面向跨模态匹配的噪声关联学习

©PaperWeekly 原创 · 作者 | 黄振宇
单位 | 四川大学博士生
研究方向 | 多模态学习

简介
跨模态匹配旨在建立两种不同模态之间的对应关系,是跨模态检索和视觉与语言理解等多种任务的基础。尽管近年来大量的跨模态匹配方法被提出并取得了显著进展,但几乎所有这些方法都隐含着一个假设:多模态训练数据是正确对齐或关联的。然而,在实践中满足这样的假设开销巨大,甚至不可能满足。
基于这一观察,我们在国际上率先揭示并研究了跨模态匹配中一个潜在的、具有挑战性的方向,即噪声关联学习,它可以被看作是噪声标签学习的一个新范式。与现有噪声标签不同的是,我们的噪声关联指的是不匹配的成对样本而非错误类别标注的单一数据。
针对上述问题,我们提出了一种新的学习方法,名为 “噪声关联矫正算法”(Noisy Correspondence Rectifier,NCR)。简单来说,NCR 根据神经网络的记忆效应将数据分为干净和噪声部分,然后通过一个自适应预测模型以 co-teaching 的方式纠正噪声关联。为验证我们方法的有效性,我们以图像-文本匹配为例进行了实验。在 Flickr30K、MS-COCO 和 Conceptual Captions 上进行的大量实验验证了我们方法的有效性。

方法
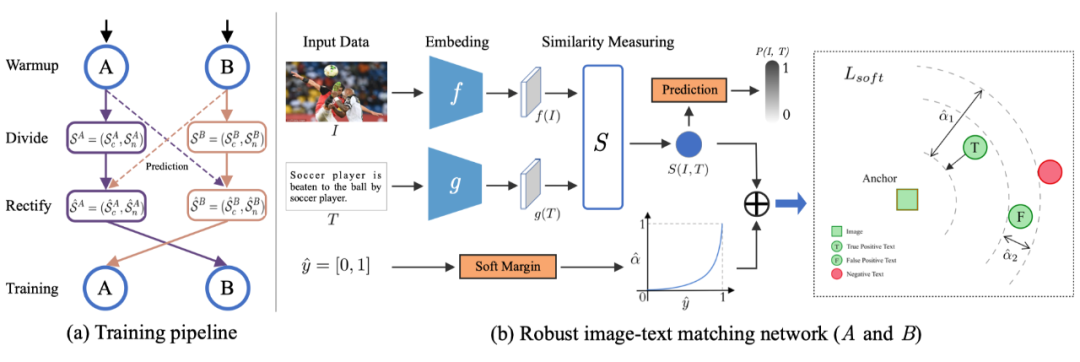
▲ 模型概览图
为解决跨模态匹配中的噪声关联问题,我们提出了一种新的方法,即噪声关联矫正算法(NCR)。我们的方法利用了 [2] 观察到的神经网络记忆效应(Memorization Effect),即神经网络首先倾向于在拟合噪声样本之前学习数据中简单的数据样本。在这一经验观察的启发下,NCR 构造一个 Co-divide 模块,其基于数据的损失差异将数据分为两个相对准确的数据分区,即“噪声”和“干净”子集。
具体的,我们首先计算每个样本的损失函数值:
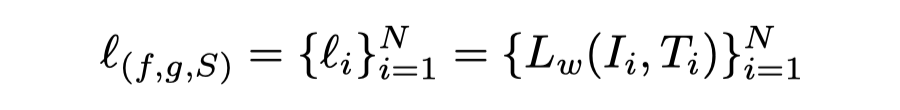
其中,Lw 定义如下:
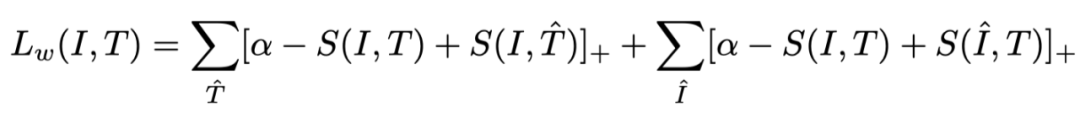
然后,我们通过使用一个二分量的高斯混合模型(GMM),对所有训练数据的样本损失函数值进行拟合。
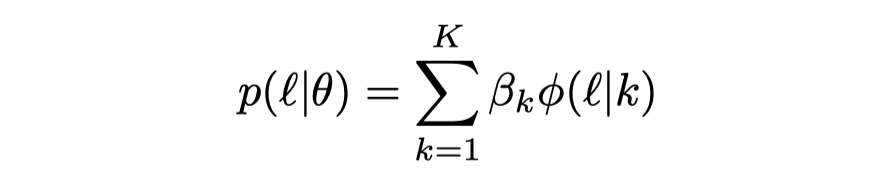
在这儿为了优化 GMM,我们采用了期望最大化算法(EM)。基于 DNN 的记忆效应,我们将均值较低(即损失较小)的成分作为干净数据集,另一个作为噪声数据集集,同时将其属于分量小的后验概率作为样本的干净置信度。
同时,为了避免单一神经网络导致的错误积累,我们采用共同训练的范式(co-teaching)。具体来说,我们单独训练两个网络 A 和 B,采用不同的初始化和批处理顺序。在每个迭代中,网络 A 或 B 将用 GMM 对其每个样本的损失分布进行建模,并将数据集分为干净和噪声的子集,然后用于训练另一个网络,即 co-divide。
之后,NCR 提出一个 co-rectify 模块,提出一个预测函数进行标签矫正,这样就可以分别从“噪声”和“干净”子集中识别出假阳性和真阳性。针对 co-divide 初略划分的数据集,我们首先进行标签矫正:

