Pytorch 实战 LESSON 16 深度学习视觉入门 上
文章目录
- 深度视觉行业综述
- 卷积与卷积神经网络的基本元素
- Pytorch复现LeNet5与AlexNet
- 构筑自己的卷积神经网络

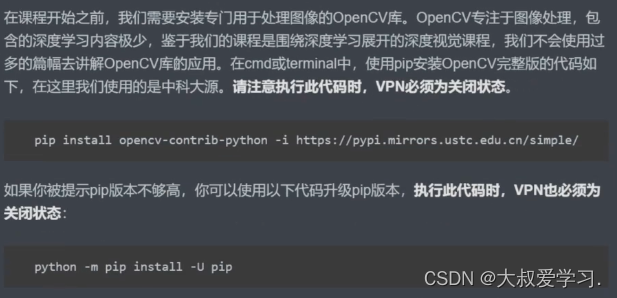
深度视觉行业综述



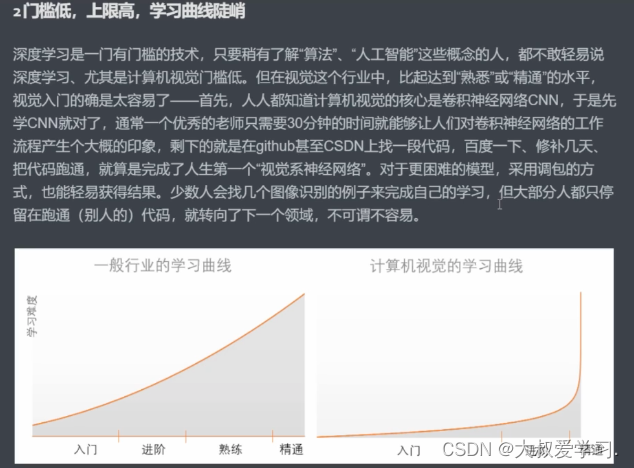




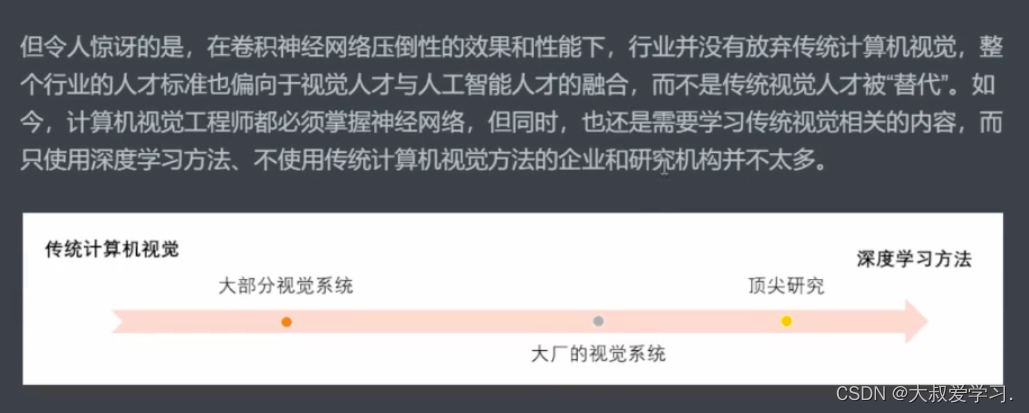


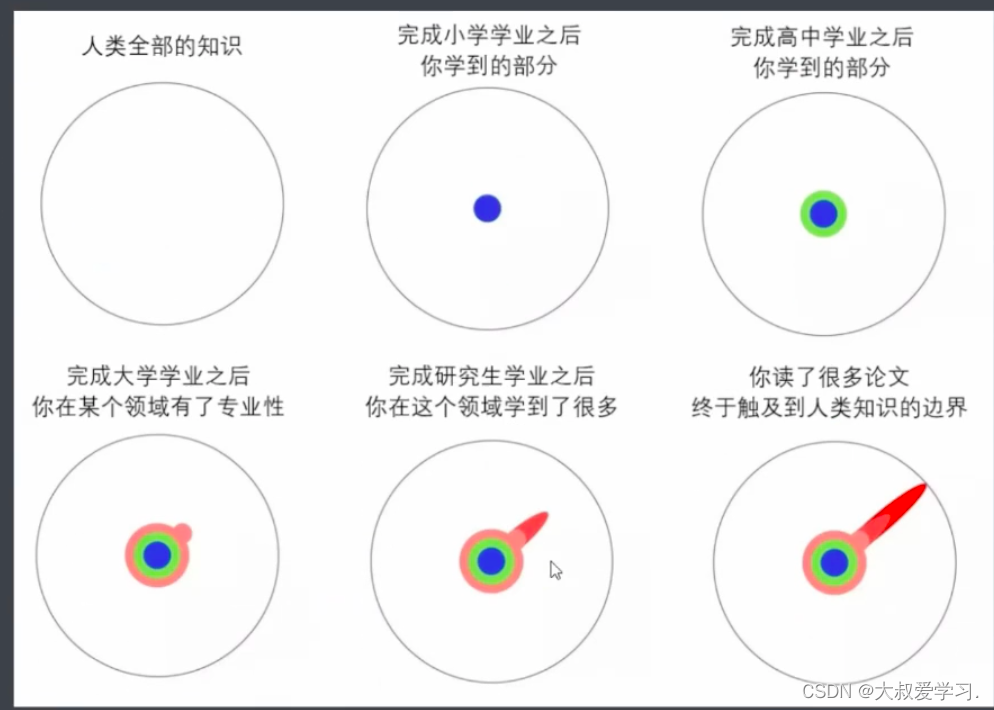








卷积与卷积神经网络的基本元素


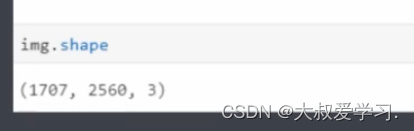
高度,宽度,通道数
通道数绝对色彩空间。



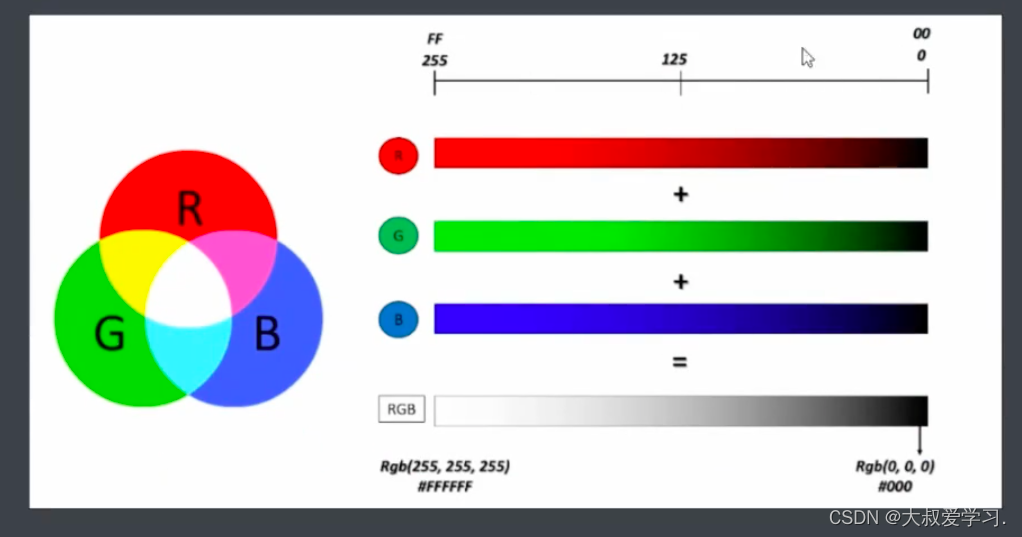
0-255.越接近0越暗。越接近255越接近颜色通道颜色本身。3个都是255,是纯白色。
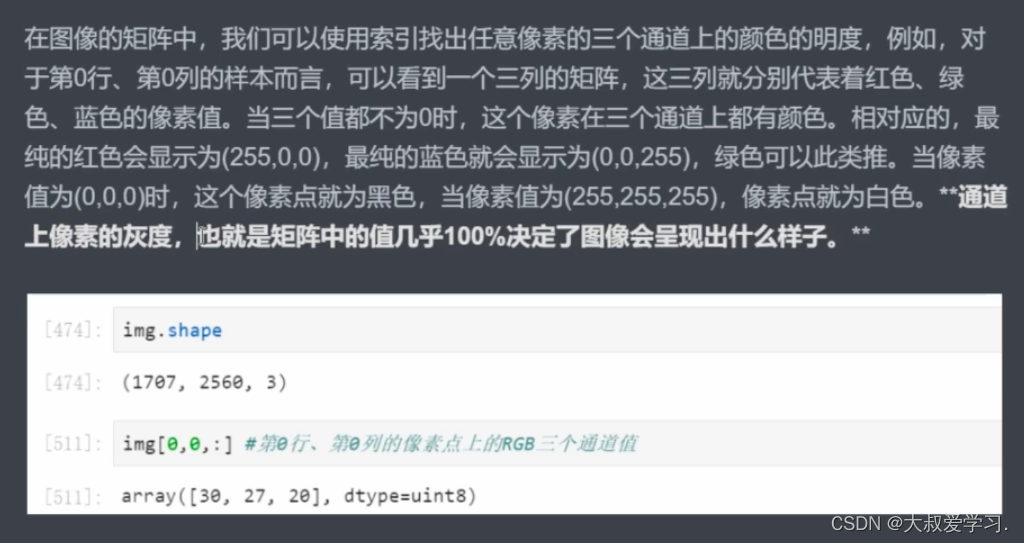
因为颜色的明亮程度不同,也就构成了图像的纹理不同。所以通道本身决定了图片的颜色和纹理等所有构成。





