱,将Integer转化为int
-
通过new生成的Integer对象和非通过new生成的Integer对象相比较时,由于前者存放在堆内存中【堆内存存储的是对象】,后者存放在Java常量池【基本数据的对象和数组等】中,所以永远不相等
-
两个非通过new生成的Integer对象比较时,如果两个变量的数值相等且在-128到127之间,结果就相等。这是因为给Integer对象赋一个int值,java在编译时,会自动调用静态方法valueOf(),根据java api中对Integer类型的valueOf的定义,对于-128到127之间的整数,会进行缓存,如果下次再赋相同的值会直接从缓存中取,即享元模式
名词解释:享元模式是设计模式中少数几个以提高系统性能为目的的模式之一。它的核心思想是:如果在一个系统中存在多个相同的对象,那么只需要共享一份对象的拷贝,而不必为每一次使用都创建新的对象。
聊一聊static和JVM?
java将内存分为栈内存(stack memory)和堆内存(heap memory)。
其中
栈内存用来存放一些基本数据类型的变量、数组和对象的引用,
堆内存主要存放一些对象。
在JVM中如果一个类中有static修饰的成员变量和成员方法,则会会其在固定的位置开辟一个固定大小的内存区域,有了这个固定的特定,JVM就可以非常方便的访问他们。static修饰的成员变量可以进行共享,而且不用创建对象。
static关键字的作用?
就是方便在没有创建对象的情况下进行调用(方法和变量)。
static修饰的成员方法为静态方法,直接通过类名进行调用,在当前类可以直接省略类名。
static修饰的成员方法不能访问非static修饰的成员变量和成员方法。
非static修饰的成员方法需要通过对象进行调用。
static修饰的成员变量为静态变量,静态变量和非静态变量的区别:
静态变量被所有对象共享,在内存中只有一个副本,在类初次加载的时候才会初始化
非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
final关键字的作用?
final修饰的类,为最终类,该类不能被继承。如String 类
final修饰的方法可以被继承和重载,但不能被重写
final修饰的变量不能被修改,是个常量
static修饰的方法不能被重写可以被继承【static修饰,通过类名进行调用】
synchronized关键字的作用?
synchronized是Java中的关键字,是一个同步锁。它可以修饰的对象有以下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
Java中Synchronized的用法_luoweifu的博客-CSDN博客_synchronized
String和StringBuilder和StringBuffer区别?
三者底层都是基于char[]数组存储数据,默认数据长度为16、JDK1.9之后使用的是byte[]数组 ,因为往往我们存储都是短字符串,使用byte[]这样更**节约空间。
由于String是基于不可变char数组(底层final修饰的)的字符串,所以是不可变的对象。每次对String的操作都会在堆内存中生成新的对象。
StringBuilder和StringBuffer是基于可变数组的字符串【自动进行扩容】,StringBuffer是线程安全的【多线程】,方法有synchronized修饰,但是性能较低,StringBuilder是线程不安全的【单线程】,方法没有synchronized修饰,性能较高
String a = "aa" 和 String a = new String("aa") 创建字符串的区别
String a = “aa”;这句话执行过程是:
先到常量池中寻找“aa”,
1.如果存在,则直接将【原有】“aa”对象的地址传递给a;
2.如果不存在,则在常量池中创建“aa”,然后将地址传递给a.
