【单细胞高级绘图】09.细胞通讯_两组比较_连线图
上周一位读者联系我,让我帮忙发一个绘图的单子。在朋友圈发单后,感兴趣的朋友很多,有十几位还私聊我让我分享一下代码,可见大家还是很感兴趣的。不过等了两天,依旧没有勇士接单,可能是因为这种图比较少见,大家画得少。
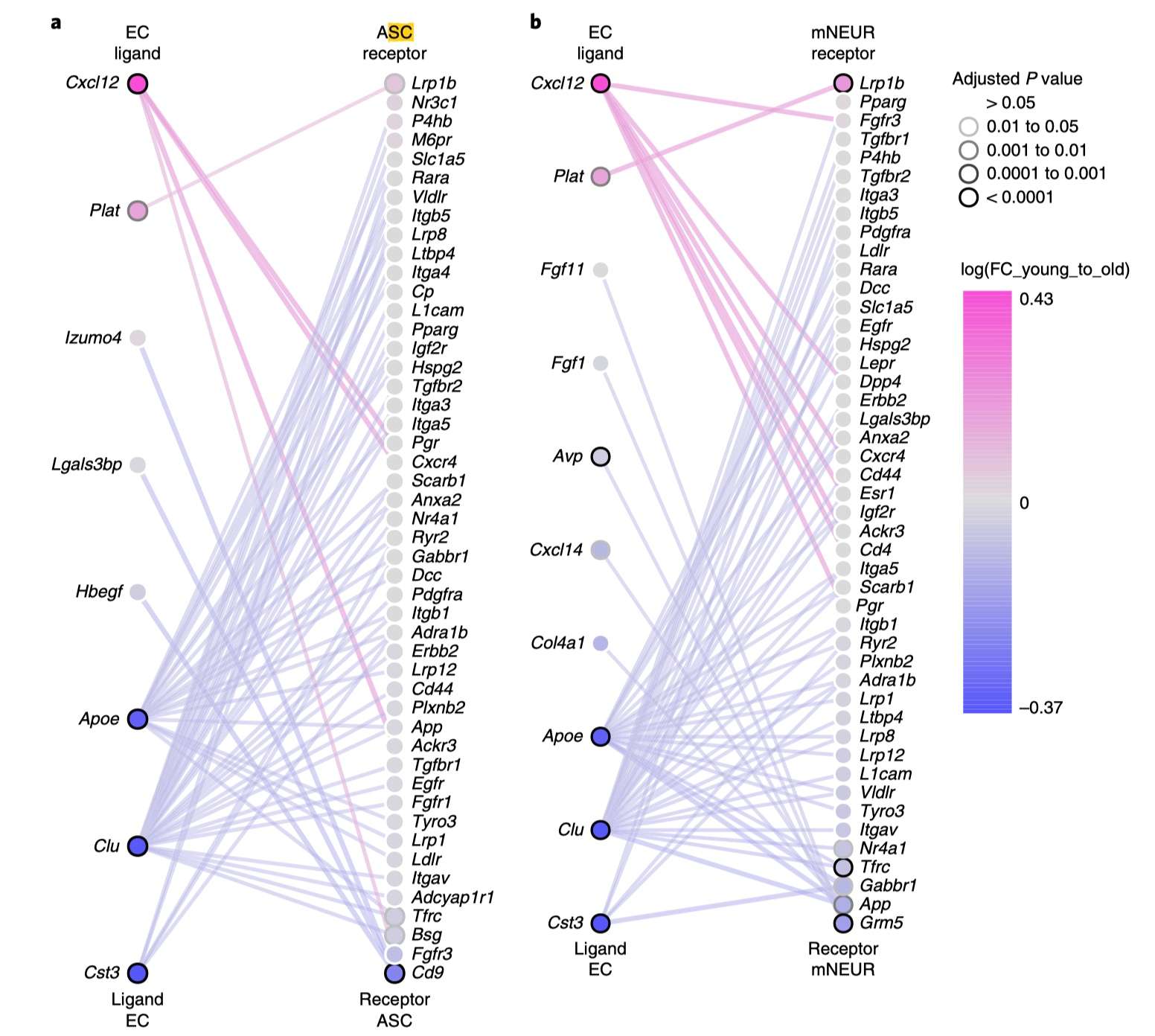
先来理解一下这张图,在b图中:
-
左边是 EC细胞表达的ligand,右边是mNEUR细胞表达的receptor。 -
ligand这一列对应的基因会排序,依据是 「两个group」(比如young和old两组)在EC细胞中找完差异基因后,能知道这些基因的log(FC_young_to_old),从大到小依次往下排,并涂色。同时,找差异基因也能知道p值,原文表示显著性用的是圆环的颜色,越显著,圆环颜色越深。 -
receptor这一列类似ligand列,不过是在mNEUR细胞中,两组之间找差异基因。 -
图中的线段,表示 ligand-receptor对,而这个信息(谁和谁构成受配体)是已知的,数据库可以下载到(也就是说,这个图即便不做细胞通讯分析,只要能下载到ligand-receptor信息,也能画)。cellphonedb的输出结果也间接含有这个信息,我的代码基于这个。 -
至于连线的颜色,我看了一下,没怎么变化,所以我推测线段的颜色取决于线段两侧ligand-receptor是高表达还是低表达,高表达时线段用浅红色,低表达时线段用浅蓝色。
以上解读均为我的理解,我没有看原文。我的图会略作更改,下文会说。
另外,因为一些互作关系没法用一个ligand一个receptor去表示,这样的pair不适合用这个图展示。
此篇推文的代码一共有3个:CCC_compare2.R、CCC_line.R、CCC_line2.R。每个代码都能出一张有意义的图。
准备数据
source("CCC_compare2.R")
CCC_compare2(group1.name = "Old",group2.name = "Young",
group1.pfile = "cellphonedb/Old/pvalues.txt",group1.mfile="cellphonedb/Old/means.txt",
group2.pfile="cellphonedb/Young/pvalues.txt",group2.mfile="cellphonedb/Young/means.txt",
p.threshold = 0.05,thre=0.5,