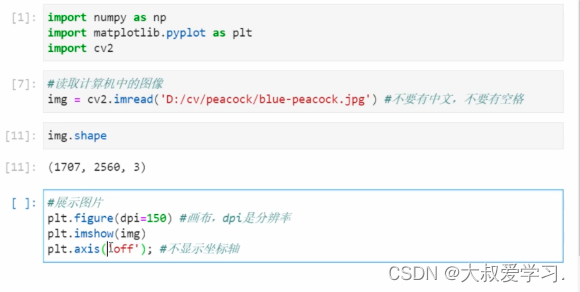

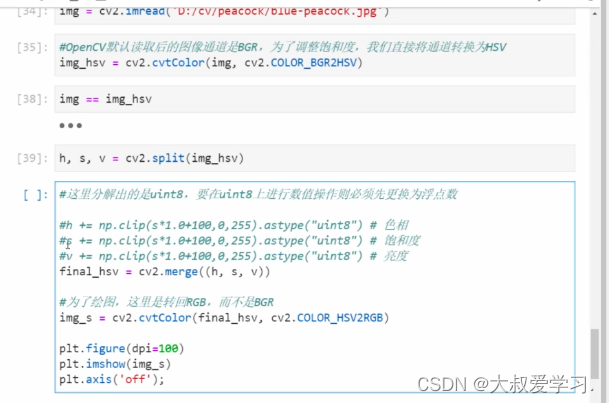
孔雀的颜色变了。因为opencv在读取图像,是BGR,不是我们以为的RGB。
#OpenCV默认读取后的图像通道是BGR,因此我们需要将图像的通道顺序转换为RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)

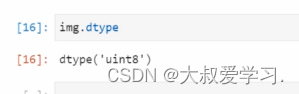
uint8限制像素是0-255.
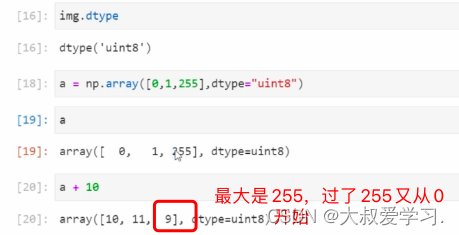
255+10->9这不符合常识,255不能再亮了之后,不是让它变黑。所以我们需要调整它。通过先将像素转成float,然后用np.clip限制。
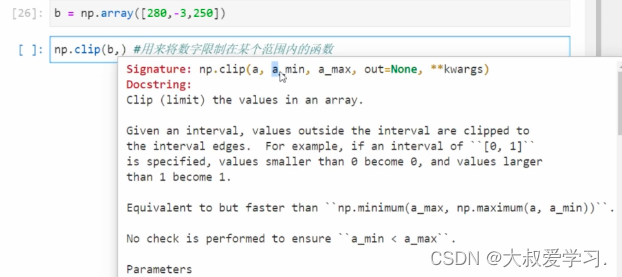
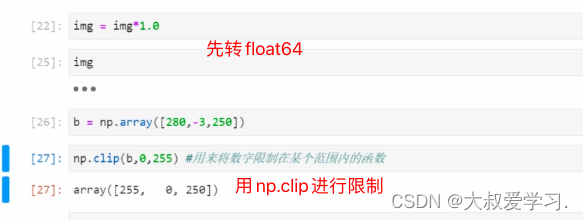
img = img/255
#所有像素值都在0-255范围内,通过除以255,我们将图像归一化,并让像素的范围被压缩到[0,1]之间
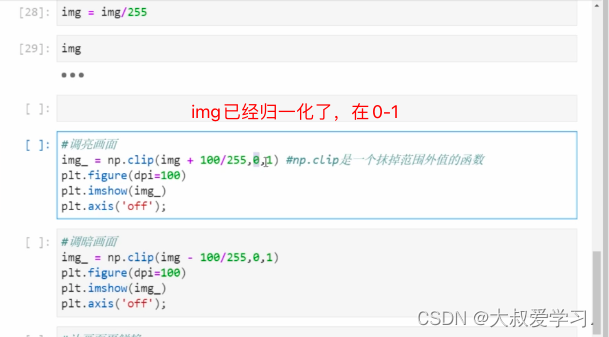




