PCIe序与死锁
Background
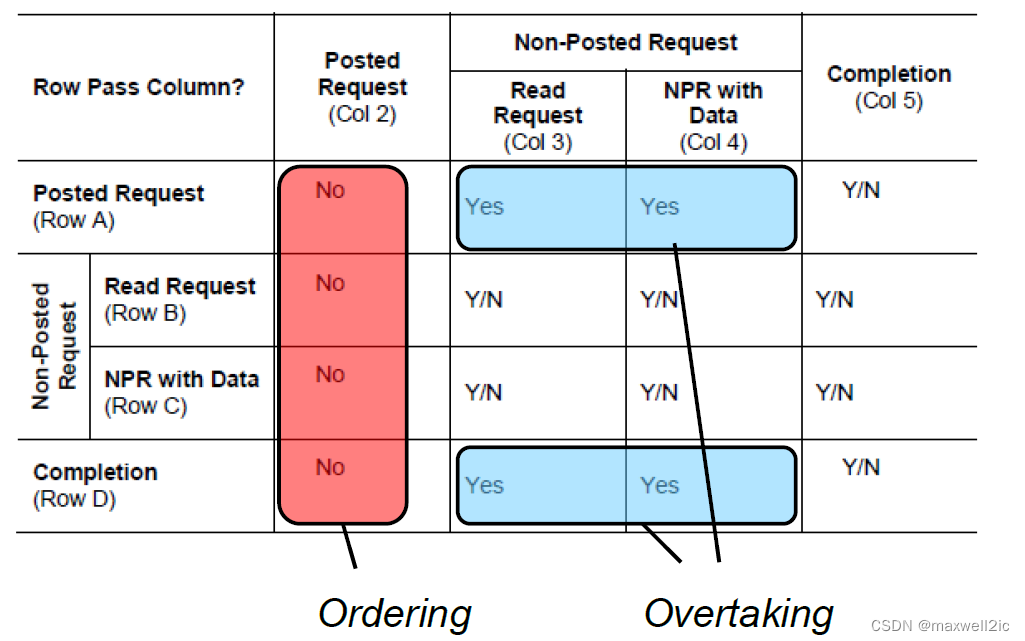
PCIe遵循x86的TSO模型,协议规定了各种TLP之间序的关系来保证memory consistency和避免死锁。在没有打开RO或IDO的情况下,order rule可以做如下简化
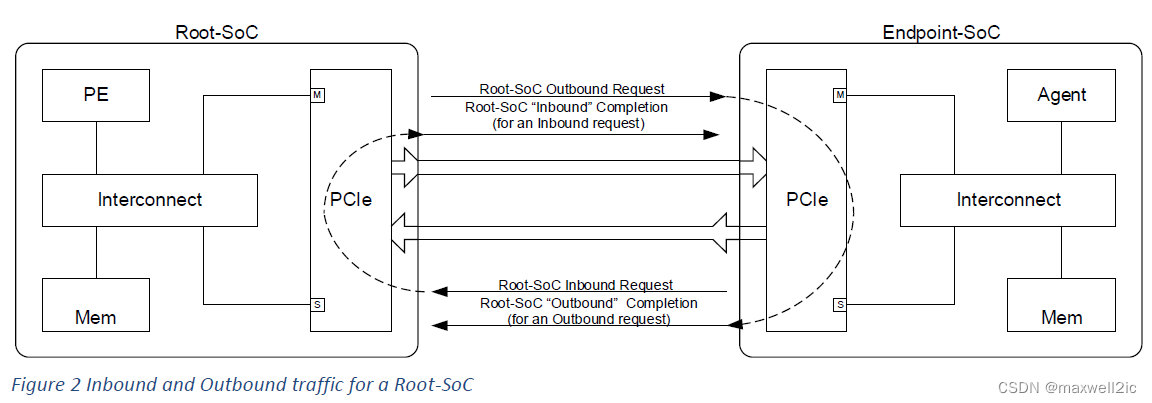
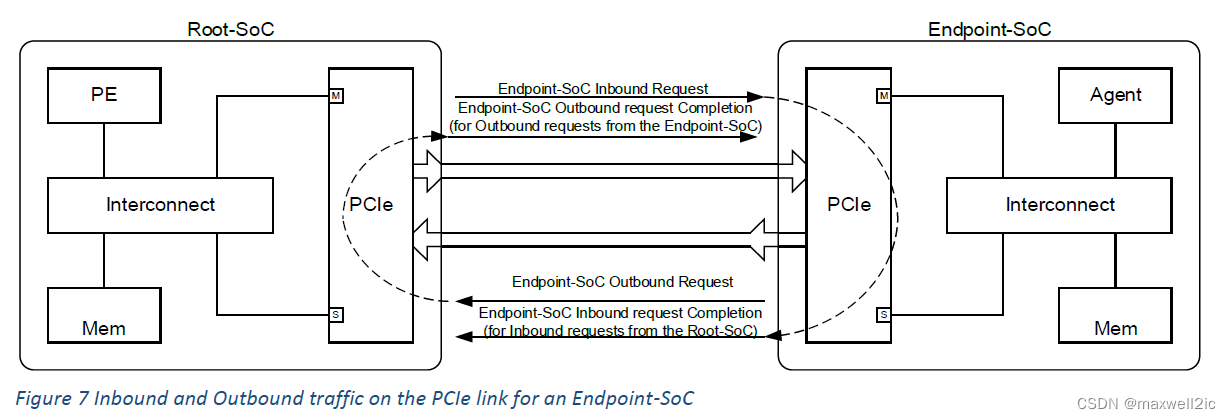
下面以一个RC直连EP的简单拓扑对上述ordering rule做说明
Overtaking Rule
Both request in the same direction
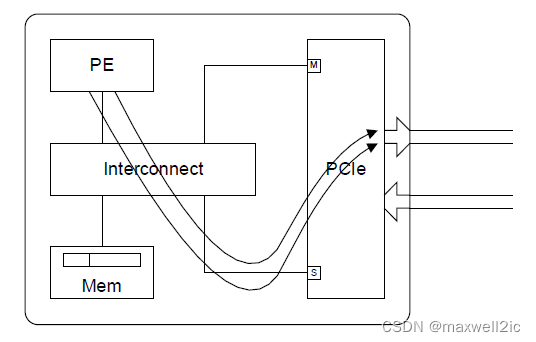

[A3] Posted Write must be able to overtake Read Request
PCIe必须保证收到的inbound/outbound写请求不能被前序的读请求所反压;
对于RC内部的P2P传输,从inbound接收再路由到outbound的写请求也不能被其通路上任何读请求所反压;
常见的风险点发生在:
- AXI读写排队的耦合点,制造了写等读,配合PCIe读等写,若成环必死锁
- SMMU内部做地址翻译依赖于PTW结果,制造了写等读(PTW属于读请求),若成环比死锁
- P2P传输对端有某种依赖才能接收写请求
[A4] Posted Write must be able to overtake Configuration Write
对于RC,只有outbound configuration write方向,其Master通常是Root-SoC内的ARM,常见的风险点发生在:
- P2P传输,某一笔inbound写请求路由到outbound时排在某个configuration write A后面,此时若无法超过该configuration write A,则会反压inbound写通路,进而反压后续inbound的completion,若该configuration write A的completion刚好排在其中,则会产生死锁
对于EP,只有inbound configuration write方向,此类TLP通常不会出PCIe控制器,所以一般没有死锁风险
Request and Completion in the same direction
[D3, D4] Inbound completion must be able to overtake Outbound Read Request or Configuration Write; Outbound Completion must be able to overtake Inbound Read Request or Configuration Write.

