Windows环境单节点部署kafka最新版本3.2.1实战(超简单)
文章目录
- 1 简介及应用场景
- 2 下载安装
- 安装
- 配置
- kafka配置
- zookeeper配置
- 测试
- 3 客户端工具 kafka Tool
- 4 项目实战
- 4.1 maven依赖
- 4.2 配置文件
- 4.3 生产者推送数据
- 4.4 消费者订阅数据
- 5 小结
1 简介及应用场景
Kafka 是一个由 LinkedIn 开发的分布式消息系统,它于2011年年初开源,现在由著名的 Apache 基金会维护与开发。 Kafka 使用 Scala 实现,所以kafka发布的版本号通常含有两部分,例如kafka_2.12-3.1.0.tgz,其中,2.12为scala版本,3.1.0为kafka版本, Kafka 是基于消息发布﹣订阅模式实现的消息系统,具体实现原理参考官方文档这里不再冗余阐述。
我的应用场景:服务器上部署了两套软件,一个是负责日常事务处理的app应用,另一个是负责项目立项管理的springboot项目,为了方便用户随时查看是否有项目立项流程发起或者走到了哪个节点,项目立项这个软件需要把流程信息推送到kafka中间件,app订阅到相关消息后查询显示出来。下面讲一下具体的实现,这个功能是我在第一次接触的情况下,只用了一两天就搞定的,跟网上查到的资料相比有坑的地方会标红显示。
2 下载安装
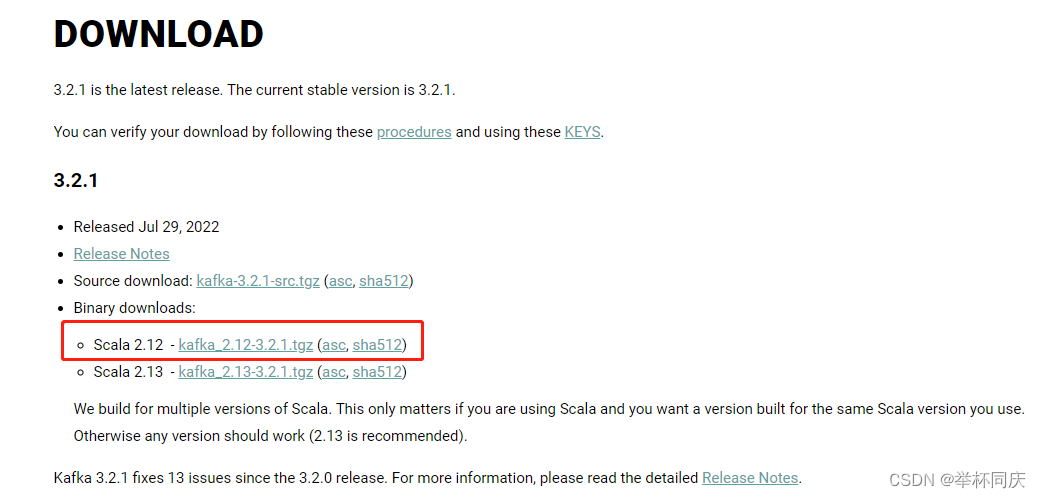
官网下载链接
我下载的是kafka_2.12-3.1.0.tgz 这个版本,应该是比较新的,可以兼容以前的旧版本。
安装
kafka只需要解压下载的压缩包就行了,我这里解压的路径是D:\kafka_2.12-3.1.0。
kafka的运行需要依赖zookeeper, kafka从2.8.0版本之后就内置了zookeeper.jar文件,用命令行启动即可,不需要单独安装zookeeper了
配置
想要启动kafka需要修改kafka配置文件和zookeeper配置文件,配置文件都在跟目录下面的config文件夹下。
kafka配置
kafka 服务端配置在server.properties文件中,这里需要修改两处配置:listeners 和 log.dirs
listeners:服务器监听的地址,修改如下:
listeners=PLAINTEXT://localhost:9092
log.dirs:日志文件修改为自定义的日志目录,我的是log.dirs=D:/kafka_2.12-3.1.0/logs
这里最好改一下,默认日志放在/temp路径,Linux环境因为临时文件夹temp不稳定的原因也需要改,Windows环境改到当前目录方便后面出现问题时删除日志重新启动
zookeeper配置
zookeeper配置文件为zookeeper.properties,只需修改一处:
dataDir:zookeeper存储数据的路径,Windows环境路径要用D:\\kafka3.2.1\\datas这种形式
我遇到了Kafka异常重启后提示错误:The Cluster ID XXXXX doesn‘t match stored clusterId Some(XXXXX) in meta.properties.
