迷宫_Sarsa算法_边做边学深度强化学习:PyTorch程序设计实践(2)
迷宫_Sarsa算法_边做边学深度强化学习:PyTorch程序设计实践(2)
- 0、相关系列文章
- 1、导入所使用的包
- 2、 定义迷宫
- 3、定义迷宫动作
- 4、策略参数θ转换为行动策略π
- 5、定义动作和状态获取函数
- 6、定义Sarsa算法
- 7、定义使智能体移动到目标的函数
- 8、初始化
- 9、智能体移动到目标
- 10、运行路径可视化
- 11、最终结果
- 12、代码下载
- 13、参考资料
0、相关系列文章
迷宫_随机实验_边做边学深度强化学习:PyTorch程序设计实践(1)
1、导入所使用的包
# 导入所使用的包
import numpy as np
import matplotlib.pyplot as plt
2、 定义迷宫
fig = plt.figure(figsize=(5, 5))
ax = plt.gca()
# 画出红色的墙壁
plt.plot([1, 1], [0, 1], color='red', linewidth=2)
plt.plot([1, 2], [2, 2], color='red', linewidth=2)
plt.plot([2, 2], [2, 1], color='red', linewidth=2)
plt.plot([2, 3], [1, 1], color='red', linewidth=2)
# 画出表示状态的文字S0-S8
plt.text(0.5, 2.5, 'S0', size=14, ha='center')
plt.text(1.5, 2.5, 'S1', size=14, ha='center')
plt.text(2.5, 2.5, 'S2', size=14, ha='center')
plt.text(0.5, 1.5, 'S3', size=14, ha='center')
plt.text(1.5, 1.5, 'S4', size=14, ha='center')
plt.text(2.5, 1.5, 'S5', size=14, ha='center')
plt.text(0.5, 0.5, 'S6', size=14, ha='center')
plt.text(1.5, 0.5, 'S7', size=14, ha='center')
plt.text(2.5, 0.5, 'S8', size=14, ha='center')
plt.text(0.5, 2.3, 'START', ha='center')
plt.text(2.5, 0.3, 'GOAL', ha='center')
# 设定画图的范围
ax.set_xlim(0, 3)
ax.set_ylim(0, 3)
ax.set_title("Random")
plt.tick_params(axis='both', which='both', bottom='off', top='off',
labelbottom='off', right='off', left='off', labelleft='off')
# 当前位置S0用绿色圆圈画出
line, = ax.plot([0.5], [2.5], marker="o", color='g', markersize=60)
3、定义迷宫动作
# 设定参数θ的初始值theta_0,用于确定初始方案
# 行为状态0~7,列为用↑、→、↓、←表示的移动方向
theta_0 = np.array([[np.nan, 1, 1, np.nan], # s0
[np.nan, 1, np.nan, 1], # s1
[np.nan, np.nan, 1, 1], # s2
[1, 1, 1, np.nan], # s3
[np.nan, np.nan, 1, 1], # s4
[1, np.nan, np.nan, np.nan], # s5
[1, np.nan, np.nan, np.nan], # s6
[1, 1, np.nan, np.nan], # s7,s8是目标,无策略
])
效果:

4、策略参数θ转换为行动策略π
# 策略参数θ转换为行动策略π
def simple_convert_into_pi_from_theta(theta):
