datawhale8月组队学习《pandas数据处理与分析》(下)(文本、分类、时序数据)
文章目录
- 第八章 文本数据
- 8.1 str对象
- 8.1.1 str对象的设计意图
- 8.1.3 string类型
- 8.2 正则表达式基础
- 8.2.1 . 一般字符的匹配
- 8.2.2 元字符基础
- 8.2.3 简写字符集
- 8.3 文本处理的五类操作
- 8.3.1 `str.split `拆分
- 8.3.2 `str.join` 或 `str.cat `合并
- 8.3.3 匹配
- 8.3.5 提取
- 8.4、常用字符串函数
- 8.4.1 字母型函数
- 8.4.2 数值型函数
- 8.4.3 统计型函数
- 8.4.4 格式型函数
- 8.5 练习
- Ex1:房屋信息数据集
- Ex2:《权力的游戏》剧本数据集
- 第九章 分类数据
- 9.1 cat对象
- 9.1.1 cat对象的属性
- 9.1.2 类别的增加、删除和修改
- 9.2 有序分类
- 9.2.1 序的建立
- 9.2.2 排序和比较
- 9.3 区间类别
- 9.3.1 利用cut和qcut进行区间构造
- 9.3.2 一般区间的构造
- 9.3.3 区间的属性与方法
- 9.4 练习
- Ex1: 统计未出现的类别
- Ex2: 钻石数据集
- 第十章 时序数据
- 10.1 时序中的基本对象
- 10.2 时间戳
- 10.2.1 Timestamp的构造与属性
- 10.2.2 Datetime序列的生成
- 10.2.3 dt对象
- 10.2.4 时间戳的切片与索引
- 10.3 时间差
- 10.3.1 Timedelta的生成
- 10.2.2 Timedelta的运算
- 10.4 日期偏置
- 10.4.1 Offset对象
- 10.4.2 偏置字符串
- 10.5、时序中的滑窗与分组
- 10.5.1 滑动窗口
- 10.5.2 重采样
- 10.6 练习
- Ex1:太阳辐射数据集
- Ex2:水果销量数据集
课程资料《pandas数据处理与分析》、github地址、讲解视频、习题参考答案
pandas官网
第八章 文本数据
8.1 str对象
8.1.1 str对象的设计意图
str 对象是定义在 Index 或 Series上的属性,专门用于处理每个元素的文本内容,其内部定义了大量方法,因此对一个序列进行文本处理,首先需要获取其 str 对象。在Python标准库中也有 str 模块,为了使用上的便利,在 pandas 的50个 str 对象方法中,有31个是和标准库中的 str 模块方法同名且功能一致,例如字母转为大写的操作:
var = 'abcd'
str.upper(var) # Python内置str模块
Out[4]: 'ABCD'
s = pd.Series(['abcd', 'efg', 'hi'])
s.str
Out[6]: <pandas.core.strings.accessor.StringMethods at 0x2b796892d60>
s.str.upper() # pandas中str对象上的upper方法
Out[7]:
0 ABCD
1 EFG
2 HI
dtype: object
8.1.2 []索引器
对于 str 对象而言,可理解为其对字符串进行了序列化的操作,例如在一般的字符串中,通过 [] 可以取出某个位置的元素,同时也能通过切片得到子串。
pandas中过对 str 对象使用 [] 索引器,可以完成完全一致的功能,并且如果超出范围则返回缺失值:
s.str[0]
Out[10]:
0 a
1 e
2 h
dtype: object
s.str[-1: 0: -2]
Out[11]:
0 db
1 g
2 i
dtype: object
s.str[2]
Out[12]:
0 c
1 g
2 NaN
dtype: object
import numpy as np
import pandas as pd
s = pd.Series(['abcd', 'efg', 'hi'])
s.str[0]
0 a
1 e
2 h
dtype: object
8.1.3 string类型
在上一章提到,从 pandas 的 1.0.0 版本开始,引入了 string 类型,其引入的动机在于:原来所有的字符串类型都会以 object 类型的 Series 进行存储,但 object 类型只应当存储混合类型,例如同时存储浮点、字符串、字典、列表、自定义类型等,因此字符串有必要同数值型或 category 一样,具有自己的数据存储类型,从而引入了 string 类型。
总体上说,绝大多数对于 object 和 string 类型的序列使用 str 对象方法产生的结果是一致,但是在下面提到的两点上有较大差异:
- 二者对于某些对象的 str 序列化方法不同。
可迭代(Iterable)对象包括但不限于字符串、字典、列表。对于一个可迭代对象,string类型和object类型对它们的序列化方式不同,序列化后str对象返回结果也可能不同。例如:
s = pd.Series([{1: 'temp_1', 2: 'temp_2'}, ['a', 'b'], 0.5, 'my_string'])
s
0 {1: 'temp_1', 2: 'temp_2'}
1 [a, b]
2 0.5
3 my_string
dtype: object
s.str[1] # 对每个元素取[1]的操作
0 temp_1
1 b
2 NaN
3 y
dtype: object
s.astype('string').str[1]
0 1
1 '
2 .