但我没有找到这个meta.properties文件,查了半天原因是log.dirs路径配置的不对
测试
接下来进入测试阶段:
1. 启动zookeeper
先启动zookeeper,进入kafka安装根目录下,地址栏输入cmd,然后回车,注意启动之后不要关闭窗口。启动命令如下:
本地:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
服务器要用绝对路径: start cmd /k D:\kafka3.2.1\bin\windows\zookeeper-server-start.bat D:\kafka3.2.1\config\zookeeper.properties
没有报错就可以了
2. 启动kafka服务端
同样进入kafka安装根目录下,地址栏输入cmd,然后回车,启动之后不要关闭窗口。启动命令如下:
启动kafka-server
本地:
.\bin\windows\kafka-server-start.bat .\config\server.properties
服务端:
start cmd /k “C:\EAMServer\kafka3.2.1\bin\windows\kafka-server-start.bat C:\EAMServer\kafka3.2.1\config\server.properties”
也是没有报错就算启动成功了,如果启动kafka失败,并出现以下异常,删除logs文件夹下的meta.properties文件即可。
The Cluster ID xxxx doesn’t match stored clusterId Some(finN2zUTRWaXMomXCknRew) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
3. 创建kafka-topics
启动zookeeper和kafka服务端这两个命令窗口是必需的,这里通过脚本创建topic通常是用于本地测试kafka服务是否能正常发布和接收消息(新手可以用脚本创建一下测测,用Java实现发送消息可自动创建topic)
同样进入kafka安装根目录下,地址栏输入cmd,然后回车,启动之后不要关闭窗口。假设创建一个名字为test的topic命令如下:
start cmd /k .\bin\windows\kafka-topics.bat --create --bootstrap-server 10.0.102.132:9092 --replication-factor 1 --partitions 1 --topic test
这里有坑:新版的主题通过kafka服务端创建即可,也就是 --bootstrap-server这个地址,网上好多资料都是旧版的连接zookeeper创建的,在新版可能报错
–partitions 1意思是建立一个分区,–replication-factor 1是配置一个副本,因为本文讲的是单节点服务所以默认一个分区,集群可设置多个。启动之后,kafka-topics处于等待创建topic状态,一段时间内如果不createTopic,kafka-topics将自动断开
- 启动生产者
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
启动生产者之后就可以发送消息了
- 启动消费者
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
启动消费者之后生产者发送的消息,消费者端就能收到了。
至此,消息队列kafka就安装完毕,完全可以通过命令行测试服务是否正常。
3 客户端工具 kafka Tool
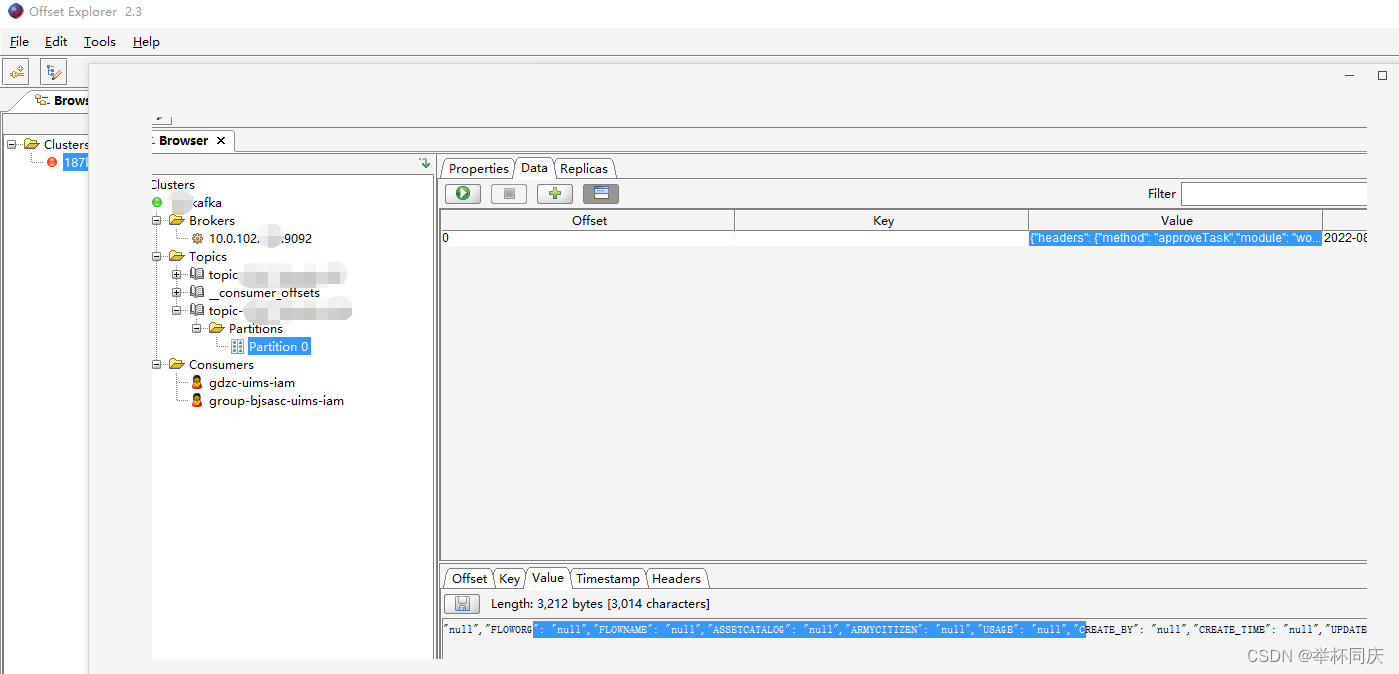
我用的是kafka Tool,下载下来的软件名字是Offset Explorer 2.3
用客户端工具看所有的Topic和接收的消息内容非常直观,实乃开发利器。
4 项目实战