cell.pair="EC|APC", #指定ligand产生的细胞|receptor产生的细胞
plot.width=15,plot.height=30,filename = "test3_"
)
前几行代码跟上一节是类似的,也能输出一个表格(test3_Old2Young.xlsx)和对应的气泡图。 后续的连线图基于这个表格的数据。
连线图有个特点,就是"谁是ligand,谁是receptor,ligand和receptor分别由什么细胞产生"非常明确,CCC_compare2.R这个代码比CCC_compare.R (在上一节)增加一百多行去理清这个事情,输出的图和表格pair左边的就是ligand(产生的细胞),右边的就是receptor(产生的细胞)
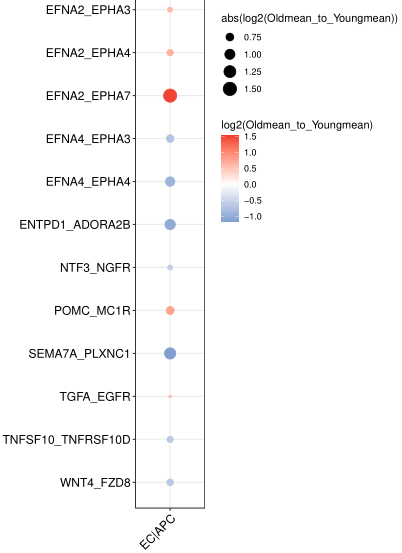
连线图的绘制 第1种方法
source("CCC_line.R")
CCC_line(table.path="test3_Old2Young.xlsx",ligand.cell="EC",receptor.cell="APC",
group1.name = "Old",group2.name = "Young",#这五个参数和上一步对应
ligand.color="#4dbbd6",receptor.color="#90d1c1",
pt.size=6,
line.thre1=0.5,line.thre2=6,#line.thre1和上一步的"thre"参数一致,line.thre2可以用来调整线的粗细,值越大,线越细
file.name="test3_",plot.width=25,plot.height=20)
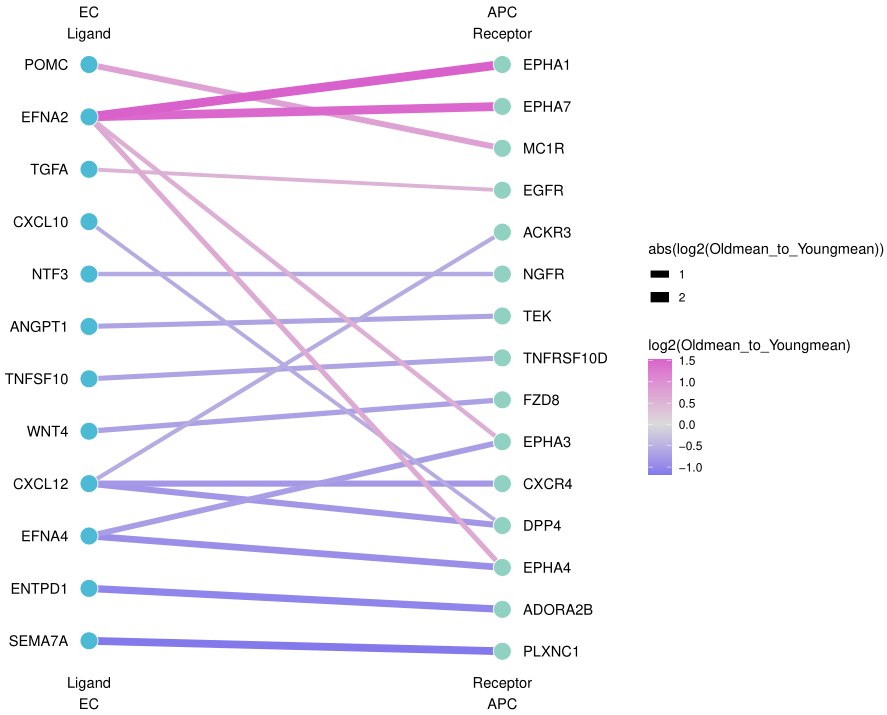
第一种方法不涉及差异基因,因此左右两列是统一的圆点。线段粗颜色红,表示(相较于group2)group1的互作强;线段粗颜色蓝,表示(相较于group2)group1的互作弱。
连线图的绘制 第2种方法
library(Seurat)
testseu=readRDS("testseu.rds")
# 此次演示为了加快运行速度,人为减少了数据量,实际分析中找差异基因不建议这么做
selectedCB=sample(testseu@meta.data$CB,1000)
testseu=testseu%>%subset(CB %in% selectedCB)
# 基于分组找差异基因
marker_group=data.frame()
Idents(testseu)="celltype_age"