[m,n] = theta.shape
pi = np.zeros((m,n))
for i in range(0,m):
pi[i,:] = theta[i,:] / np.nansum(theta[i,:])
pi = np.nan_to_num(pi)
return pi
5、定义动作和状态获取函数
# 获得动作
def get_action(s, Q, epsilon, pi_0):
direction = ["up", "right", "down", "left"]
# 确定行动
if np.random.rand() < epsilon:
# 以ε概率随机行动
next_direction = np.random.choice(direction, p=pi_0[s, :])
else:
# 采用Q的最大值对应的动作
next_direction = direction[np.nanargmax(Q[s,:])]
# 为动作加上索引
if next_direction == "up":
action = 0
elif next_direction == "right":
action = 1
elif next_direction == "down":
action = 2
elif next_direction == "left":
action = 3
return action
def get_s_next(s, a, Q, epsilon, pi_0):
direction = ["up", "right", "down", "left"]
next_direction = direction[a]
# 由动作确定下一个状态
if next_direction == "up":
s_next = s - 3 # 向上移动时状态的数字减少3
elif next_direction == "right":
s_next = s + 1 # 向右移动时状态的数字增加1
elif next_direction == "down":
s_next = s + 3 # 向下移动时状态的数字增加3
elif next_direction == "left":
s_next = s - 1 # 想做移动时状态的数字减少1
return s_next
6、定义Sarsa算法
1、(策略梯度法)对策略进行更新,选择能够更快到达目标的策略下所执行的动作,即借鉴成功案例
2、(价值迭代法)从目标反向计算在目标的前一步、前两步的位置(状态)等,一步步引导智能体的行为,即给目标以外的位置也附加价值
# 基于Sarsa更新动作价值函数
def Sarsa(s, a, r, s_next, a_next,Q, eta, gamma):
if s_next == 8: # 已到达目标
Q[s,a] = Q[s,a] + eta * (r - Q[s, a])
else:
Q[s,a] = Q[s,a] + eta * (r + gamma * Q[s_next, a_next] - Q[s, a])
return Q
7、定义使智能体移动到目标的函数
# 迷宫内使智能体移动到目标,输出状态和动作序列
def goal_maze_ret_s_a_Q(Q, epsilon, eta, gamma, pi):
s = 0 # 开始地点
a = a_next = get_action(s, Q, epsilon, pi) # 初始动作
s_a_history = [[0,np.nan]] # 记录智能体移动轨迹的列表
while (1): # 循环,直至到达目标
a = a_next # 更新动作
s_a_history[-1][1] = a # 将动作放在现在的状态下
s_next = get_s_next(s, a, Q, epsilon, pi) # 有效的下一个状态
s_a_history.append([s_next, np.nan])
if s_next == 8: # 到达目标地点则终止
r = 1 # 到达目标,给予奖励
a_next = np.nan
break
else:
r = 0
a_next = get_action(s_next, Q, epsilon, pi)