4.1 maven依赖
<!-- kafka 消息队列 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.1</version>
</dependency>
4.2 配置文件
spring:
kafka:
bootstrap-servers: 10.0.102.132:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: am #群组ID
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
auto-offset-reset: earliest
enable-auto-commit: true
#如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
4.3 生产者推送数据
发送数据代码非常简单,开发人员基本上就关注怎么组装消息报文就行了,消息发送就一行代码:
@Autowired
KafkaTemplate kafkaTemplate; // 上面注入一个KafkaTemplate对象
... // 组装JSONData
kafkaTemplate.send(“test”, JSONData); // 直接用send方法,参数是topic名称和JSON报文数据,这行代码加到任何需要发送kafka消息的方法中
这里需要关注一个知识点:kafkaTemplate.send(“test”, JSONData)是kafka默认的异步消息发送,异步发送消息时,只要消息积累达到batch.size值或者积累消息的时间超过linger.ms(二者满足其一),producer就会把该批量的消息发送到topic中。
注:batch.size默认是16384,linger.ms默认是0,这两个参数可在springBoot项目配置文件中增加/修改。
同步发送消息时,需要在每次send()方法调用get()方法,因为每次send()方法会返回一个Future类型的值,Future的get()方法会一直阻塞,知道该线程的任务获取到返回值,即当消息发送成功。可在返回future类型后增加回调函数执行发送成功后的处理逻辑。
4.4 消费者订阅数据
订阅接收消息就是要加一个@KafkaListener注解,指定Topic主题和groupId(随意取,是为了区分订阅者是谁)
@KafkaListener(topics = "test", groupId = "am")
public void onMessage(ConsumerRecord<?, ?> record){
System.out.println("消费消息,record:"+record.topic()+"-"+record.partition()+"-"+record.value());
Optional<Object> kafkaMassage = Optional.ofNullable(record.value());
if (kafkaMassage.isPresent()) {
Object o = kafkaMassage.get();
logger.info("ConsumerController.groupId[gdzc-uims-iam]:" + o);
try {
Map<String, Object> res = JSON.parseObject(o.toString(), Map.class);
.......
} catch (Exception e) {
logger.error("KafkaConsumer error", e.toString());
}
}
}
5 小结
以上就是windows环境中单节点kafka中间件的配置实现过程,通过两端代码展示了发送消息和接收订阅消息的代码,实现超简单,看完本文就会使用了。具体kafka的实现原理和集群配置感兴趣的可以深入研究一下,后续我也可能会更新集群配置的文章,关注我吧。