乘法和加法对于图像来说,是不太一样的。乘法是控制对比度,加法控制敏感程度。

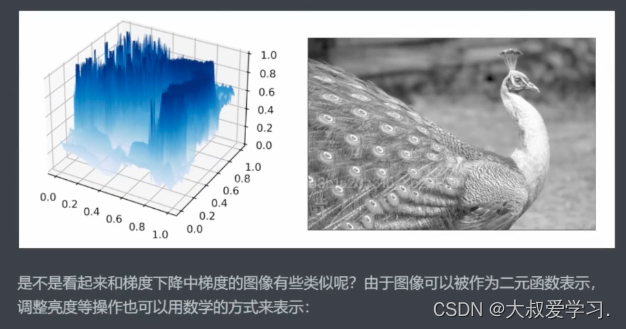


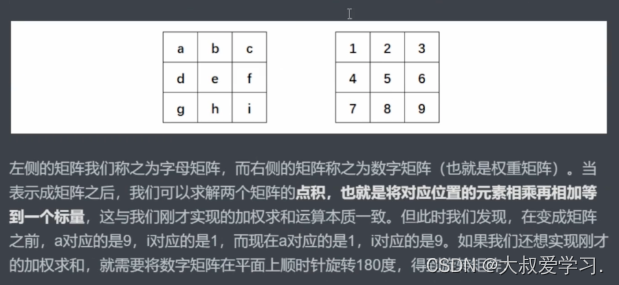

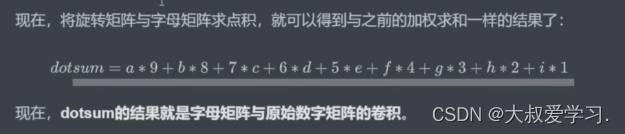
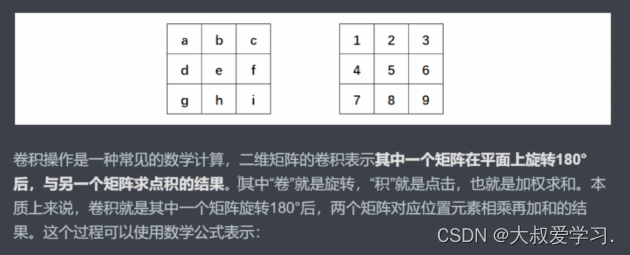
这和我一开始学的不一样。才知道为什么叫卷积。


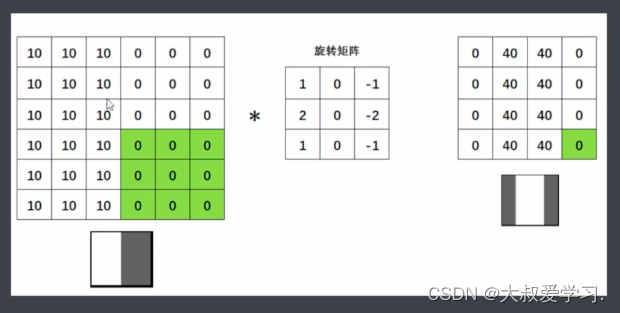
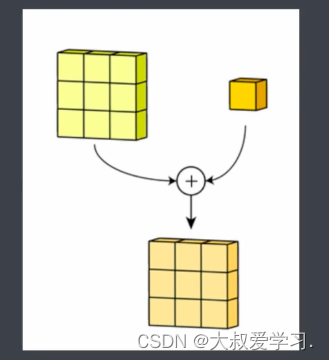
这里特别关键,我们之前说过,对图像像素进行数学运算,并且不超出图像的像素范围,就可以生成新的图像。而卷积就是一种从2个矩阵中得出新数值的方式。这个操作正好就是图像变换。
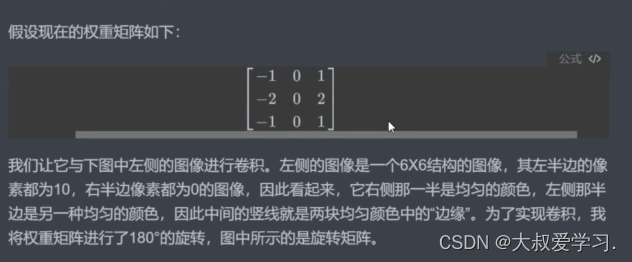
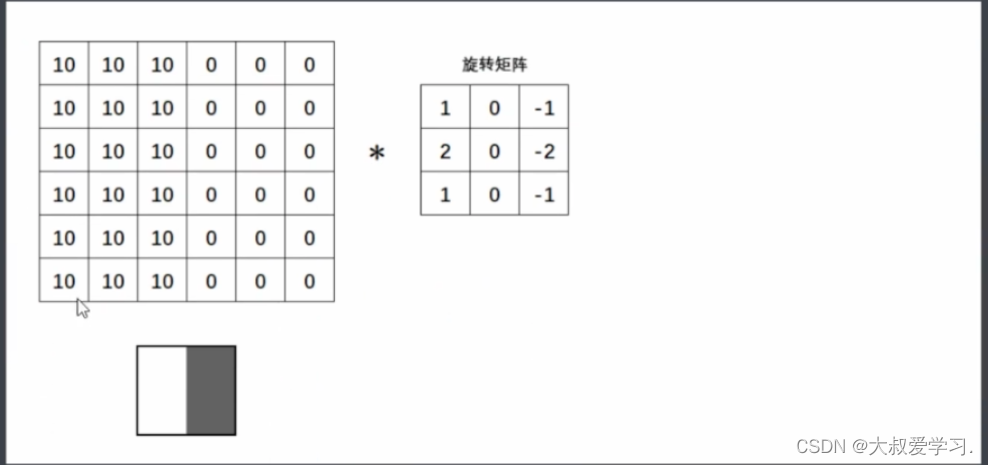
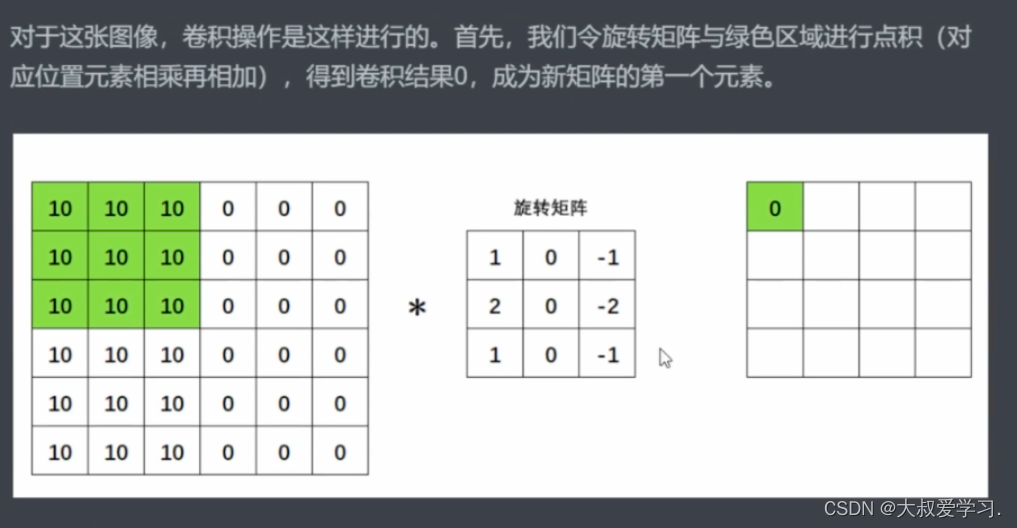
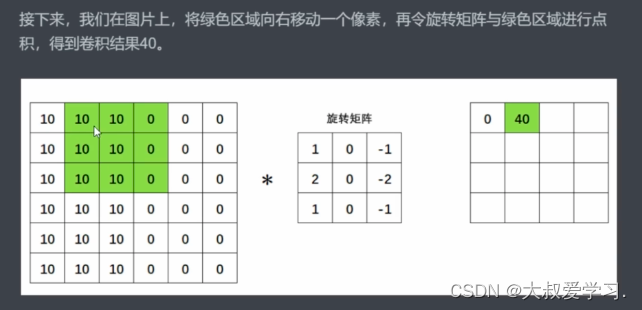