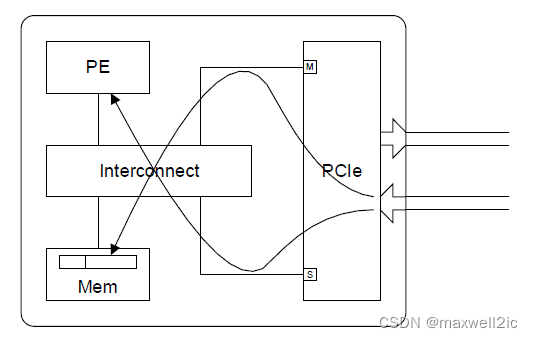
这两条通常没有风险,因为AXI协议的rdata和wdata是两个通道,之间没有耦合。即使是NSP这种读写合并的协议也是把wdata放在request,rdata放在response通道,互相没有依赖关系。
Ordering Rule
Both requests in the same direction
[A2, B2, C2] Posted Write, Read Request, or Configuration Write must not overtake Posted Write
写后写保序:比如data和flag都在对侧,生产者先写data,后写flag。预期消费者看到flag生效一定在data生效之后。所以通常PCIe转到AXI域之后awid都是相同的。
写后读保序:比如设备A通过P2P经过RC写data到设备B,然后写flag到RC,RC读到flag之后读设备B的data。消费者用read request把data推过去,预期RC一定能读到有效的data。
读后读不保序:no requirement。所以通常PCIe转到AXI域之后arid都是unique ID。
读后写不保序:一些特殊的应用中,软件可以根据返回的数值确定序是否正确
Request and Completion in the same direction
[D2] Inbound Completion must not overtake Outbound Posted Write; Outbound completion must not overtake Inbound Posted Write.
生产者的data在远端,flag在本地;消费者读生产者那一侧的flag,用completion把data勾回来,预期一定能读到有效的data。


Case Analysis
场景1:首先看一个最简单的EP单卡死锁场景
- J6作为EP与RC相连,PCIe的inbound wr和outbound rd业务同时执行,某一时刻EP SoC的interconnect内buffer资源占满,开始反压后续的请求(该interconnect内部读写排队,所以后续所有读写请求都会被反压)
- Inbound MemWr0在某个读写排队的interconnect(可能是FlexNoC的switch或者某一级mux,demux结构)等待outbound MemRd0的完成才能下发
