2D Transpose算子GPU实现和优化
2D Transpose
一种较好的做法是基于shared mem,合并内存访问读取到shared mem,读取整个warpSize x warpSize大小的矩阵块。然后基于shared mem索引变换读取实现转置效果,最后写回同样可以合并内存访问。可以考虑使用一个warp或者一个thread block读取warpSize x warpSize大小的矩阵,基于shared mem转置后写回。中小尺寸采用后者,也就是一个thread block转置一个warpSize x warpSize大小的矩阵,可以创建更多的线程提高硬件利用率,性能更优。
参考CUDA实现代码
#include <stdio.h>
#include <iostream>
using namespace std;
#include <cuda_runtime.h>
#include "utils/cuda_mem_helper.h"
#include "utils/cuda_stream_helper.h"
#define THREAD_PER_WARP 32
#define WARP_PER_BLOCK 8
#define BLOCK_RD_NUM (THREAD_PER_WARP / WARP_PER_BLOCK)
/*
using a warp to transpose warpSize*warpSize block
*/
template <typename T>
__global__ void transpose_2d_warp(const T* __restrict__ in, T* __restrict__ out,
const int row, const int col,
int warp_row, int warp_col, int total_warp) {
const int tid = blockDim.x * blockIdx.x + threadIdx.x; // global thread id
const int warp_bid = threadIdx.x / THREAD_PER_WARP; // warp id in thread block
const int warp_gid = tid / THREAD_PER_WARP; // warp id in grid
const int lane = threadIdx.x % THREAD_PER_WARP; // thread id in warp
const int warp_id_c = warp_gid % warp_col;
const int warp_id_r = warp_gid / warp_col;
// add array padding to handle bank-conflict
__shared__ T block_data[WARP_PER_BLOCK][THREAD_PER_WARP][THREAD_PER_WARP + 1];
const int row_bias = warp_id_r * THREAD_PER_WARP;
const int col_bias = warp_id_c * THREAD_PER_WARP;
// read block from input
for (int i = 0; i < THREAD_PER_WARP; i++) {
int addr = (row_bias + i) * col + col_bias + lane;
block_data[warp_bid][i][lane] = in[addr];
}
__syncthreads();
// write block to output
for (int i = 0; i < THREAD_PER_WARP; i++) {
int tgt_c = col_bias + i;
int tgt_r = row_bias + lane;
if ((tgt_r < row) && (tgt_c < col)) {
int addr = tgt_c * row + tgt_r;
out[addr] = block_data[warp_bid][lane][i];
}
}
}
/*
using a thread block to transpose warpSize*warpSize block
*/
template <typename T>
__global__ void transpose_2d_block(const T* __restrict__ in, T* __restrict__ out,
const int row, const int col) {
int block_id = blockIdx.x;
int block_num_col = col / warpSize;
int block_id_row = block_id / block_num_col;
int block_id_col = block_id % block_num_col;
int row_offset = block_id_row * warpSize;
int col_offset = block_id_col * warpSize;
int row_id = threadIdx.x / warpSize;
int col_id = threadIdx.x % warpSize;
// add array padding to handle bank-conflict
__shared__ T block_data[THREAD_PER_WARP][THREAD_PER_WARP + 1];
#pragma unroll
for (int i = 0; i < BLOCK_RD_NUM; i++) {
int row_pos = i * WARP_PER_BLOCK + row_id;
int in_addr = (row_offset + row_pos) * col + col_offset + col_id;
