Deep Reinforcement Learning with Double Q-learning(double DQN)
众所周知,流行的Q-learning算法在某些条件下会高估动作值。在实践中,这种高估是否常见,是否会损害性能,以及它们是否通常可以预防,这在以前并不为人所知。本文肯定地回答了这些问题。最近的DQN算法将Q-learning与深度神经网络相结合,在Atari 2600领域的一些游戏中受到了严重的高估。双q学习算法是在表格设置中引入的,其背后的思想可以推广到大规模函数逼近。本文提出了对DQN算法的一种特定适应,并表明所产生的算法不仅如假设的那样减少了观察到的高估,而且还在一些游戏上带来了更好的性能。
背景:
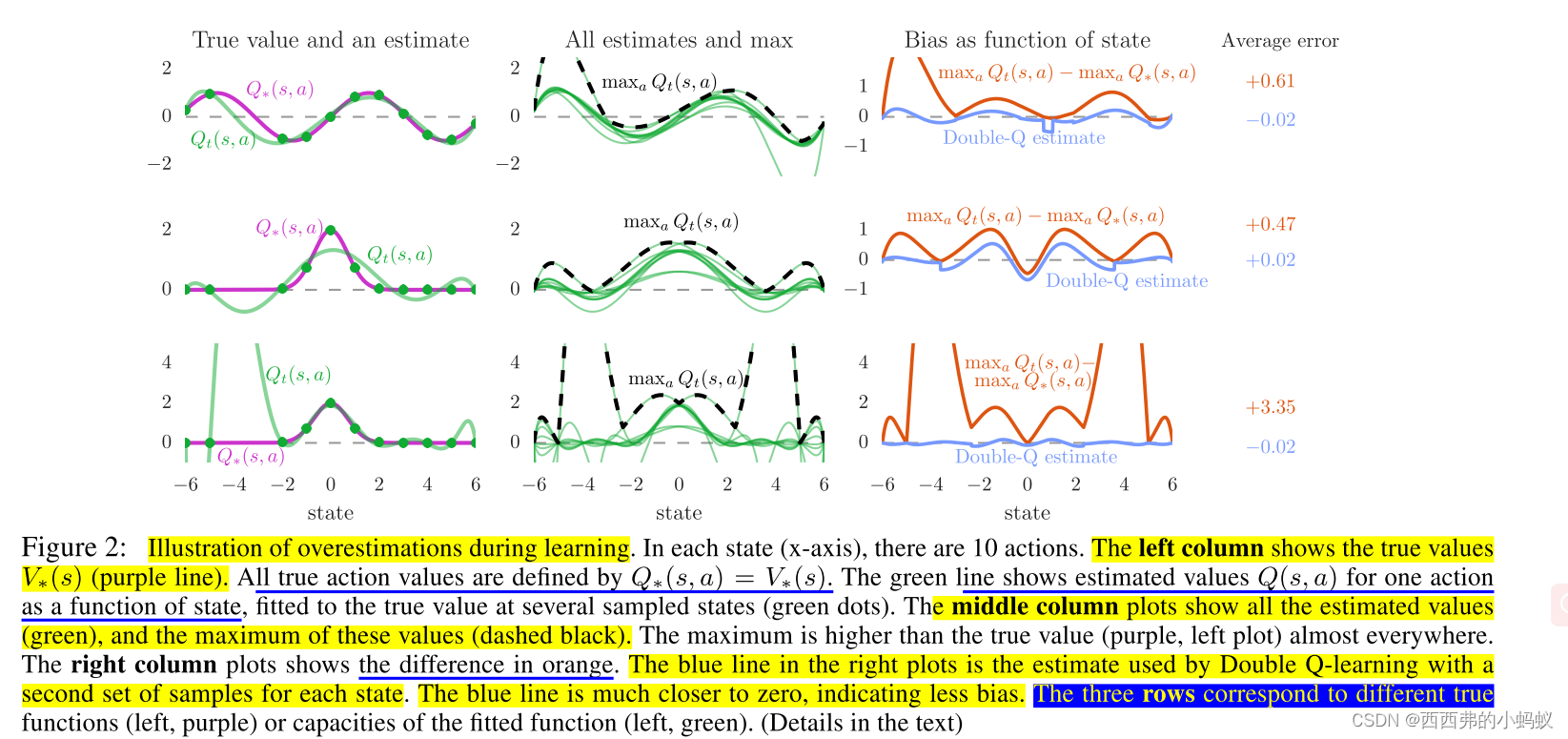
1)过高估计被归因于不够灵活的函数逼近(Thrun和Schwartz, 1993)和噪声(van Hasselt, 2010, 2011)。当动作值不准确时,无论近似值误差的来源如何,都可能出现高估。当然,不精确的价值估计是学习过程中的常态,这表明高估可能比之前认识到的更普遍。
2)我们用这个构造了一个新的算法,我们称之为双DQN。然后,我们展示了这种算法不仅产生了更准确的价值估计,而且在一些游戏中获得了更高的分数。
Double Q-learning
在原始的双q学习算法中,通过随机分配每个经验来更新其中一个值函数来学习两个值函数,这样就有两组权重,θ和θ
为了比较清楚,我们可以先理清Q-learning中的选择和评价,将其目标(2)改写为