- MemRd0需要等到RC返回CmplD0才能完成,并释放interconnect的outstanding资源
- CmplD0在PCIe链路上排在MemWr0后面,按照PCIe序的要求不能超过前面的Posted write(比如CmplD0在RC PCIe侧的tx buffer中等待前序MemWr0)
- 因为MemWr0被interconnect反压,所以一直无法下发,进而导致CmplD0一直在tx buffer里排队
- MemRd0等不到CmplD0无法完成,所以无法释放interconnect,进而继续反压MemWr0,最终导致死锁

场景2:如果没有读写排队,在Root-SoC中会发出CfgWr TLP,也有类似的问题
- MemWr0等待CfgWr0完成
- CfgWr0等带Cmpl0返回
- Cmpl0等待MemWr0下发,导致死锁

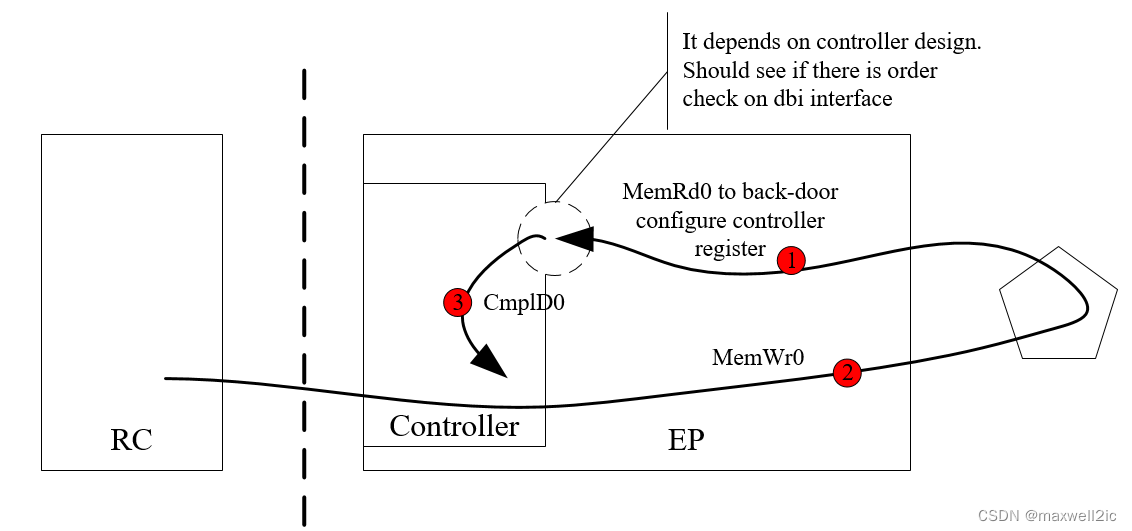
场景3:下面这种场景与场景1类似,但是否发生死锁取决于控制器的微架构
- 控制器内部的寄存器如DMA,ATU等通常会作为memory mapped register映射到BAR空间中,Host可以通过inbound访问启动EP的DMA或对ATU进行配置
- 从inbound下发的配置控制器内部寄存器的访问通常又会从控制器的master接口出来经过一个interconnect绕回到控制器的某个slave接口(对于SNPS就是dbi接口,对于PLDA是一个axi slave)
- 如果这个slave接口同普通的outbound接口一样也对read和write做order check,则会发生如下图的死锁
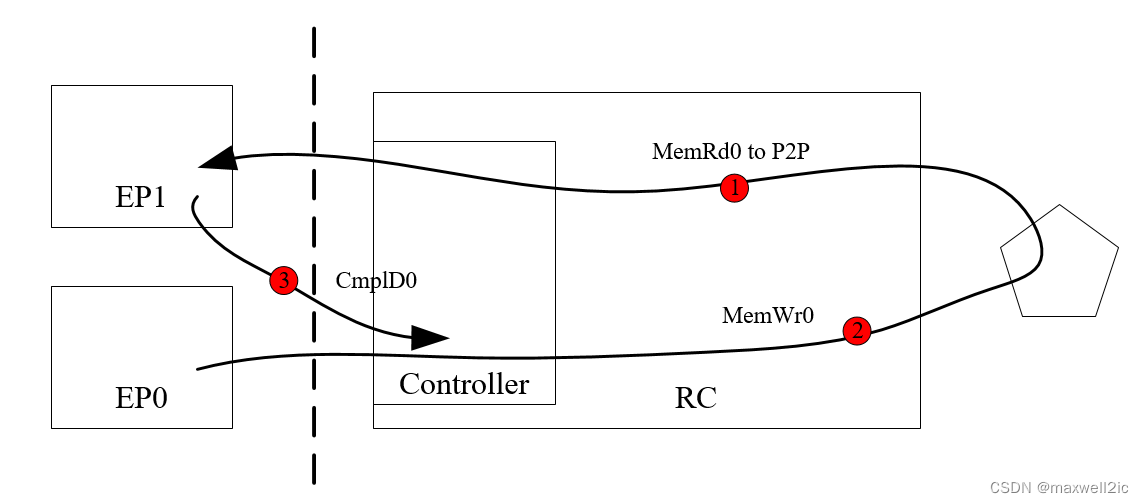
场景4:作为RC时需要处理P2P访问,此时即使没有片内master参与outbound也会产生下述死锁
- EP0发送第一笔P2P MemRd0访问,到RC后经过地址路由绕回到outbound映射到EP1的BAR地址
- EP0发送第二笔MemWr0访问(可以是P2P,也可以是访问RC的DDR),在读写排队的interconnect等待MemRd0完成
- MemRd0对应的CmplD0排在MemWr0后面无法完成,最终形成死锁
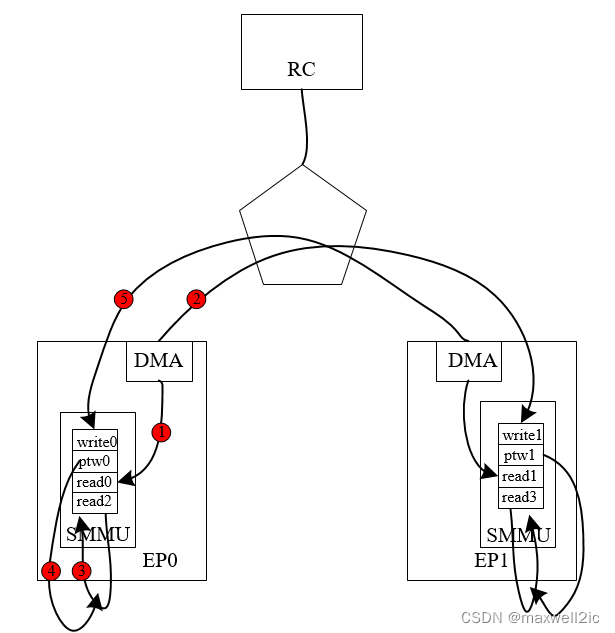