其中 P()是一个预测函数,具体形式为:

完成数据的标签修正后,我们就可以实现鲁棒的跨模态匹配。由于传统的匹配损失函数近接受二值化的标签,即非正即负的数据样本对,为了能充分利用我们上述模块修改后的软标签,我们提出了一种新的 Triplet 损失函数,通过将修改后的软标签自适应的转化为软间距(Soft Margin)来进行鲁棒的跨模态匹配,即:

其中软间隔由软标签自适应转化而来,即:
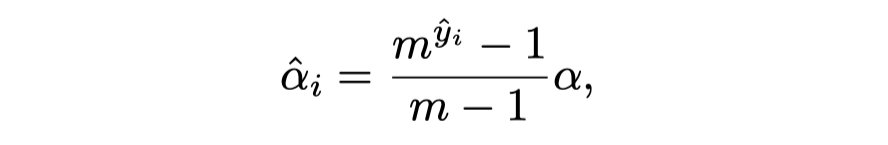

创新概要
一方面,论文在国际上率先揭示了匹配及关联学习中的一个新范式,即噪声关联学习。其可认为属于噪声标签学习,但具有显著不同。简要地,与传统的噪声标签不同,噪声关联指的是配对数据中的对齐错误,而不是类别注释的错误。
另一方面,为解决噪声关联问题,我们提出了一种新的噪声关联学习方法,即噪声关联矫正算法(NCR)。NCR 的一个主要创新点是,修改后的标签以一种巧妙的方式重新描述为 Triplet 损失的自适应间距(Margin),从而实现鲁棒的跨模式匹配。算法在三个具有挑战性的数据集上进行了大量实验,验证了我们的方法在合成噪音及真实噪声数据中的有效性。