String a = new String(“aa”);执行过程是:
首先在堆内存(存储对象)中创建对象new String(“aa”),【堆内存存储对象】,将对象的引入传递给a
然后在常量池中寻找“aa”,
1.如果存在,啥事不做;
2.如果不存在,在常量池中创建一个“aa”对象;
总结可见;直接赋值形式的新建string对象是从常量池中拿数据;最多创建一个string对象,最少创建0个string对象;
new形式新建string对象无论怎样会首先在堆内存中创建一个string对象,然后确保常量池中也有一个相同内容的string对象;最多创建2个,最少创建1个。
由于直接赋值方式可能节约内存,推荐使用该方式。
String a = “abc“ 和 String a = new String(“abc“) 创建字符串的区别_GuGuBirdXXXX的博客-CSDN博客
== 和 equals 的区别是什么
“==”
1,比较8大基本数据类型(byte,short,int,long,float,double,char,boolean):
==比较是值是否相等。
2,比较6大引用数据类型(类,接口,抽象类,枚举,注释,数组)
==比较是地址值是否相等。
equals
1,只能比较引用数据类型(因为基本类型不能调用方法)
equals比较的是内容是否相同。
equals和hashCode的区别?
重点结论
前提是两个对象都重写了hashCode和equals方法,
equals相等的两个对象,hashCode一定相等。
hashCode相等的两个对象,equals不一定相等。
上述结论解释:
equals比较的引用数据类型比较的是两个对象的内容是否相等,而hashCode比较的是两个对象的哈希值是否相等(两个内容不同的值生成的哈希值可能也是相同的,所以再进行equals比较的时候,就可能不相等。这就是所谓的哈希碰撞**(HashMap底层原理会有哈希碰撞))
顺带提一下
equals和hashCode,一个是性能好(hashCode),一个是可靠性(equals)。
equals的比较的逻辑比较全面复杂,效率较低,而hashCode比较只用生成一个哈希值就可以了,效率高。
为什么重写了hashcode方法还需要重写equals方法?
首先equals比较的是引用数据类型的内容是否相等,而hashcode比较的是hash值是否相等。
为了提高效率 采取重写hashcode方法,先进行hashcode比较,如果不同【说明两个对象一定不同】,那么就没必要在进行equals的比较了,这样就大大减少了equals比较的次数,这对比需要比较的数量很大的效率提高是很明显的。
final 和 finally 和 finalize 的区别
当用final修饰类的时,表明该类不能被其他类所继承。当我们需要让一个类永远不被继承,此时就可以用final修饰。
finally作为异常处理的一部分,它只能用在try/catch语句中,并且附带一个语句块,表示这段语句最终一定会被执行(不管有没有抛出异常),经常被用在需要释放资源(关流),释放锁的情况下
finalize()【结束】是在java.lang.Object里定义的,也就是说每一个对象都有这么个方法。执行时机:当一个java对象即将被垃圾回收器回收的时候,垃圾回收器GC负责调用finalize()方法。
其实gc可以回收大部分的对象(凡是new出来的对象,gc都能搞定,一般情况下我们又不会用new以外的方式去创建对象),所以一般是不需要程序员去实现finalize的。
GC【Garbage Controller】垃圾回收机制
有了GC,程序员就不需要再手动的去控制内存的释放。当Java虚拟机(JVM)发觉内存资源紧张的时候,就会自动地去清理无用对象(没有被引用到的对象)所占用的内存空间(这里的说法略显粗略,事实上何时清理内存是个复杂的策略)。如果需要,可以在程序中显式地使用System.gc() / System.GC.Collect()来强制进行一次立即的内存清理。Java提供的GC功能可以自动监测对象是否超过了作用域,从而达到自动回收内存的目的,Java的GC会自动进行管理,调用方法:System.gc() 或者Runtime.getRuntime().gc();
常用的垃圾回收算法有三种:标记-清除算法、复制算法、标记-整理算法,分代回收 【新生代和老年代】
Java是如何实现跨平台的?
跨平台:是指java语言编写的程序,一次编译,可以在多个系统运行。
如何实现跨平台:JDK中的javac编译器将java文件编译成字节码文件(.class文件),通过JVM【java虚拟机】将字节码文件通过类加载器编译成不同系统【windows、linux、Mac】**能够识别的二进制机器码**,这样就实现了一次编译,到处(多个系统平台上)运行。【关键因素就是系统是否安装相应的虚拟机。java程序实际是在虚拟机JVM上运行的】
JDK 、JRE、JVM 有什么区别和联系?