Overoptimism due to estimation errors
Double DQN
双q学习的思想是通过将目标中的最大值操作分解为动作选择和动作评价来减少过估计。虽然没有完全解耦,但DQN架构中的目标网络为第二值函数提供了一个自然的候选网络,而无需引入额外的网络。因此,我们建议根据在线网络来评估贪婪策略,而使用目标网络来估计其价值。在提到Double Q-learning和DQN时,我们将由此产生的算法称为Double DQN。

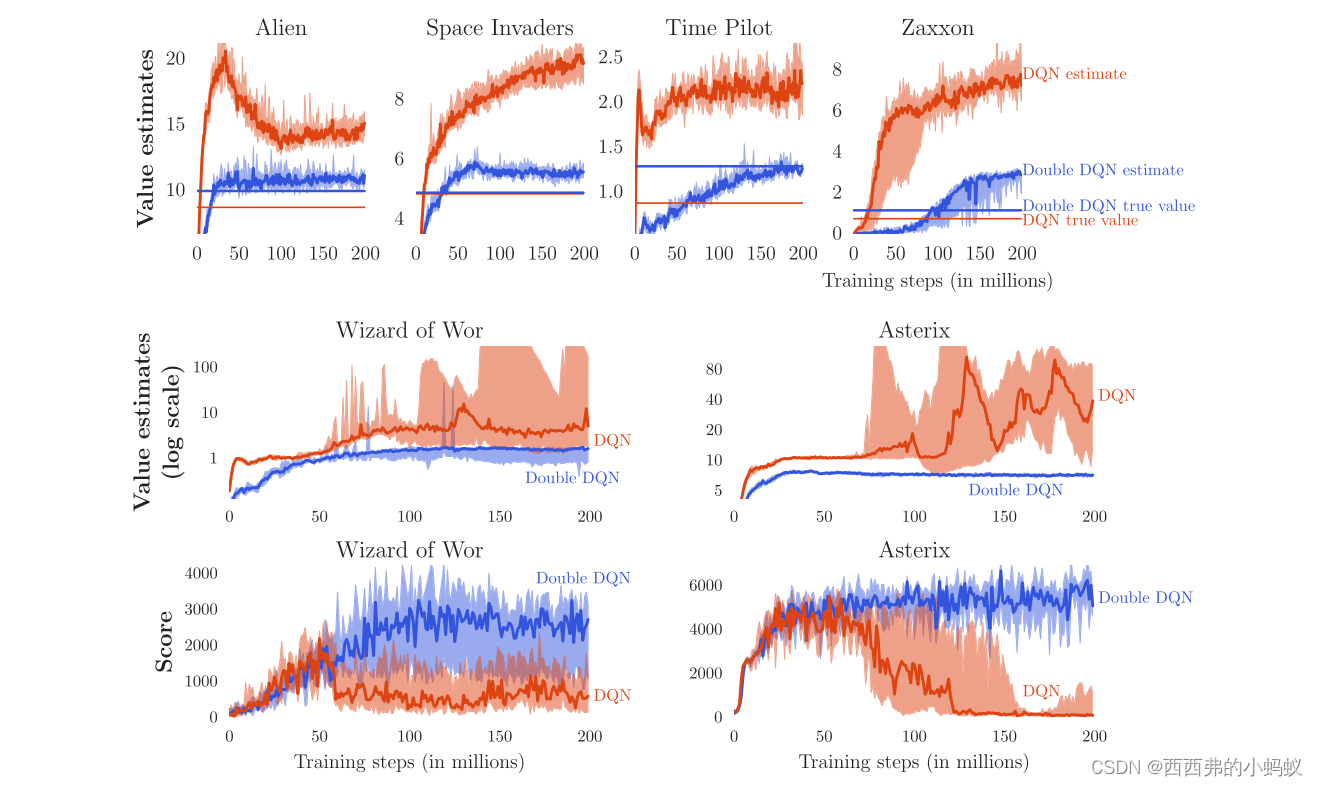
实验:

结论:
本文有五个贡献。首先,我们展示了为什么q学习在大规模问题中可能过于乐观,即使这些问题是确定性的,因为学习的固有估计误差。其次,通过分析Atari游戏的价值估计,我们已经表明,这些高估在实践中比之前承认的更常见和更严重。第三,双q学习可以大规模使用,成功地减少这种过度乐观,从而实现更稳定和可靠的学习。第四,我们提出了一种称为Double DQN的具体实现,它使用DQN算法的现有架构和深度神经网络,而不需要额外的网络或参数。最后,我们证明了Double DQN可以找到更好的策略,在Atari 2600域上获得了新的最先进的结果。