kafka学习总结
申明:
仅用于学习记录,参考资料在文末,若侵权,请联系我。
这篇文章将从以下几个方面了解kafka:
为什么使用消息队列?
消息队列的两种通信方式?
kafka?
基础架构及术语?
工作流分析?
背景
什么是消息队列?
kafka是一种消息中间件,在了解它之前,需要先了解一下什么是消息队列。
消息队列(Message Queue)[1]简写为MQ,可以简单将其理解成: 把要传输的数据放在队列中。
消息队列中间件主要解决应用解耦,异步消息,流量削锋, 消息通迅等问题, 从而实现高性能,高可用,可伸缩和最终一致性的架构。
生活中的场景: 快递员送快递到客户家,客户不在家或客户有事需要快递员等待,这样就降低了快递员工作的效率。所以现在小区或写字楼的楼下都建立了菜鸟驿站或蜂巢柜等,它们就相当于是消息队列。
消息队列的两种通信模式[2]:
1、点对点
点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理
生产者将消息放入消息队列后,由消费者主动地去拉取消息进行消费。
优点:消费者的消费频率由消费者自己控制
缺点:
但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
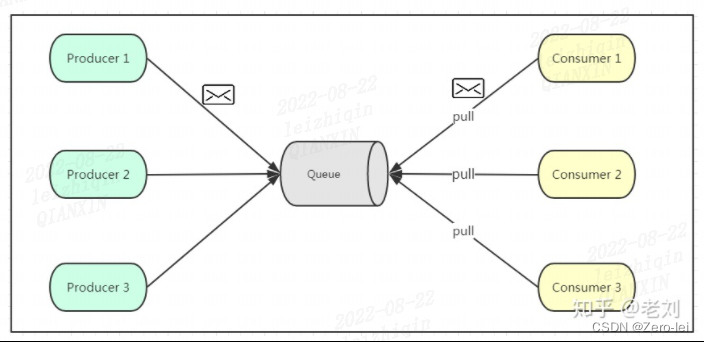
图片来自参考文章
2、发布订阅(类似于公众号,不用关注有没有消息,)
生产者:将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者。
消费者:被动接收推送。无法感知消息队列是否有待消费的消息。
缺点:消息队列无法感知消费者消费速度
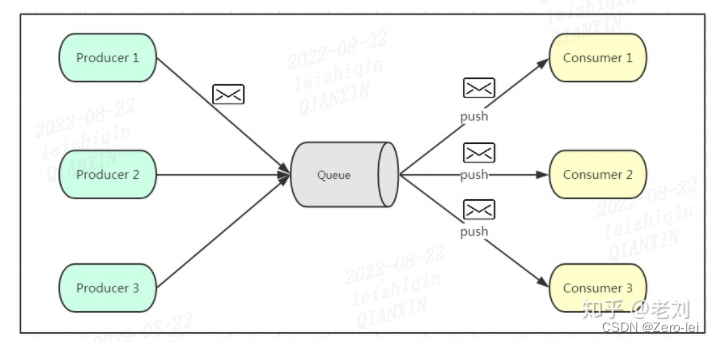
图片来自参考文章
那么kafka是一种基于发布/订阅的消息系统。
kafka
kafka的基础架构
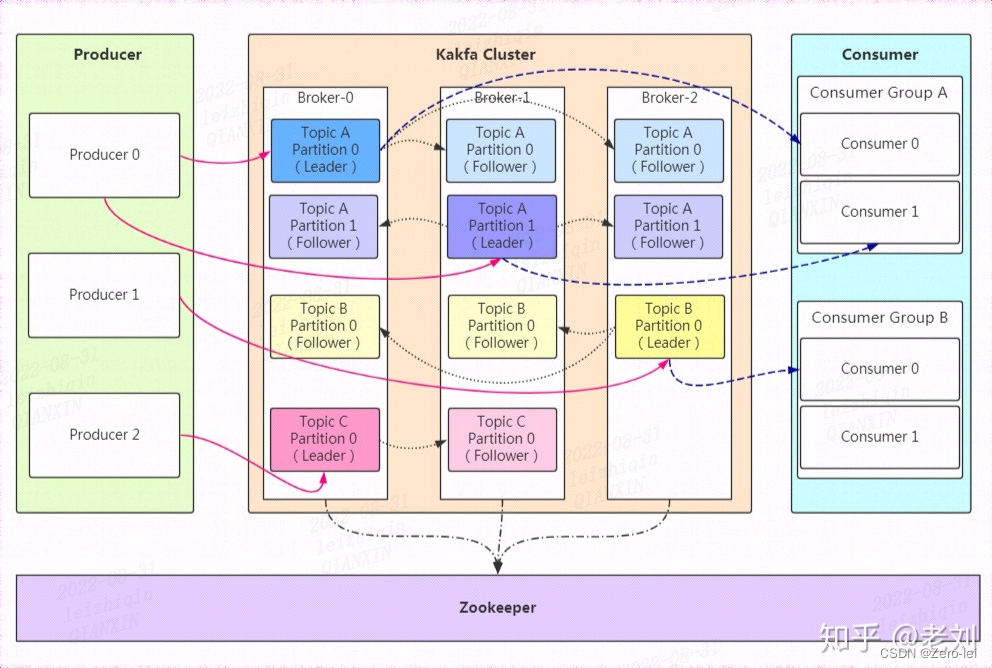
kafka的概念区分
概念一:
生产者(producer):消息的发布者,创建消息
消费者(consumer):消息的订阅者,负责消费或读取消息
概念二:
主题(topic): 消息通过主题分类,每个主题对应一个消息队列,对应一类消息。对消息分类,主题就像数据库中的表。【消息的存放格式为队列,类似于用户排队,先进先出,在主题中先产生的消息就先被消费】
分区(partition):分区是对主题的水平扩展,那么对于分区里面的消息。主题被分为若干个分区。同一个主体中的分区可以不在一个机器上,有可能部署在多个机器上。
目的:实现kafka的伸缩性
总结:
一个topic中的消息被打散存储在多个分区(partition)中:
partition: topic的分区,每个topic可以有多个分区,同一个topic在不同的分区的数据是不重复的。topic数据中的整体是所有分区之和。
kafka中采用分区的目的是什么?分区的目的是做负载,提高kafka的吞吐量
概念三:
Broker:可以看作为一个服务器
集群(cluster):
一个分区可以被复制到多个broker上来实现
概念四:
消费者与消费组:
消息的读取是针对消费组的,消费组在逻辑上可以等价于一个应用
consumer Group:消费者组,每个消费者组都有一个唯一的组id
1、同一个分区中的数据只能被消费者组中的某一个消费者消费。【消费者与分区对应】那也就是说,从topic分区来说,topic分区与消费者是一对一关系;从消费者来说,一个消费者可以消费多个分区。如下图所示,当消费者组中消费者个数与topic分区少时,一个消费者可以消费多个分区数据;当消费者组中消费者的个数与topic分区个数一样多时,一对一关系;当消费者组中消费者的个数比分区topic的个数多时,从前往后依次排队,后面的消费者空闲
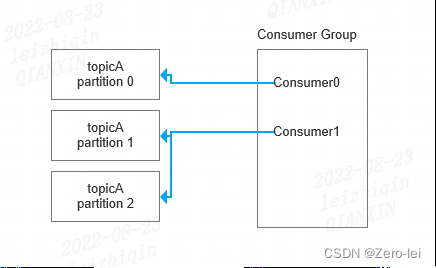
其他常用概念:
replication:副本。每个分区都有多个副本(Follower)。当主分区(Leader)故障时会选择一个Follower成为Leader。
要求:kafka中默认副本最大数量是10个,且副本的数量不能大于broker数据【可以将broker看做是服务器】
特点:Follower和leader绝对在不同的broker上,同一机器对同一个分区也只能存放一个副本(包括自己)
参考:
再过半小时,你就能明白kafka的工作原理了 - 知乎
消息队列(mq)是什么? - 知乎
学习 Kafka 入门知识看这一篇就够了!(万字长文) - 腾讯云开发者社区-腾讯云