3 y
dtype: string
除了最后一个字符串元素,前三个元素返回的值都不同,其原因在于:
- 当序列类型为
object时,是对于每一个元素进行 [] 索引,因此对于字典而言,返回temp_1字符串,对于列表则返回第二个值,而第三个为不可迭代对象,返回缺失值,第四个是对字符串进行 [] 索引。 - string 类型的
str对象先把整个元素转为字面意义的字符串,例如对于列表而言,第一个元素即 “{”,而对于最后一个字符串元素而言,恰好转化前后的表示方法一致,因此结果和object类型一致。
- string 类型是 Nullable 类型,但 object 不是
这意味着 string 类型的序列,如果调用的 str 方法返回值为整数 Series 和布尔 Series 时,其分别对应的 dtype 是 Int 和 boolean 的 Nullable 类型,而 object 类型则会分别返回 int/float 和 bool/object ,不过这取决于缺失值的存在与否。
同时,字符串的比较操作,也具有相似的特性, string 返回 Nullable 类型,但 object 不会。
s = pd.Series(['a'])
s.str.len()
Out[17]:
0 1
dtype: int64
s.astype('string').str.len()
Out[18]:
0 1
dtype: Int64
s == 'a'
Out[19]:
0 True
dtype: bool
s.astype('string') == 'a'
Out[20]:
0 True
dtype: boolean
s = pd.Series(['a', np.nan]) # 带有缺失值
s.str.len()
Out[22]:
0 1.0
1 NaN
dtype: float64
s.astype('string').str.len()
Out[23]:
0 1
1 <NA>
dtype: Int64
s == 'a'
Out[24]:
0 True
1 False
dtype: bool
s.astype('string') == 'a'
Out[25]:
0 True
1 <NA>
dtype: boolean
对于全体元素为数值类型的序列,即使其类型为 object 或者 category 也不允许直接使用 str 属性。如果需要把数字当成 string 类型处理,可以使用 astype 强制转换为 string 类型的 Series :
s = pd.Series([12, 345, 6789])
s.astype('string').str[1]
Out[27]:
0 2
1 4
2 7
dtype: string
8.2 正则表达式基础
这一节的两个表格来自于 learn-regex-zh 这个关于正则表达式项目,其使用 MIT 开源许可协议。这里只是介绍正则表达式的基本用法,需要系统学习的读者可参考《Python3 正则表达式》,或者《 正则表达式必知必会 》这本书
8.2.1 . 一般字符的匹配
正则表达式是一种按照某种正则模式,从左到右匹配字符串中内容的一种工具。对于一般的字符而言,它可以找到其所在的位置,这里为了演示便利,使用了 python 中 re 模块的 findall 函数来匹配所有出现过但不重叠的模式,第一个参数是正则表达式,第二个参数是待匹配的字符串。例如,在下面的字符串中找出 apple :
import re
re.findall(r'Apple', 'Apple! This Is an Apple!') # 字符串从左到右依次匹配
Out[29]: ['Apple', 'Apple']
8.2.2 元字符基础
| 元字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| [ ] | 字符类,匹配方括号中包含的任意字符 |
| [^ ] | 否定字符类,匹配方括号中不包含的任意字符 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次。比如r’d+'就是匹配数字串,r’d’就是匹配单个数字 |