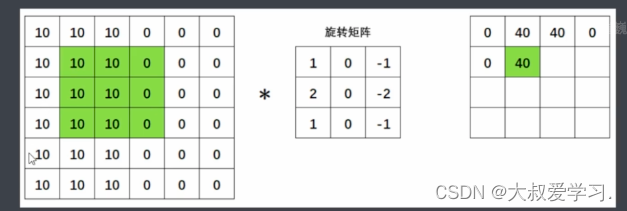
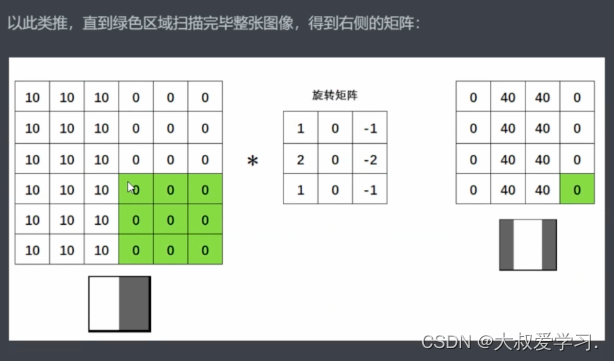





为什么要找个矩阵才旋转呢,为什么不直接找一个矩阵呢。所以从今天的眼光来说,旋转对于卷积已经是不太有意义的操作了。但是从卷积的发源来看,是有一个180度旋转的(数学线性加权)。在今天的深度学习当中,我们都不需要旋转了。很多人不知道卷积的卷怎么来的,卷就是旋转,但是目前不用旋转了。直接去求扫描区域和卷积核来进行点积。

感受野就是卷积核能够看到的区域。卷积核和感受野轮流得到的新的矩阵,叫特征图feature map。



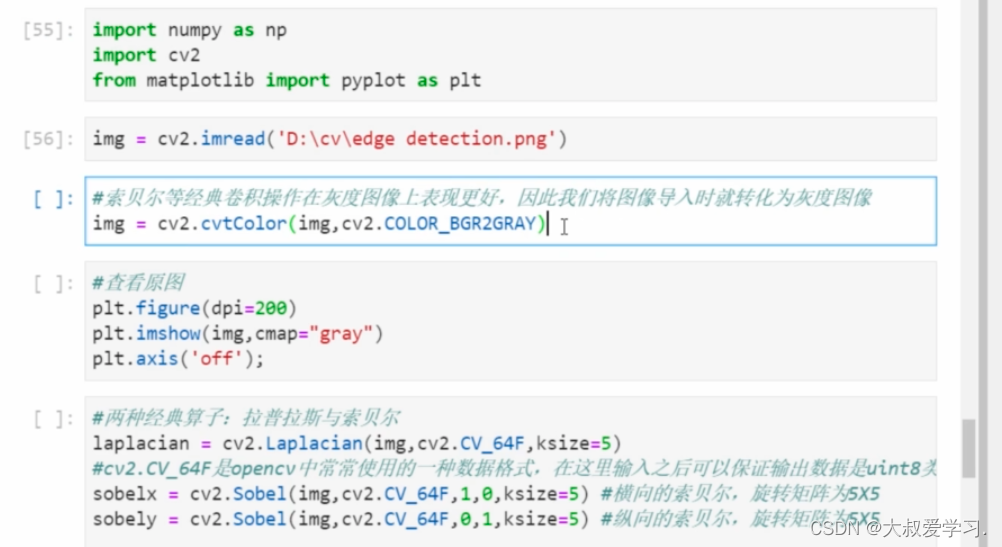
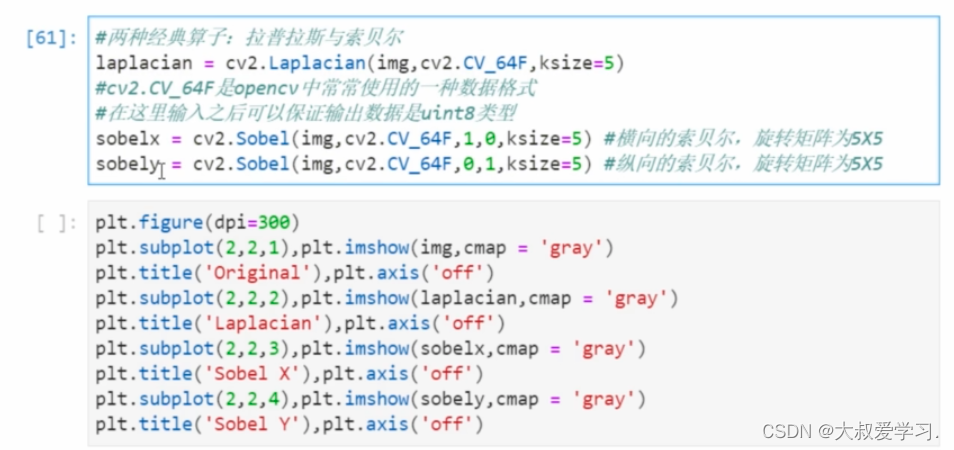
sobel和laplace已经不能很好的凸显原始图像了。我们需要用不同的卷积核,去提取图像的特征。假设计算机可以自己判断图像需要什么样的卷积核算子,知道自己需要把特征提取道什么程度就ok,我们希望让计算机自己做。这就是深度学习,神经网络自己学习kernal的weight。







