编程的基础知识
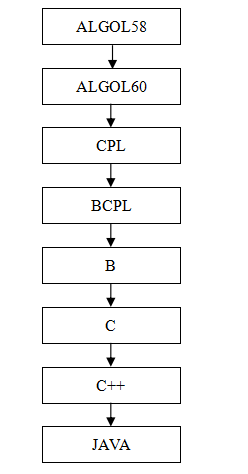
c的发展历史
void 类型


程序的入口成了**_tmain(),这个和 VC6.0 中的 main 函数类似, 在前面加个 t**,是为了对 unicode 项目的设置兼容,但它们都是程序执行的入口,其中 int argc 是程序的参数个数,_TCHAR* argv[]是参数数组。
**程序的编译与链接,**PE 格式
一个完整的 PE(Portable Executable)文件由 DOS 头,PE 文件头,块表,块 和**调试信息(调试版本有效)**组成
在 DOS 头部,以 e_magic 开头,它的值是固定的”0x5a4d”,即(MZ)开头。最开头的 是部分是 DOS 部首,DOS 部首由两部分组成:DOS 的 MZ 文件标志和 DOS stub(DOS 存根程序)。之所以设置 DOS 部首是微软为了兼容原有的 DOS 系统下的程序而设立的。

系统与程序的内存布局
在我们开始内核调试之前,首先我们需要对系统的内存内核层与应用层的布局有一个基本认 识。以 X86 为例,X86 支持 32 位寻址,因此可以支持最大 2^32=4GB 的虚拟内存空间(当然 也可以通过 PAE 将寻址空间扩大到 64GB,PAE 即 Physical address extension,x86 的处理器增加了额外的地址线以选择那些增加了的内存,所以实体内存的大小从 32 位增加到了 36 位。 最大的实体内存由 4GB 增加到了 64GB)。如下图所示,在 4G 的虚拟地址空间中,Windows系统的内存主要分为内核空间和应用层空间上下两部分,每部分各占约 2GB,其中还包括了 一个 64KB 的 NULL 空间以及非法区域,虚拟地址再通过页表机制映射到物理地址以便存取物理内存中的数据和指令。
X64(AMD64)的内存布局与 X86 的内存布局类似,不同的地方在于各自空间的范围和大小不同,同时 X64 下还存在着一些空洞(hole**)。在 X64 内存理论上支持最大 2^64的寻址空间,但实际上这个空间太大了,目前根本用不完,因此实际上的 X64 系统一般都只支持到 40多位(比如Windows支持44位最大寻址空间为16TB**,Linux 支持48位最大寻址空间256TB 等),支持的空间达到了 TB 级别。但是,无论是在内核空间还是在应用层空间,这些上 TB的空间并不都是可用的,存在着所谓的空洞(HOLE)。



Bit 与 Byte
1byte=8bit
1 个 bit 只能存储 2 个信息:0,1
1 个 byte 能存储:2^8-1 个信息:【****-128,127】or【0,255】
数据存储位置:寄存器,内存,磁盘等