| ? | 匹配前面的子表达式零次或一次,非贪婪方式 |
| {n,m} | 花括号,匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| (xyz) | 字符组,按照确切的顺序匹配字符xyz |
| | | 分支结构,匹配符号之前的字符或后面的字符 |
| \ | 转义符,它可以还原元字符原来的含义 |
| ^ | 匹配行的开始 |
| $ | 匹配行的结束 |
import re
re.findall(r'.', 'abc')
Out[30]: ['a', 'b', 'c']
re.findall(r'[ac]', 'abc') # []中有的子串都匹配
Out[31]: ['a', 'c']
re.findall(r'[^ac]', 'abc')
Out[32]: ['b']
re.findall(r'[ab]{2}', 'aaaabbbb') # {n}指匹配n次
Out[33]: ['aa', 'aa', 'bb', 'bb']
re.findall(r'aaa|bbc|ca', 'aacabbcbbc') # 匹配前面的或者后面的字符串
Out[34]: ['ca', 'bbc', 'bbc']
# 上面的元字符都有特殊含义,要匹配其本来的意思就得用\进行转义。
"""
1. ?匹配的是前一个字符,即被转义的\,所以|前面的内容就是匹配a\或者a,但是结果里面没有a\,相当于只能匹配a。
2. |右边是a\*,转义之后匹配a*,对于竖线而言左边优先级高于右边
3. 然后看目标字符串aa?a*a,第一个a匹配左边,第二个a匹配左边,第三个a虽然后面有*,
但是左边优先级高, 还是匹配左边,剩下一个a还是左边,所以结果是四个a
"""
re.findall(r'a\\?|a\*', 'aa?a*a') # 第二次先匹配到a,就不会匹配a?。a*同理。
Out[35]: ['a', 'a', 'a', 'a']
# 这里匹配不到是因为目标串'aa\a*a'中,\a是python的转义字符(\a\b\t\n等),所以匹配不到。
# 如果是'aa\s*a'之内非python的转义字符,或者'aa\\s*a',或者r'aa\\s*a'就可以匹配到\字符。
re.findall(r'\\', 'aa\a*a')
[]
re.findall(r'a?.', 'abaacadaae')
Out[36]: ['ab', 'aa', 'c', 'ad', 'aa', 'e']
re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10') # 多个匹配模式,返回元组列表
[('width', '20'), ('height', '10')]
8.2.3 简写字符集
则表达式中还有一类简写字符集,其等价于一组字符的集合:
| 简写 | 描述 |
|---|---|
| \w | 匹配所有字母、数字、下划线: [a-zA-Z0-9_] |
| \W | 匹配非字母和数字的字符: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配空格符: [\t\n\f\r\p{Z}] |
| \S | 匹配非空格符: [^\s] |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
re.findall(r'.s', 'Apple! This Is an Apple!')
Out[37]: ['is', 'Is']
re.findall(r'\w{2}', '09 8? 7w c_ 9q p@') # 匹配任意数字字母下划线的组合,但必须是两次
Out[38]: ['09', '7w', 'c_', '9q']
re.findall(r'\w\W\B', '09 8? 7w c_ 9q p@') # 匹配的是两个字符串,前一个是任意数字字母下划线(\W),后一个不是(\W)
Out[39]: ['8?', 'p@']
re.findall(r'.\s.', 'Constant dropping wears the stone.')