JDK(Java Development Kit) :是Java开发工具包,它提供了Java的开发环境(提供了编译器javac等工具,用于将java文件编译为.class[字节码]文件)和运行环境(提供了JVM和Runtime辅助包,用于解析class文件使其得到运行)。JDK是整个Java的核心,包括了Java运行环境(JRE),一堆Java工具tools.jar和Java标准类库 (rt.jar)。
JRE(Java Runtime Enviroment) :是Java的运行环境,JRE是运行Java程序所必须的环境,包含JVM及 Java核心类库**
三者之间的关系:
JDK = JRE + 其他(一堆java工具(javac编译器)和java核心类库)
JRE = JVM + 其他(runtime class libraries等组件)
JDK【Java Development Kit】是 Java 语言的开发工具包。在JDK的安装目录下有一个jre【java runtime environment】目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm【java virtual machine】,lib中则是jvm工作所需要的核心类库,而jvm和 lib合起来就称为jre。
面向对象和面向过程的区别
1:面向过程【微观】
针对小问题的时候,面向过程可以很简单的解决问题,事情复杂的时候面向过程就显得力不从心。面向过程是微观上解决问题的方式。
比如:领导出游,司机开车。
领导找司机开车
司机取车
司机加油
定制出游路线
这些问题都是面向过程解决的问题。
2:面向对象【宏观】
面向对象是解决事情的另外一种方式,针对小问题的时候有点大才小用,问题复杂的时候就显得很轻松。面向对象是宏观上解决问题的方式。
比如:领导出游,司机开车。
领导和司机就是两个对象
领导:出钱,出车,管去哪
司机:开车。
3:区别和联系
面向对象和面向过程是相互依存的,人们思考问题是用面向对象的思维,最终去实现还是用面向过程。
在编码的过程中,存在一个需求,我们应先从宏观上去思考这个需求,再从微观上去解决问题。
人开门这个需求,人和门都是对象,要实现这个需求只需要人去调用开门这个功能即可。
面向对象四大特性
抽象【abstract】 : 是将一类对象的共同特征抽取出来构造类的过程,包括数据抽象和行为抽象两方面,抽象只关注对象的哪些属性【姓名,年龄】和行为【吃饭,睡觉】,并不关注这些行为的细节是什么【吃的什么饭】 - 举例:定义一个person类,就是对人这种事物的抽象。
封装【private】**:【类的行为和属性 与其他类的关系】====封装工具类
封装定义:
封装就是将代码封装起来,对外界隐藏了类的内部实现机制,只是给外界的提供他的访问【getXxx/setXxx方法】方法。
封装的作用:
1.保护我们的代码或防止代码被随意的修改和访问,保证数据的完整性。
2.封装增加了代码的可维护性以及可重用性,不需要去该类修改客户代码
3.使用封装可以隐藏实现的细节,使用者只需要如何使用,不需要知道过程。
继承【extends】**:【子类和父类的关系、其实也是类与类】**
继承定义:子类继承父类【对父类中的属性和行为(方法)】进行继承,并且可以扩展新的能力(属性和行为)。
继承的作用:增加代码的复用性,避免代码冗余。【直接继承父类 可以使用父类的属性和方法【就不用再去子类中写重复的代码,导致代码冗余,可读性差】】;
多态:【类与类的关系】
多态的定义:当不同的对象去完成相同的行为【即方法】时会产生出不同的状态【当多个类实现了同一个接口,并对接口中的方法进行重写,在执行类的方法时就会出现不同的结果。】。
实现多态的三个条件:
1-继承
2-重写方法
3-向上转型【父类引用指向子类对象 Animal a = new Dog();】
(如果需要访问子类的特有方法就需要向下转型 Dog d = (Dog)a;)。
注意:
成员方法:编译看左边【父类中有没有这个方法】,执行看右边【子类】
成员变量:编译看左边【全是父类】,执行看左边】