for ( ci in c("EC","APC") ) {
tmp.marker <- FindMarkers(
testseu, logfc.threshold = 0, min.pct = 0.01,
only.pos = F, test.use = "wilcox",
ident.1=paste0(ci,"_Old"),ident.2=paste0(ci,"_Young")
)
tmp.marker$gene=rownames(tmp.marker)
tmp.marker$cluster_group=ifelse(tmp.marker$avg_log2FC > 0,paste0(ci,"_Old"),paste0(ci,"_Young"))
tmp.marker$cluster=ci
tmp.marker=tmp.marker%>%arrange(desc(avg_log2FC))
marker_group=marker_group%>%rbind(tmp.marker)
}
#本次演示的数据集为小鼠数据集,在运行cellphonedb时,进行了基因symbol的转换。
#此处找差异基因得到的symbol为真实基因名,为了让两个分析匹配,DEG表格也应该做基因名转换。
#但是为了简化,此处只是简单地将小鼠基因名转为大写,不是很精确。大家在分析的时候建议严格一点。
marker_group$gene=marker_group$gene %>% toupper()
第二种方法需要不设置筛选条件去找差异基因,然后用CCC_line2函数就可以了
source("CCC_line2.R")
CCC_line2(cpdb.table.path = "test3_Old2Young.xlsx",marker_group = marker_group,
ligand.cell = "EC",receptor.cell = "APC",
group1.name = "Old",group2.name = "Young",
line.size = 2,file.name = "test3_",plot.width = 25,plot.height = 20
)
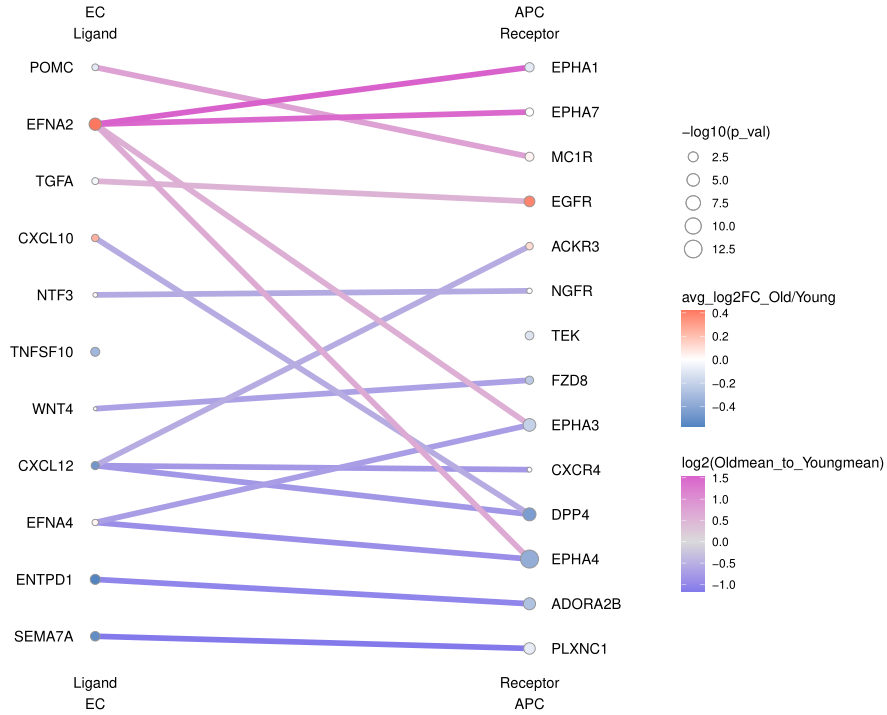
这种方法得到的图,左右两列添加了差异基因相关的信息,p值、log2FC。线段的粗细固定了,线段的颜色表示(相较于group2)group1的互作强弱。
本文代码编写(3个函数)花费大量时间,故不无偿提供,有需要的朋友可以后台回复2022B