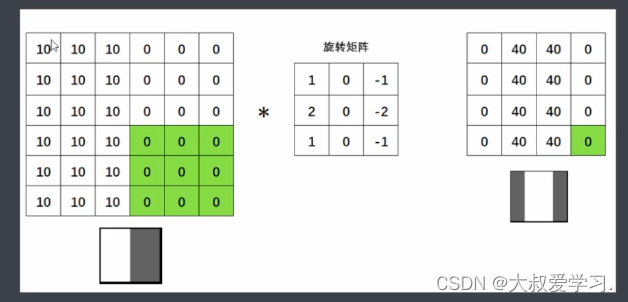



真实情况,反而是越浅的图片,越容易理解。但是对于人类看到的,浅层的,更容易理解。
Pytorch复现LeNet5与AlexNet




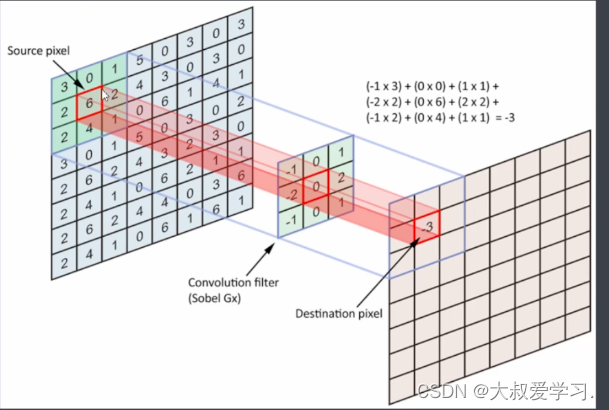
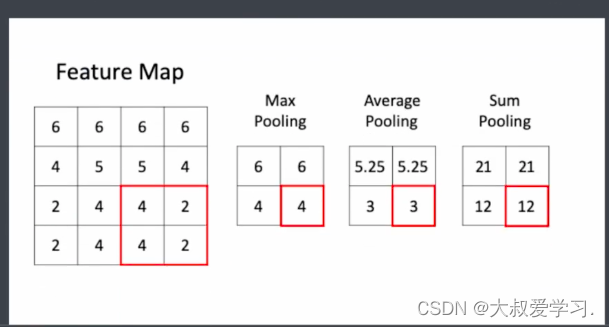
聚合了9个像素到中间那个点,保证图像的信息不断向中心进行压缩的。