block_data[row_pos][col_id] = in[in_addr];
}
__syncthreads();
#pragma unroll
for (int i = 0; i < BLOCK_RD_NUM; i++) {
int row_pos = i * WARP_PER_BLOCK + row_id;
int out_addr = (col_offset + row_pos) * row + row_offset + col_id;
out[out_addr] = block_data[col_id][row_pos];
}
}
template <typename T>
void Transpose2DWarp(const T* in, T* out, const int row, const int col, cudaStream_t & stream) {
const int warp_row = (row + THREAD_PER_WARP - 1) / THREAD_PER_WARP;
const int warp_col = (col + THREAD_PER_WARP - 1) / THREAD_PER_WARP;
const int total_warp = warp_row * warp_col;
const int block_size = THREAD_PER_WARP * WARP_PER_BLOCK;
const int grid_size = (total_warp + WARP_PER_BLOCK - 1) / WARP_PER_BLOCK;
transpose_2d_warp <<< grid_size, block_size, 0, stream>>>(in, out, row, col, warp_row, warp_col, total_warp);
}
template <typename T>
void Transpose2DBlock(const T* in, T* out, const int row, const int col, cudaStream_t & stream) {
const int block_row = (row + THREAD_PER_WARP - 1) / THREAD_PER_WARP;
const int block_col = (col + THREAD_PER_WARP - 1) / THREAD_PER_WARP;
const int total_block = block_row * block_col;
const int block_size = THREAD_PER_WARP * WARP_PER_BLOCK;
const int grid_size = total_block;
transpose_2d_block <<< grid_size, block_size, 0, stream>>>(in, out, row, col);
}
int main(void) {
cudaError_t err = cudaSuccess;
int row = 256;
int col = 256;
CudaMemoryHelper<float> data_in({row, col});
CudaMemoryHelper<float> data_out({row, col});
data_in.StepInitHostMem(1.0f);
data_in.CopyMemH2D();
data_in.PrintElems(4, 512, col);
CudaStreamHelper stream_helper;
auto & stream = stream_helper.stream;
int eval_num = 20;
int thread_num = row * col;
int threadsPerBlock = std::min(128, col);
int blocksPerGrid = (thread_num + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
for (int i = 0; i < eval_num; i++) {
Transpose2DWarp(data_in.d_mem, data_out.d_mem, row, col, stream);
}
stream_helper.Sync();
for (int i = 0; i < eval_num; i++) {
Transpose2DBlock(data_in.d_mem, data_out.d_mem, row, col, stream);
}
stream_helper.Sync();
data_out.CopyMemD2H();
printf("results0:\n");
// verify results
data_out.PrintElems(1, 1024, row);
return 0;
}
可以参考
CUDA学习(二)矩阵转置及优化(合并访问、共享内存、bank conflict) - 知乎
存在两个问题
端侧GPU没有shared mem怎么处理?
矩阵比较小的时候,一个warp 16/32个线程(端侧GPU可能是warp size=16),这个方法需要读取16x16 / 32x32矩阵块,导致创建的线程太少,性能比较差。
解决方案
主要针对小shape矩阵转置和没有/不使用shared mem场景。
针对warp=16的情况考虑整个warp读取4x4矩阵快,相比16x16矩阵块,创建线程数x16倍。同样,warp=32考虑读取4x8,或者8x4,或者2个4x4,或者读两次得到8x8矩阵块。
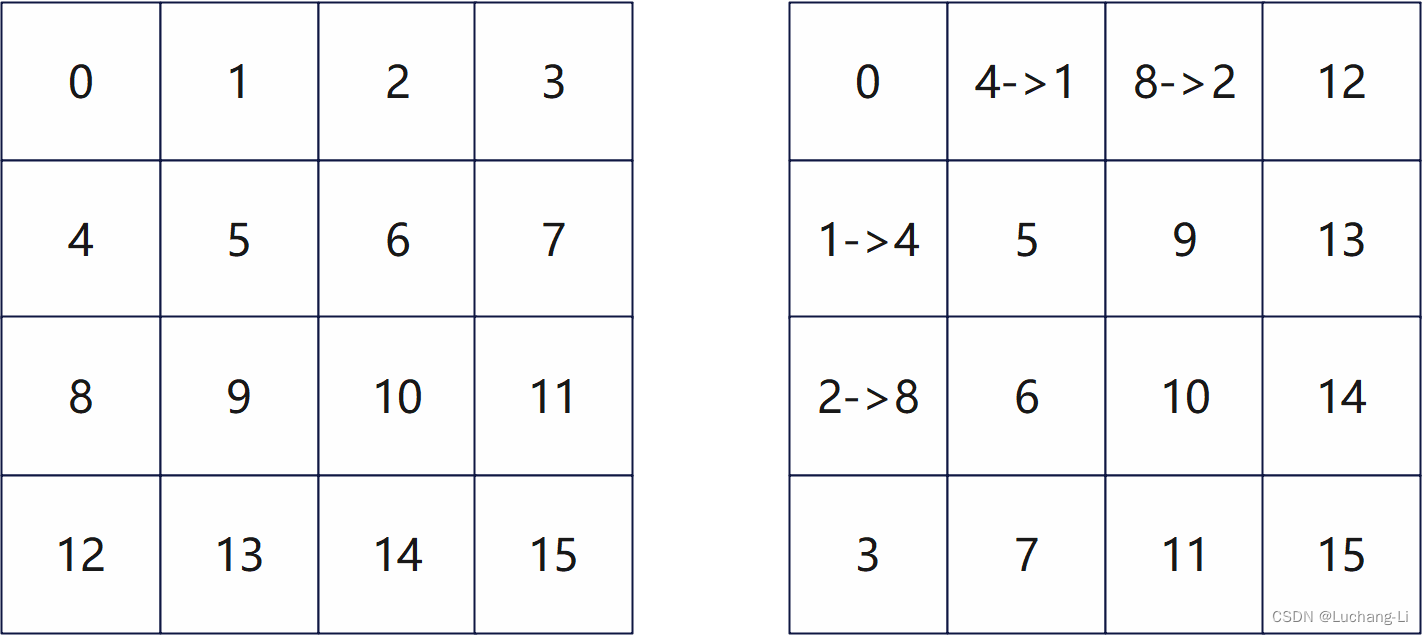
这样每个线程读写1个值,同时,每4个相邻线程读写相邻的4个元素。
第二个图的箭头表示线程之间的数据交换,其他位置类似。其特点是两个线程之间数据相互交换。