整数的编码与存储
整数包括负数,零,和正数。计算机中的整数分为有符号数和无符号数。有符号数的最高位表示符号:即最高位为 0,表示正数,最高位为 1,表示负数。无符号数表示非负数,整个位数都用来表示整数的值。 如果用 N 位来表示整数,那么有符号数的范围为: [-2(N-1),(2(N-1))-1];无符号数的表示范围为[0,(2^N)-1]。比如,用 8 位来表示有符号整数,由于第 8 位用于表示了符号,因此,整数的表示范围为**[-128,+127];如果是表示无符号整数,则表示范围为[0,255]**。
整数的编码
整数的编码分为原码、反码、和补码。计算里使用的是补码的存储方式。
对于 8 位整数来说,补码的表示范围为[-128, 127]
那么有了原码,计算机为什么还要用补码呢?
补码的设计目的是:
⑴使符号位能与有效值部分一起参加运算,从而简化运算规则。
⑵使减法运算转换为加法运算,进一步简化计算机中运算器的线路设计。
此外,在补码中用-128 代替了-0,所以没有+0 和-0 之分,符合常理,所以补码的表示范围
为: -1280127 共 256 个。
注意:-128 没有相对应的原码和反码,-128 的补码为:10000000
整数的存储
整数的存储分为高位优先存储(big-endian)和低位优先存储(little-endian)
高位优先存储:高位首先存在低地址。
低位优先存储:低位首先存在低地址。
假设一个 32 位整数的值为 25000。25000 的补码为: 0x000061a8,共 4 个字节(注意到, 在十六进制中,2 个数为一个字节),其中最左边的 00 是最高位,然后依次为 00 次高位, 61 次低位,a8 低位。 那么在内存中如何存放这 4 个字节呢?也就是内存中的低地址是优先存放最高位还是最低位呢? 下图是这一个整数的低位优先和高位优先的存储实例:
在上图中,高位优先的系统中,会优先把高位的 00 存放在低地址;而低位优先的系统正好 相反,将低位 a8 优先存放在内存中的低地址。
如何判断一个系统是低位优先或者高位优先?首先,来看整数 1 在高位优先和低位优先的系统中的存储。
给出下面 2 种判断方法的代码:
//第一种方法: bool is_integer_lower_store() { int x = 0x1; char *p = (char *)&x; if (*p == 1) return true; else return false; } //第二种方法: typedef union { char c; int a; } U; bool is_integer_lower_store() { U u; u.a = 1; if (u.c == 1) return true; else return false; }在这两种判断方法中,都利用了 0x01 在低位优先中最低字节值为 1,在高位优先中最低值 为 0 的特性。用一个指向字符的指针就可以获得 int 整数的第一个字节。获得了第一个字节的值,就可以根据上面的特性来判断出系统究竟是低位优先还是高位优先。



题目:设计一个算法,改变一个整数的存储方式,即低位优先<–>高位优先
int change_int_storage(int val) { int iRun = 0, i = 0; char* pByte= (char*)&val; //指向整数的低地址,取一个字节 i = sizeof(int)-1; while (i >= 0) { //把整数的第 1 字节,第 2 字节,第 3 字节,第四 4 字节一次左移 24 位,16 位,8 位和 0 位 iRun |= *pByte<<(i*8); pByte++;//前进一个字节 i--; } return iRun; }
网络字节序
由于现实的系统中,不同的系统采取的整数存储的方式不一样,有的使用的是低位优先,有 的使用的是高位优先存储方式。 那么将一个整数值,通过网络从一台机器发送到另外一台机器之后,整数的存储方式可能就变了。
因此,为了使得整数在传输的过程中保持值不变,需要定义一个网络字节序和本地字节序。 也就是,把一个整数传输到网络的时候,统一转化为网络字节序。当这个整数通过网络传输到对方本地之后, 再统一把网络字节序转化为对应的本地字节序。 实际上,网络字节序是高位优先存储方式。而到达对方系统之后,再根据对方使用的整数存储方法,转化为对应的本地字节序。
比如网络上有 2 台机器,一个整数 0x12345678,从一台系统中使用的是低位优先存储,传输到另外一台使用的是高位优先存储方式的机器中。 那么整数的传输为:
本地字节序:0x78563421–>网络字节序:0x12345678–>本地字节序:0x12345678
在实际的网络编程中,我们一般使用 htonl()来实现本地字节序到网络字节序转换; 使用 ntohl()来实现从网络字节序到本地字节序的转换。
进制转换
在计算机里,最基本的存储单位为字节(Byte**,常说的大 B**),1 个字节包含 8 位(bit**,常 说的小** b)。计算机的数据就是一个字节一个字节的形式存储在内存中。
内存的大小单位有 KB,MB,GB,TB 等,它们之间的关系是:
1KB = 1024B
1MB = 1024*1024B
1GB = 1024*1024*1024B
1TB = 1024*1024*1024*1024B
计算机存储单位一般用 B,KB,MB,GB,TB,PB,EB,ZB,YB,BB 来表示。
1KB (Kilobyte 千字节)=1024B
1MB (Megabyte 兆字节 简称“兆”)=1024KB
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB
1TB (Trillionbyte 万亿字节 太字节)=1024GB,其中 1024=2^10 ( 2 的 10 次方)
1PB(Petabyte 千万亿字节 拍字节)=1024TB
1EB(Exabyte 百亿亿字节 艾字节)=1024PB
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB
计算机中的数,是以二进制存在于内存中
10 进制转换为 16 进制 :先把 10 进制数转化为 2 进制数,然后再把 2进制数转化为 16 进制数。
比如,100 对应的二进制我们很快就能求出来是:1100100,把这个 2 进制按照 4 位为一个 单位进行转化,0110 0100–>64 所以对应的 16 进制为:0x64。