场景5:即使片内NoC把读写通路拆分,对于inbound通路上有SMMU的EP或RC,如果其PTW read通路与outbound read有耦合,也会产生死锁
- MemWr0触发SMMU执行PTW
- 该PTW read请求在某个interconnect等待outbound read MemRd0的完成才能下发
- PTW一直无法取回页表,导致MemWr0 stall在SMMU,进而阻塞后面的CmplD0
- CmplD0无法返回,MemRd0无法释放interconnect,继续阻塞PTW,形成死锁

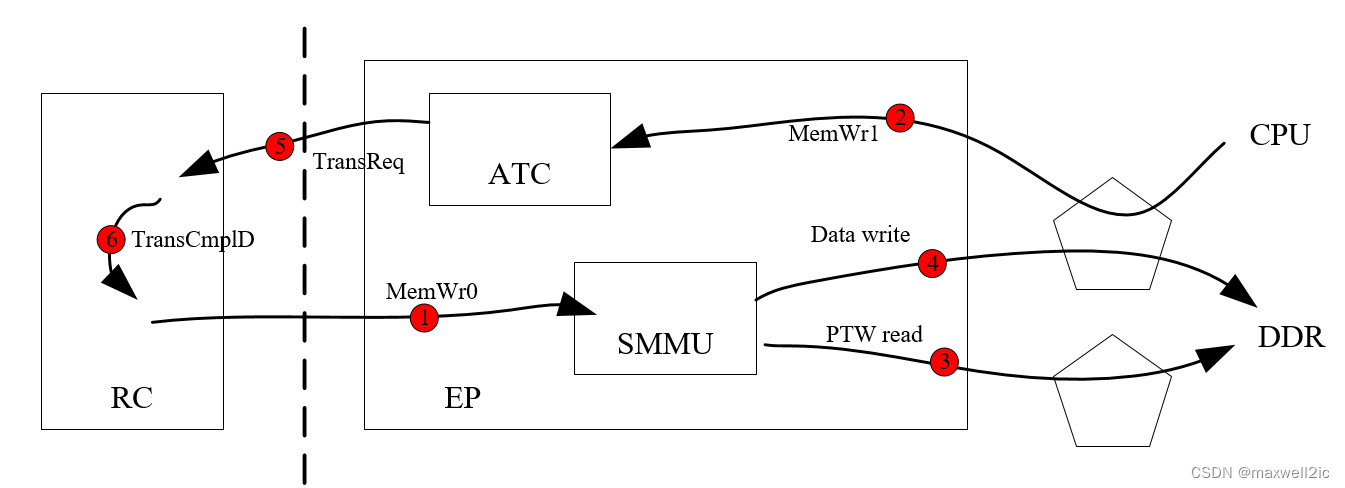
场景6:同样的场景也会发生在有ATC的EP设备中,只是死锁的源头从inbound write变成outbound write
- Inbound MemWr0在某个interconnect排在outbound MemWr1的后面无法下发
- MemWr1触发ATC产生translation request向RC IOMMU请求页表
- RC返回的translation completion排在MemWr0后面无法返回到ATC,则MemWr1始终被stall在ATC中,进而产生死锁
场景7:在P2P访问的拓扑中,只要两个EP结构对称,都有inbound与outbound耦合点,且读写排队,就会产生如下死锁
- EP0读EP1的BAR,发了很多read,并将对方的credit耗尽,此时R0攒在interconnect的buffer里,导致interconnect开始反压后续的请求
- 同样EP1读EP0的BAR,也最终导致R1攒在interconnect的buffer里,开始反压后续请求
- 此时在这一堆read前面的两笔write,w0和w1刚好被反压在interconnect前面
- 这两笔Posted MemWr阻塞后面的所有Non-Posted MemRd,outbound的read反压无法解除,interconnect无法释放,导致死锁

场景8:在某种结构中,即使没有读写排队或inbound/outbound耦合点,因为某些master的buffer与outstanding设计不合理,也会导致死锁
- EP0的DMA做P2P Push操作,发起read0从本地的DDR读数据;拿到数据之后发起write1写到EP2的BAR地址
- 如果write1产生反压,且DMA内部的buffer设计不合理,无法吸收后续read2的rdata,则inbound的response通路产生反压