这个可以通过warp shuffle完成,每个线程给出自己的值,然后再获取自己想要的线程的值。
针对warpSize=16, 4x4读取,当前线程id lane_dst获取目标线程线程id lane_src计算:
col = lane_dst % 4 // & 0x03
row = lane_dst / 4 // >> 2
lane_src = col * 4 + row针对warpSize=32, 4x8读取,转置后是8x4,上面更加一般化为:
col = lane_dst % COL_SIZE_NEW // COL_SIZE_NEW = 4
row = lane_dst / COL_SIZE_NEW
lane_src = col * COL_SIZE_OLD + row // COL_SIZE_OLD = 8CUDA参考实现代码
#include <stdio.h>
#include <iostream>
using namespace std;
#include <cuda_runtime.h>
#include "utils/cuda_mem_helper.h"
#include "utils/cuda_stream_helper.h"
#define WARP_SIZE 32
#define ROW_SIZE_OLD 4
#define COL_SIZE_OLD 8
#define ROW_SIZE_NEW 8
#define COL_SIZE_NEW 4
// use a warp to calculate
__global__ void transpose_warp1(const float* __restrict__ in, float* __restrict__ out, int row, int col) {
int gid = blockDim.x * blockIdx.x + threadIdx.x;
int warp_id = gid / 32;
int lane_id = threadIdx.x % 32;
int _row = lane_id / COL_SIZE_NEW;
int _col = lane_id % COL_SIZE_NEW; // COL_SIZE_NEW = 4
int lane_src = _col * COL_SIZE_OLD + _row; // COL_SIZE_OLD = 8
int warp_num_col = col / COL_SIZE_OLD;
int row_id = warp_id / warp_num_col;
int col_id = warp_id % warp_num_col;
// addr offset of the matrix block
int row_offset = row_id * ROW_SIZE_OLD;
int col_offset = col_id * COL_SIZE_OLD;
int row_th_old = lane_id / COL_SIZE_OLD;
int col_th_old = lane_id % COL_SIZE_OLD;
int row_th_new = lane_id / COL_SIZE_NEW;
int col_th_new = lane_id % COL_SIZE_NEW;
float data = in[(row_offset + row_th_old) * col + col_offset + col_th_old];
// warp shuffle
data = __shfl_sync(0xFFFFFFFF, data, lane_src);
int out_addr = (col_offset + row_th_new) * row + row_offset + col_th_new;
out[out_addr] = data;
}
int main(void) {
cudaError_t err = cudaSuccess;
int row = 256;
int col = 256;
CudaMemoryHelper<float> data_in({row, col});
CudaMemoryHelper<float> data_out({row, col});
data_in.StepInitHostMem(1.0f);
data_in.CopyMemH2D();
data_in.PrintElems(4, 512, col);
CudaStreamHelper stream_helper;
auto & stream = stream_helper.stream;
int eval_num = 20;
int thread_num = row * col;
int threadsPerBlock = std::min(128, col);
int blocksPerGrid = (thread_num + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
for (int i = 0; i < eval_num; i++) {
transpose_warp1 <<< blocksPerGrid, threadsPerBlock, 0, stream>>>(data_in.d_mem, data_out.d_mem, row, col);
}
stream_helper.Sync();
data_out.CopyMemD2H();
printf("results0:\n");
// verify results
data_out.PrintElems(4, 512, row);
return 0;
}
在上面三个方法以及tensorflow transpose算子对比中,
最后的方法在32x32, 64x64等小矩阵转置性能最优,128x128时略差于基于thread block转置warpSize*warpSize。在大于128x128时最后的方法性能比较差。基于thread block转置warpSize*warpSize最优。