多态的作用:
增加了代码的可移植性,健壮性,灵活性
多态的含义、多态的作用及多态的详细代码实现_GuGuBirdXXXX的博客-CSDN博客_多态的含义和作用
为什么这些面向对象的特征能够帮助我们**写出更好的代码呢????【关键+加分项** 】
封装:封装好了的代码就可以重复进行使用【增加了代码的复用性】,并且提高了开发效率【不用每次都去写】
继承:实现了代码的复用性,避免代码冗余。
多态:增加了代码的可移植性,健壮性,灵活性
名词解释:
可移植性:指当条件有变化时,程序无需作很多修改就可运行【使改写程序变得轻易】。
健壮性:就是一个程序很健壮,出现一些小的异常也能够继续执行下去,不会造成down机。
灵活性:指在添加新代码的时候,已有代码能够不受影响,不产生冲突,不出现排斥,在保证自身不遭到破坏的前提下灵活地接纳新代码。
方法重写和重载
Overload:
重载【方法名相同就行,返回值不管】,方法名相同形参列表不同【顺序、个数、类型】。
Override:
重写【啥都相同】,方法名相同,参数列表相同,返回值相同。
重写是子类对父类的方法进行重新编写, 返回值和形参列表都不能改变,方法体可以进行重写【可以理解为扩展】。即外壳不变,核心重写(语句体内容进行重写),当父类的行为不能满足子类需求的时候,子类就重写父类的方法。(子类可以既继承了父类的属性和方法,也可以有自己的独有属性和方法)
构造方法可以被重载但不能被重写。(无参构造和有参构造方法就是方法重载,这样在创建对象的过程中就可以有多种方式创建带参对象)。
为什么构造方法不能被重写?
因为重写发生在父类和子类之间,要求方法名称相同,而构造方法的名称是和类名相同的,而子类类名不会和父类类名相同,所以不可以被重写。
普通类和抽象类
普通类:可以实例化对象(与抽象类最大的区别)
抽象类(abstract):
抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
抽象类的最大作用就是为了被子类继承【就是一些方法只想让子类进行执行】。

final修饰的类,为最终类,该类不能被继承。如String 类
final修饰的方法可以被继承和重载,但不能被重写【final修饰了就不可变了】
final修饰的变量不能被修改,是个常量【不可变】
为什么要使用抽象类?
就是一些特定的工作不需要父类完成,而该由子类进行完成,如果不小心误用父类,使用普通类是不会报错的,但是抽象类在实例化对象时就会报错,让我们尽早发现问题。
没有实际工作的方法, 我们可以把它设计成一个 抽象方法(abstract method), 包含抽象方法的类我们称为 抽象类(abstract class)。
接口和抽象类
接口interface:
1.由interface关键词修饰的称之为接口;
2.接口中可以定义成员变量,但是这些成员变量默认都是public static final的常量。
3.接口中没有已经实现的方法,全部是抽象方法。
4.一个类实现某一接口,必须实现接口中定义的所有方法。
5.一个类可以实现多个接口。6.JDK1.8后,有静态方法,还有default方法(default方法作用)】和成员变量【全局常量】
抽象类abstract:
1.由abstract关键词修饰的类称之为抽象类。
2.抽象类中没有实现的方法称之为抽象方法,也需要加关键字abstract。
3.抽象类中可以有已经实现的方法,可以定义成员变量。4.类继承了抽象类必须重写抽象方法,如果也是抽象类可以不写。
加分项:
接口和抽象类除了在语法上的区别还有在语义上的区别
语义:什么时候用接口interface,什么时候用抽象类abstract?
抽象类:描述在我们心中形成了一种概念。---建议使用抽象类(动物,植物.....)
接口:描述某些事物之间所具有的共同特征。---建议使用接口(flyable 会飞的 【飞机会飞,鸟会飞....】)你要具备这个能力就必须实现这个接口 【比如支付宝定义的接口,你需要用他的支付功能,你就需要去实现他的接口】
IO流
你知道BIO,NIO,AIO么?
IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。
BIO (Blocking I/O):同步(操作)-阻塞I/O(线程)模式 ,以流的方式处理数据,一个连接对应一个线程,数据的读取写入必须等待另一个线程完成。适用于连接数目比较小且固定的架构。
NIO (New-[non-blocking] I/O):同步-非阻塞模式,以块的方式处理数据(面向缓冲区),适用于连接数目多且连接比较短【client和server每进行一次报文收发才进行通讯连接,交易完毕之后立即断开连接,常用于一对多通讯】(轻操作)的架构,比如聊天器
非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情
AIO ( Asynchronous I/O):异步-非阻塞I/O 模式,适用于连接数目多且连接比较长(长连接-client方与server方建立连接后,连接建立不断开,然后再进行报文的收取和发送,这种通讯连接一直存在,这种方式常用于P2P通信(peer-to-peer)的架构,比如相册服务器------P2P(对等网络是一种短暂的internet网络,它允许具有相同网络程序的一群计算机用户相互连接,并且直接访问一个硬盘驱动器中的文件**)
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。

Java 中四大基础流
InputStream : 字节输入流(读数据)
OutputStream: 字节输出流(写数据)
Reader: 字符输入流(读数据)
Writer: 字符输出流(写数据)
读文本用什么流,读图片用什么流
读文本使用使用字符输入流Reader,也可以用字节输入流,但是读取的时候要将字符转换成字节,效率比较低,所以最好使用字符输入流进行读取。也可以使用缓冲字符输入流将字符输入流包装起来,一次读取一个字符数组,提高读取效率。
读取图片使用字节输入流InputStream,字节输入流可以读取任何类型,会将所有类型转换成二进制进行读取,可以使用字节缓冲输入流BufferInputStream包装字节输入流,一次读取一个字节数组提高读取效率。
字符流写数据会先放在缓冲区,只有调用flush或者close关流【close方法中包含了flush】,才会将缓冲区的数据写出去。
而字节流是直接输出的,没有关流(close)之前已经将数据读取出去了,调用close方法只是为了释放资源,避免一直占用。
字符流和字节流有什么区别
InputStream OutputStream
字节流的按照字节进行读取数据,一次读取一个字节(byte),相当于8位二进制,适用于读取任何类型的文件,
字节流可分为字节输入流和字节输出流,为了提高读取效率,又出现了缓冲字节输入流和缓冲字节输出流(一次读取一个字节数组,从而提高读取效率)
Reader Writer
字符流的按照字符进行读取数据,一次读取一个字符(char),相当于16位二进制,适用于文本类型,
字符流可分为字符输入流和字符输出流,为了提高读取效率,又出现了缓冲字符输入流和缓冲字符输出流(一次读取一个字符数组,从而提高读取效率)
BufferedInputStream(缓冲字节输入流) 用到什么设计模式
主要运用了俩个设计模式,适配器和装饰者模式
装饰器模式(Decorator )
允许向一个现有的对象添加新的增强功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
适配器模式(Adapter)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能【USB接口】
常用设计模式+代理模式【Design Pattern】【我终于懂设计模式了】_GuGuBirdXXXX的博客-CSDN博客
怎么实现一张图片拷贝
需要一个FileInputStream文件字节输入流指向读取的文件,然后把它包装到BufferInputStream缓冲字节输入流【创建一个内部缓冲区数组】,使用BufferInputStream的read方法去读byte[]字节数组,然后创建一个FileOutputStream指向输出文件写数据,然后把它包装到BufferOutputStream,使用BufferOutputStream的write方法写byte[]到另外一个文件

怎么实现文本拷贝
和文件拷贝思路一样,只不过读的时候需要使用BufferedReader和FileReader,使用readline方法来读 , 写的时候需要BufferedWriter和 FileWriter,用wite来写