- 如果SMMU的PTW通路没有专门设计,在某个地方与inbound read通路有耦合。则write0在SMMU触发的ptw0返回的页表刚好排在rdata2的后面,导致write0被stall在SMMU中。
- write0无法下发,进而反压EP1的DMA写。两边具有对称结构,EP1的ptw1也无法完成,导致write1无法下发。
- 两边DMA对称地都无法吸收后续rdata,ptw无法完成,write无法下发,最终产生死锁
Rule of Thumb
Bridge Topology Consideration
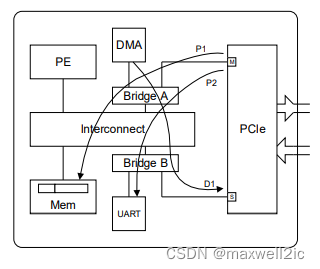
下图为一个典型的PCIe SoC架构:
- Bridge A位于PCIe inbound通路,与其他agent共享(本例子为DMA)
- Bridge B位域PCIe outbound通路,与其他peripheral共享(本例子为UART)
为了避免死锁,在Bridge上必须保证Posted write有dedicated resource可以下发而不被阻塞。
比如在Bridge A上,必须保证P1/P2上的posted write不被阻塞,即使其条件是让DMA的read D1或者DMA可以发Cfg write D1被反压。
同理在Bridge B上,必须保证D1上的posted write不被阻塞。
Intermediate Components
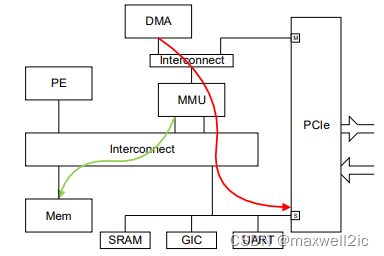
PCIe传输在某些系统组件上可能会要求先对main memory做读或写访问,才能让PCIe传输下发到目的地。
为了避免死锁,这些中间组件访问memory的通路一定不能被阻塞。
两个典型的例子如:
- PCIe inbound访问memory经过SMMU,传输下发依赖于QTW结果(图中绿色箭头),那么该条path与PCIe outbound访问(红色箭头)不能有耦合
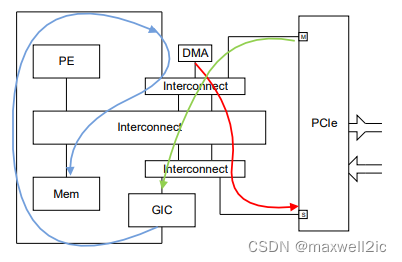
- MSI经过GIC(绿色箭头),而GIC需要访问memory中存储的GIC state(蓝色箭头)才能让让MSI传输下发,那么这两条path与PCIe outbound访问(红色箭头)不能有耦合
Reference
PCIe AMBA Integration Guide