2*2,没法向中心点压缩,而是往一个角进行压缩,可能造成图像的扭曲失真。有些像素往右边聚合,有的往左边聚合。那么多来几轮卷积操作,图像就失真了。

没有失真的feature map,对于原图来说只是缩放了比例。这对于anchor机制的目标检测很关键。


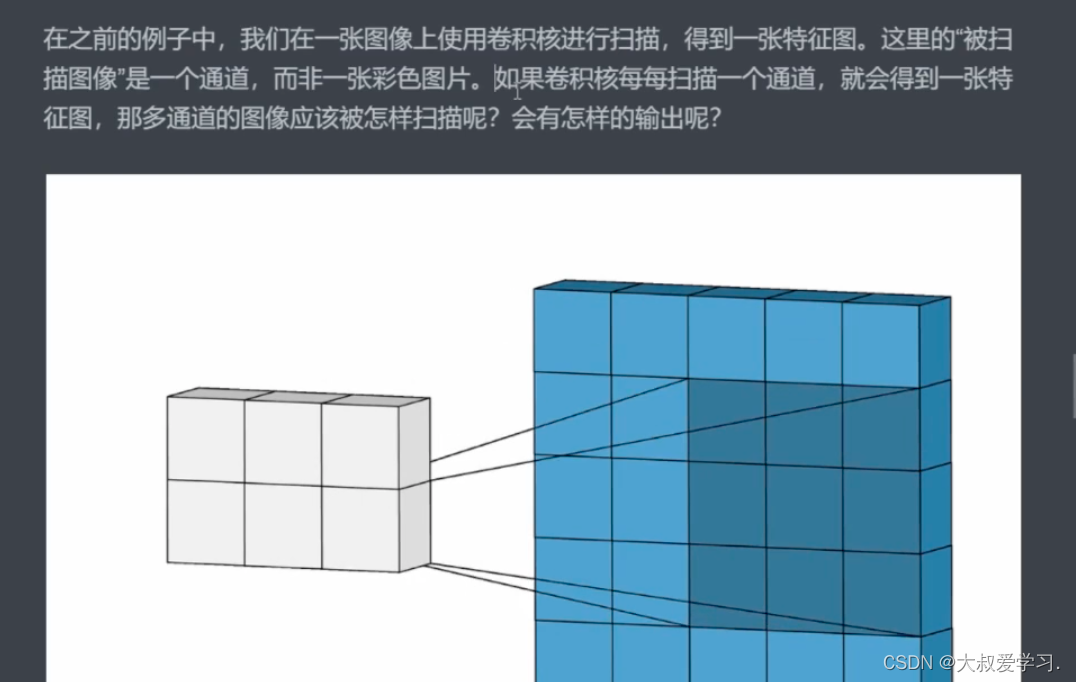
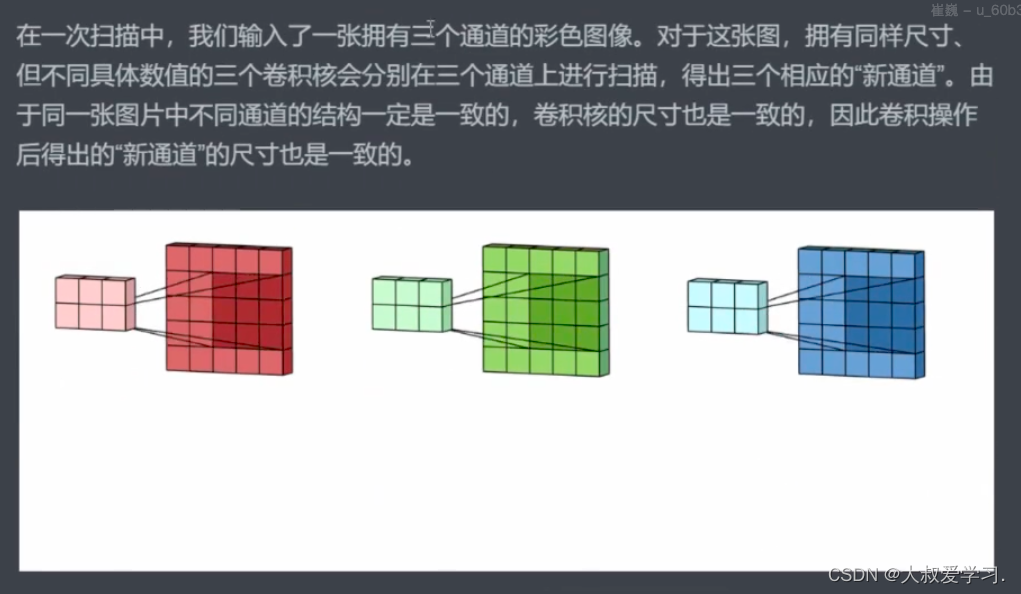
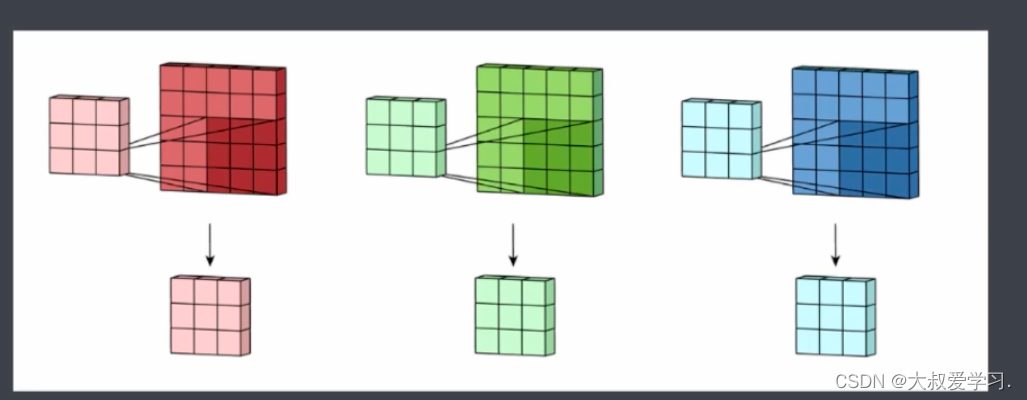
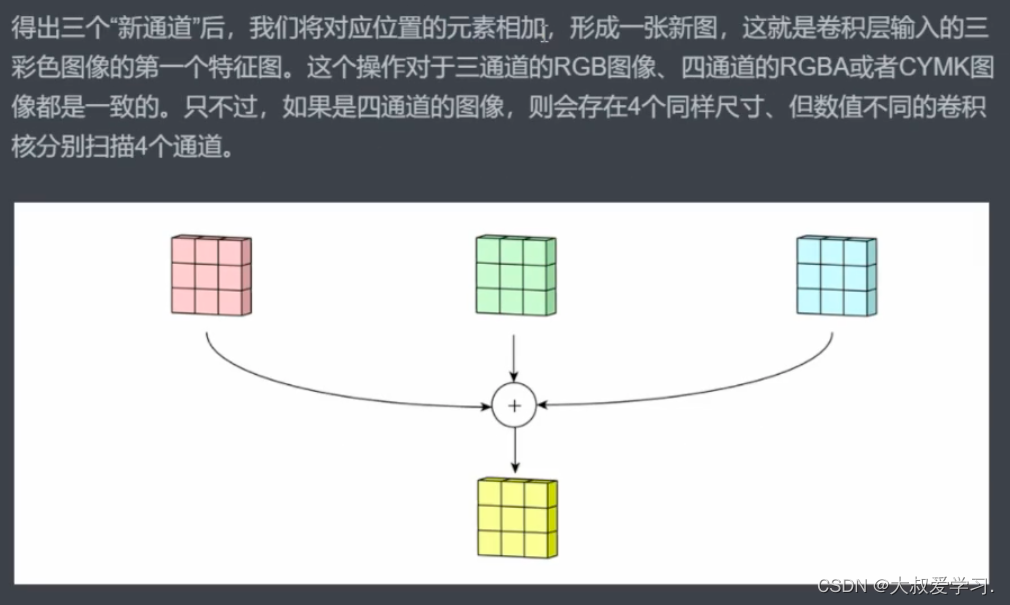