实验结果
为了验证 NCR 的有效性,我们使用了三个基准数据集,包括 Flickr30K,MS-COCO 和 Conceptual Captions。其中,Conceptual Captions 使用的是来自开放场景的真实噪声关联,而 Flickr30K 和 MS-COCO 使用的是模拟的噪声关联。实验结果如下:
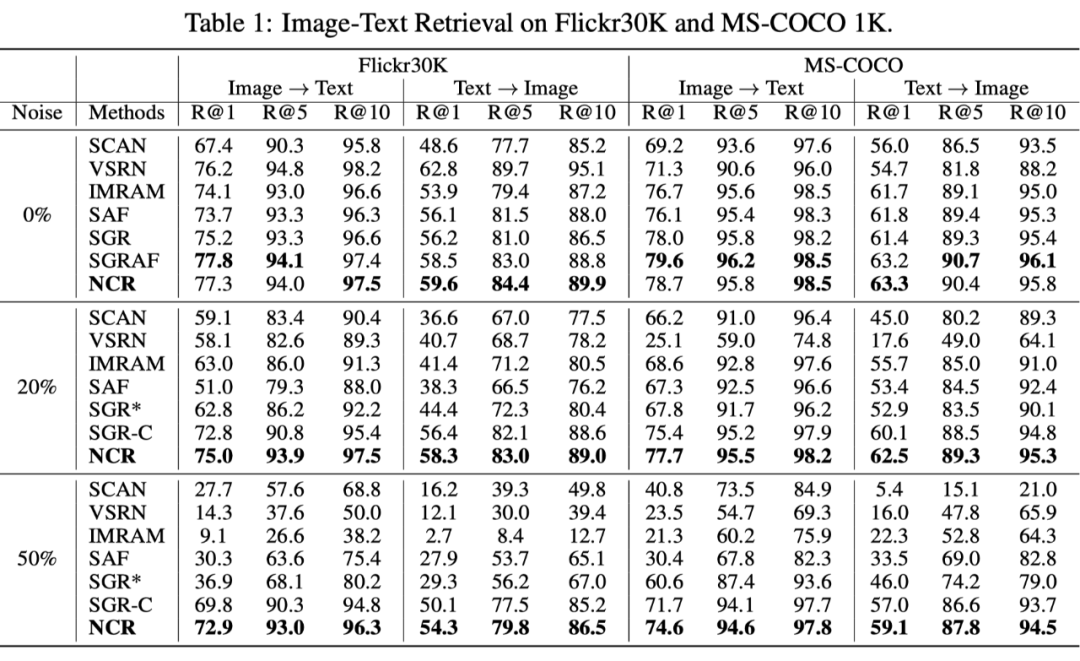
在 Flickr30K 和 MS-COCO 的实验结果:
在 CC 的子集 CC152K 上的实验结果:
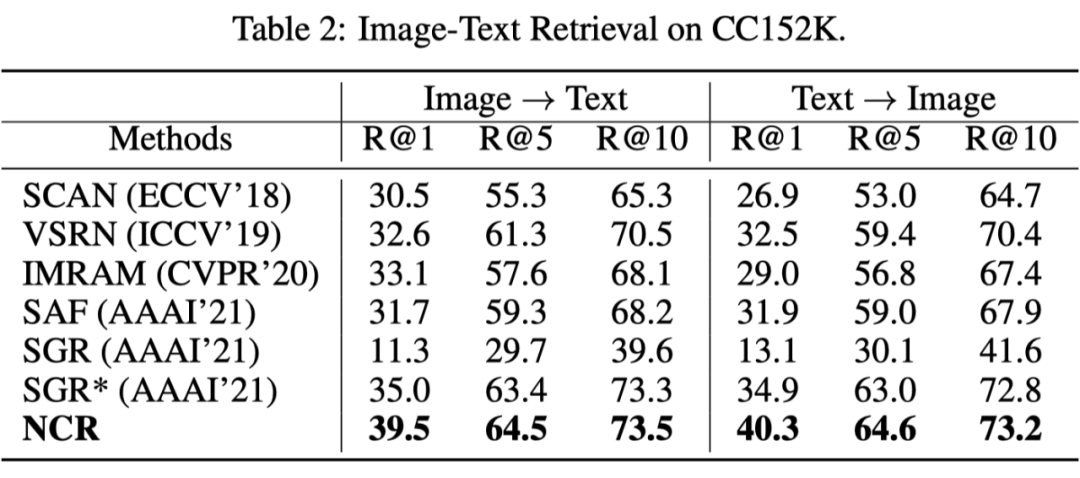
可以发现我们的方法 NCR 不管是在真实噪声还是模拟噪声,亦或低噪声(20%)还是高噪声(50%)中,都显著超过了基准方法,充分证明了算法的有效性。值得注意的是,即使我们的方法设计为解决噪声关联问题,在干净数据集上(Flickr30K 和 MS-COCO)NCR 仍然取的和当前最好基准线相当的结果,体现了其有效性。
同时,实验还展示了一些由NCR在Conceptual Captions数据集中检测到的噪声样本:

▲ Conceptual Captions数据中检测到的噪声样本示例图

总结
本文是四川大学彭玺教授研究组 CVPR 2021 [4] 的深入延续。[4] 通过探索了对比学习中的假阴性(False Negative)样本对问题,初步揭示了数据错配和错误关联现象,并构造了一个鲁棒的损失函数,赋予对比学习对假阴性样本的鲁棒性。而本文则以跨模态匹配任务为背景,基于对真实数据集(Conceptual Captions)的观察,揭示了假阳性(False Positive)的错误配对现象,其首次正式提出了噪声关联学习的概念和方向,并给出了解决方案。

参考文献
[1] Z. Huang, G. Niu, X. Liu, W. Ding, X. Xiao, H. Wu, X. Peng*, Learning with Noisy Correspondence for Cross-modal Matching, Neural Information Processing Systems (NeurIPS’21), Dec 6-12, 2021, Online.
[2] Arpit, D., Jastrzębski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., ... & Lacoste-Julien, S. (2017, July). A closer look at memorization in deep networks. In International Conference on Machine Learning (pp. 233-242). PMLR.
[3] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.
[4] M. Yang, Y. Li, Z. Huang, Z. Liu, P. Hu, X. Peng*, Partially View-aligned Representation Learning with Noise-robust Contrastive Loss, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 19-25, 2021. Online.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