# 更新价值函数
Q = Sarsa(s, a, r, s_next, a_next, Q, eta, gamma)
if s_next == 8:
break
else:
s = s_next
return [s_a_history,Q]
8、初始化
# 设置初始的动作价值函数
[a,b] = theta_0.shape # 将行列数放入a、b
Q = np.random.rand(a,b) * theta_0 # 将theta_0乘到各元素上,使得Q的墙壁方向的值为nan
# 求初始策略π
pi_0 = simple_convert_into_pi_from_theta(theta_0)
pi_0
9、智能体移动到目标
eta = 0.1
gamma = 0.9
epsilon = 0.5
v = np.nanmax(Q, axis=1)
is_continue = True
episode = 1
ypoints = []
while is_continue:
print("当前回合:"+ str(episode))
epsilon = epsilon / 2
[s_a_history,Q] = goal_maze_ret_s_a_Q(Q, epsilon, eta, gamma, pi_0)
new_v = np.nanmax(Q, axis=1)
print(np.sum(np.abs(new_v - v)))
# 可视化
ypoints.append(np.sum(np.abs(new_v - v)))
v = new_v
print("求解迷宫问题所需要的步数是:" + str(len(s_a_history) - 1))
print(np.sum(np.abs(new_v - v))) # 输出策略的变化的绝对值
episode = episode + 1
if episode > 100:
break
# 可视化策略变化的绝对值
#plt.figure(figsize = (20,10))
#plt.plot(ypoints[1:])
# plt.show()
# 可视化状态价值函数Q
print(Q)
10、运行路径可视化
# 参考URL http://louistiao.me/posts/notebooks/embedding-matplotlib-animations-in-jupyter-notebooks/
from matplotlib import animation
from IPython.display import HTML
def init():
'''初始化背景图像'''
line.set_data([], [])
return (line,)
def animate(i):
'''每一帧的画面内容'''
state = state_history[i] # 画出当前的位置
x = (state % 3) + 0.5 # 状态的x坐标为状态数除以3的余数加0.5
y = 2.5 - int(state / 3) # 状态y坐标为2.5减去状态数除以3的商
line.set_data(x, y)
return (line,)
# 用初始化函数和绘图函数来生成动画
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(
state_history), interval=200, repeat=False)
anim.save('result/maze_Random.gif',writer='pillow')
HTML(anim.to_jshtml())
11、最终结果
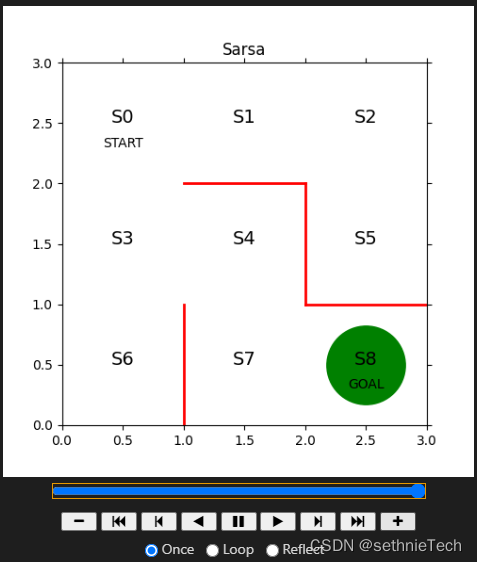
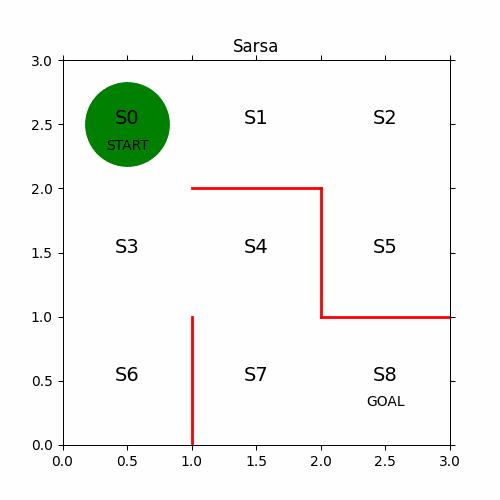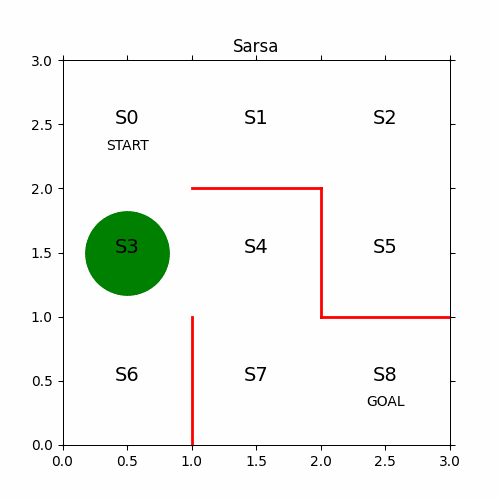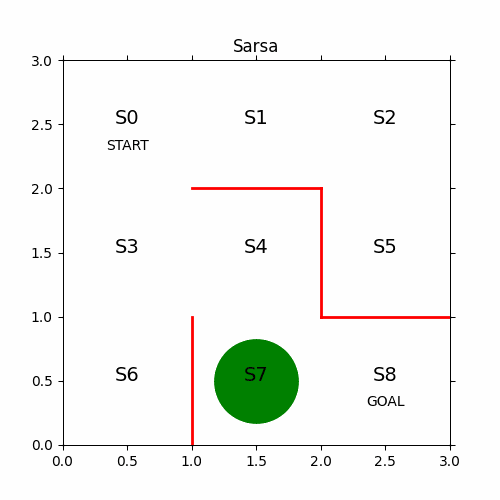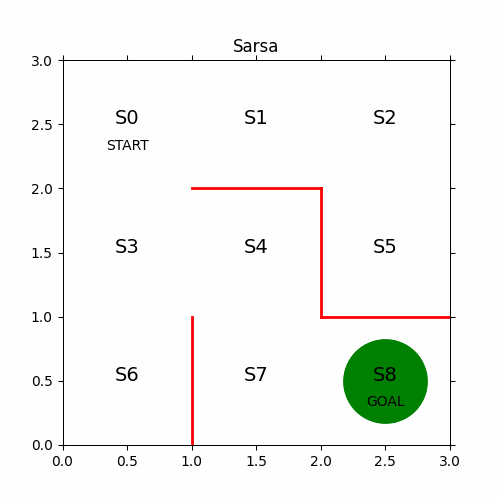
12、代码下载
跳转到下载地址
13、参考资料
[1]边做边学深度强化学习:PyTorch程序设计实践