为什么需要扫描多次,因为图像有很多特征,一次扫描不能扫出全部特征。

比如说孔雀脖子,一个卷积核可能就可以扫出来了,但是尾巴那里,这个卷积就无法扫出来,需要别的卷积参数来提取特征。









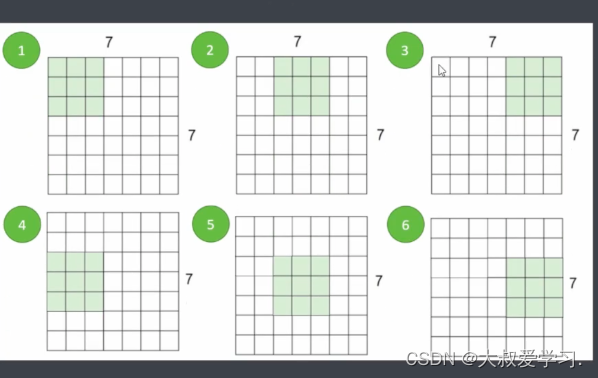





当像素不足够的时候,卷积核是不会扫描出去的。它会舍弃右边最后一列。
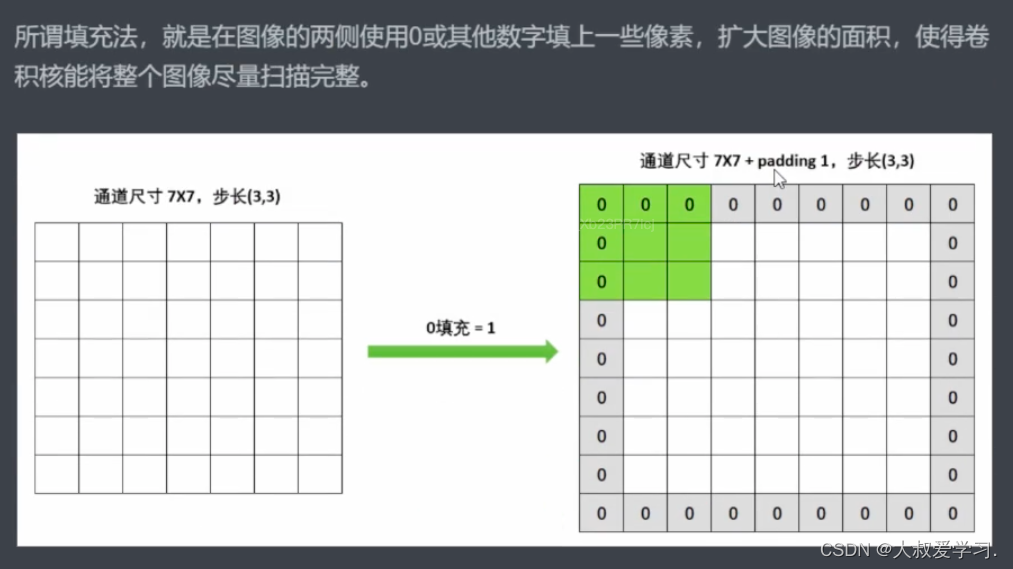

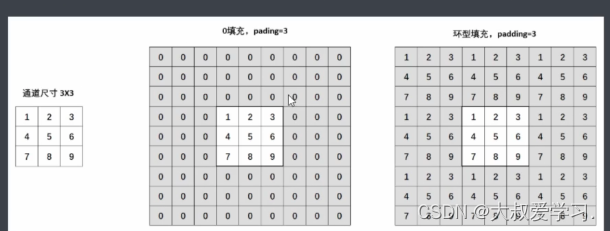
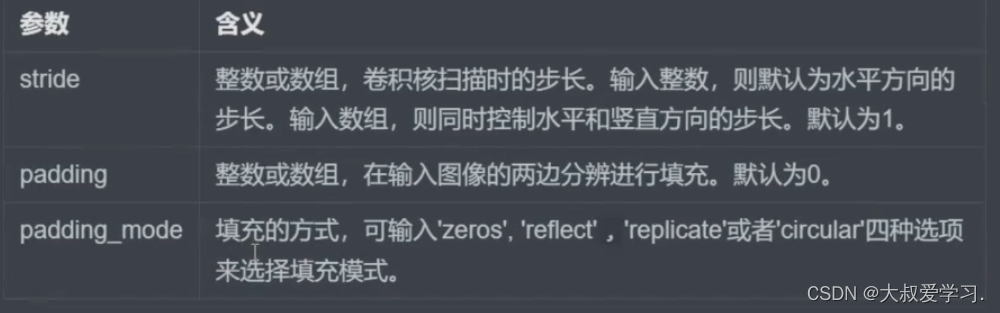
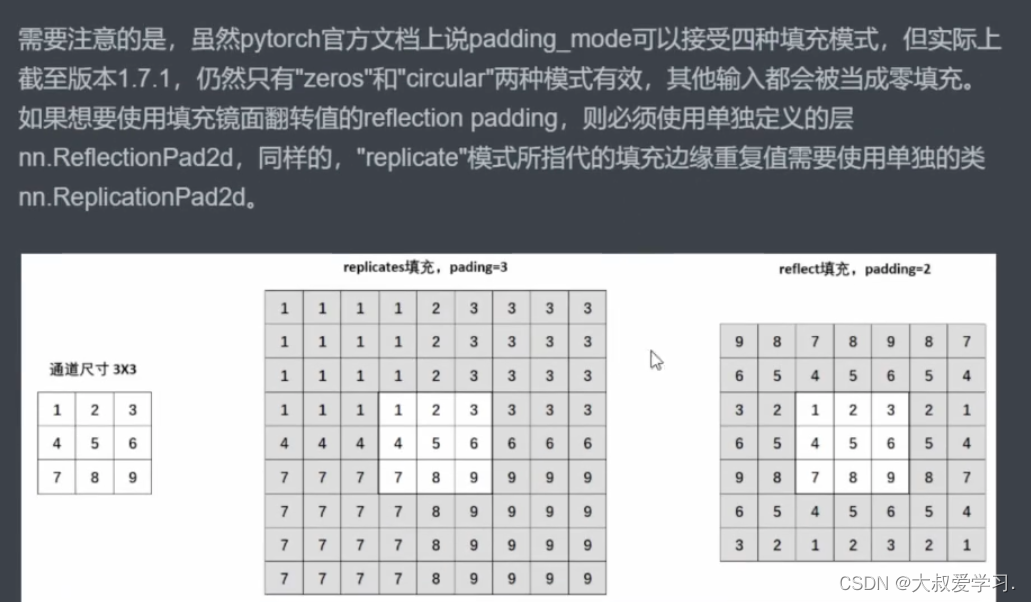

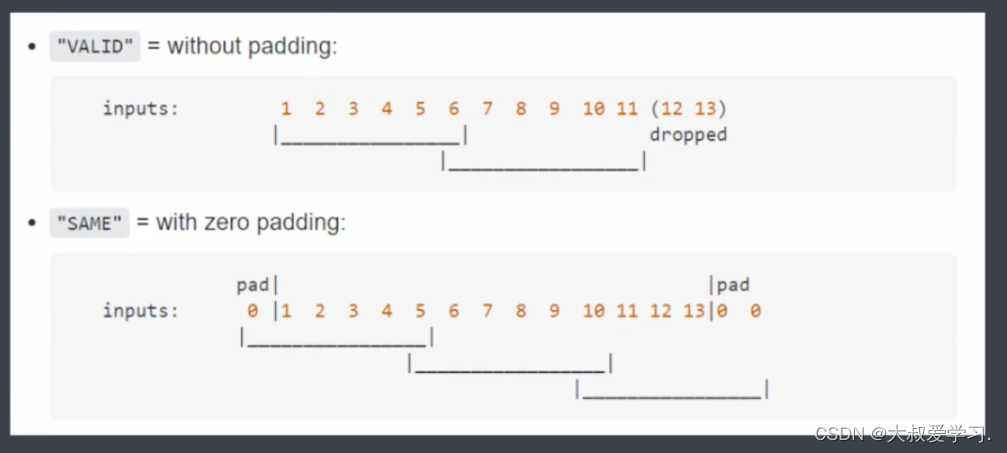

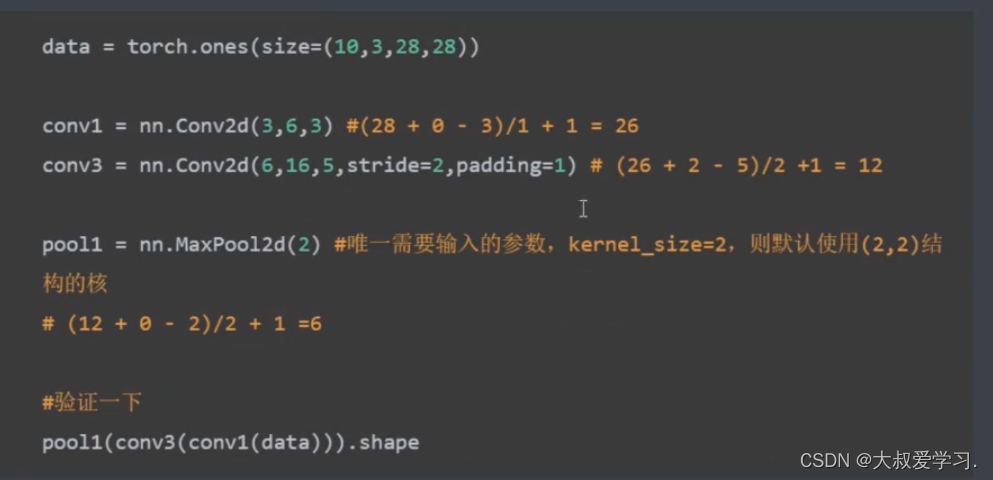
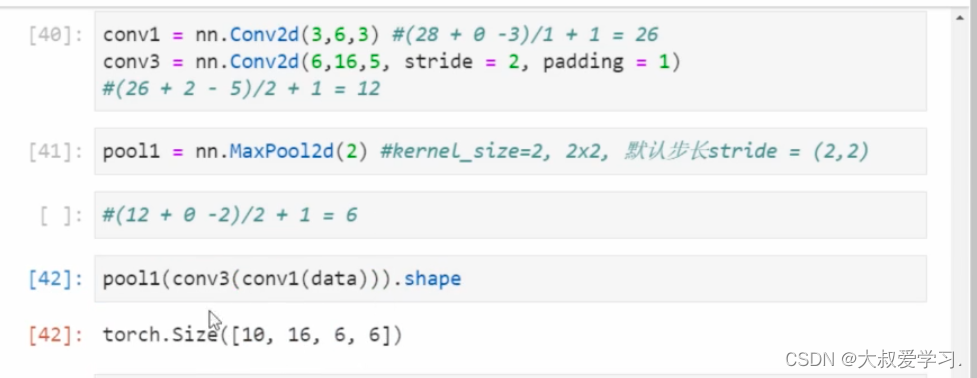
上面功能是tensorflow的。pytorch没有这个功能。



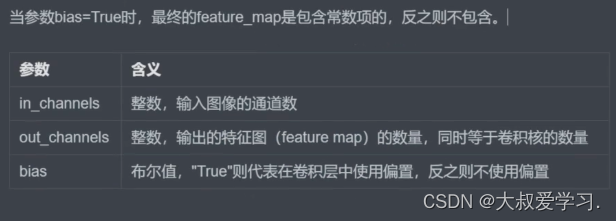
卷积kernel参数就是weight,需要loss反传学习。另外卷积是线性操作,一般都会后面跟激活函数,达到非线性变换目的。




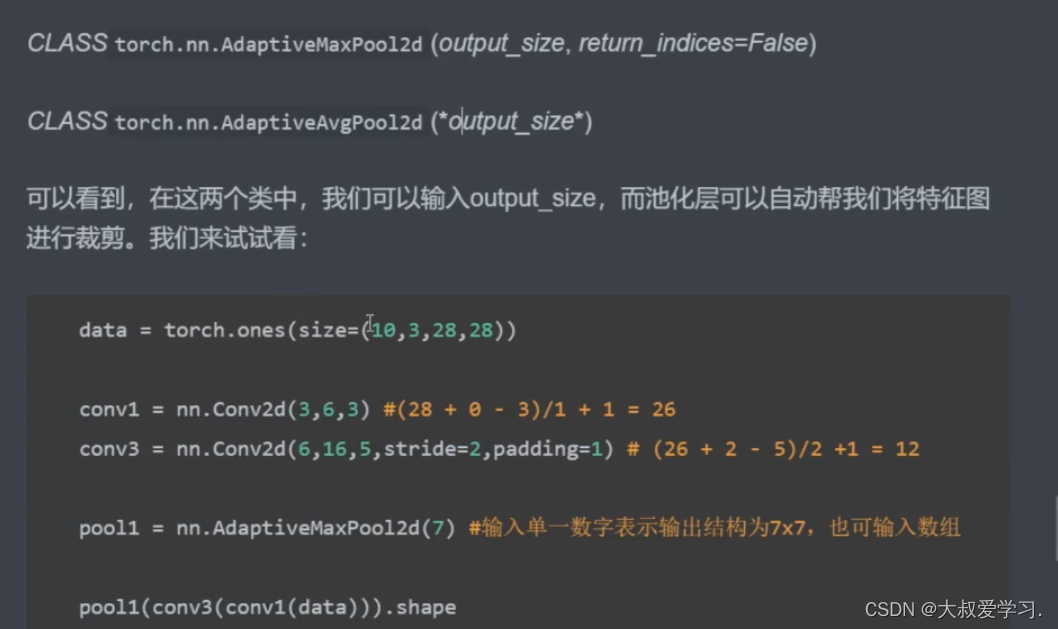



BN的输入也就是out_channels。
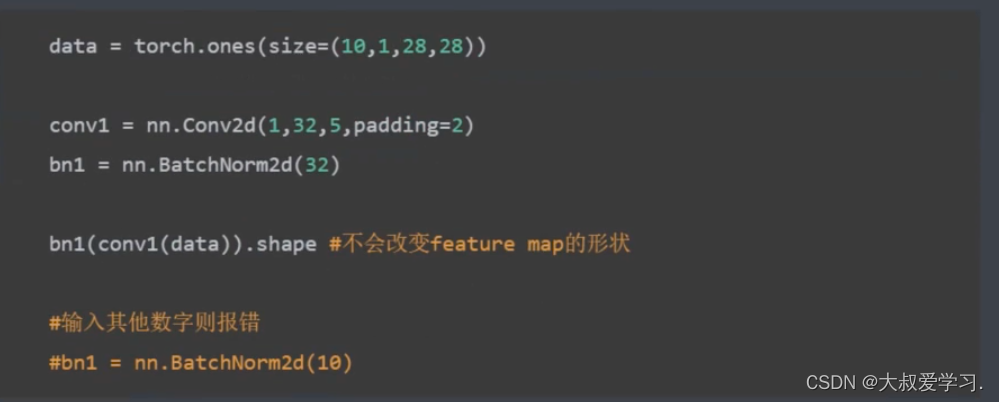

batchnorm2d是对每一张特征图进行归一化。总参数量=特征图的数量*2。2是gama和beta。