Out[40]: ['t d', 'g w', 's t', 'e s']
re.findall(r'上海市(.{2,3}区)(.{2,3}路)(\d+号)',
'上海市黄浦区方浜中路249号 上海市宝山区密山路5号')
Out[41]: [('黄浦区', '方浜中路', '249号'), ('宝山区', '密山路', '5号')]
8.3 文本处理的五类操作
8.3.1 str.split 拆分
str.split 能够把字符串的列进行拆分,其中第一个参数为正则表达式,可选参数包括从左到右的最大拆分次数 n ,是否展开为多个列 expand 。
s = pd.Series(['上海市黄浦区方浜中路249号',
'上海市宝山区密山路5号'])
s.str.split('[市区路]') # 每条结果为一行,相当于Series
Out[43]:
0 [上海, 黄浦, 方浜中, 249号]
1 [上海, 宝山, 密山, 5号]
dtype: object
s.str.split('[市区路]', n=2, expand=True) # 结果分成多个列展示,结果相当于DataFrame
Out[44]:
0 1 2
0 上海 黄浦 方浜中路249号
1 上海 宝山 密山路5号
类似的函数是 str.rsplit ,其区别在于使用 n 参数的时候是从右到左限制最大拆分次数。但是当前版本下 rsplit 因为 bug 而无法使用正则表达式进行分割:
s.str.rsplit('[市区路]', n=2, expand=True)
Out[45]:
0
0 上海市黄浦区方浜中路249号
1 上海市宝山区密山路5号
8.3.2 str.join 或 str.cat 合并
str.join表示用某个连接符把 Series 中的字符串列表连接起来,如果列表中出现了非字符串元素则返回缺失值。str.cat用于合并两个序列,主要参数为:- sep:连接符、
- join:连接形式默认为以索引为键的左连接
- na_rep:缺失值替代符号
s = pd.Series([['a','b'], [1, 'a'], [['a', 'b'], 'c']])
s.str.join('-')
Out[47]:
0 a-b
1 NaN
2 NaN
dtype: object
s1 = pd.Series(['a','b'])
s2 = pd.Series(['cat','dog'])
s1.str.cat(s2,sep='-')
Out[50]:
0 a-cat
1 b-dog
dtype: object
s2.index = [1, 2]
s1.str.cat(s2, sep='-', na_rep='?', join='outer')
Out[52]:
0 a-?
1 b-cat
2 ?-dog
dtype: object
8.3.3 匹配
str.contains返回了每个字符串是否包含正则模式的布尔序列:
s = pd.Series(['my cat', 'he is fat', 'railway station'])
s.str.contains('\s\wat')
0 True
1 True
2 False
dtype: bool
str.startswith和str.endswith返回了每个字符串以给定模式为开始和结束的布尔序列,它们都不支持正则表达式:
s.str.startswith('my')
0 True
1 False
2 False
dtype: bool
s.str.endswith('t')
0 True
1 True
2 False
dtype: bool
str.match可以用正则表达式来检测开始或结束字符串的模式,其返回了每个字符串起始处是否符合给定正则模式的布尔序列。当然,这些也能通过在str.contains的正则中使用^和$来实现。(貌似没有python里的search方法)
s.str.match('m|h')
s.str.contains('^[m|h]') # 二者等价
0 True
1 True
2 False
dtype: bool
s.str[::-1].str.match('ta[f|g]|n') # 反转后匹配
s.str.contains('[f|g]at|n$') # 二者等价
0 False
1 True
2 True
dtype: bool
str.find与str.rfind返回索引的匹配函数,其分别返回从左到右和从右到左第一次匹配的位置的索引,未找到则返回-1。需要注意的是这两个函数不支持正则匹配,只能用于字符子串的匹配:
s = pd.Series(['This is an apple. That is not an apple.'])
s.str.find('apple')
Out[62]:
0 11
dtype: int64
s.str.rfind('apple')
Out[63]:
0 33
dtype: int64
- 替换
str.replace和replace并不是一个函数,在使用字符串替换时应当使用前者。
s = pd.Series(['a_1_b','c_?'])
# regex默认为True,表示是正则模式,否则第一个参数内容表示是单纯的字符串,也就是匹配字符串\d|\?
s.str.replace('\d|\?', 'new', regex=True)
0 a_new_b
1 c_new
dtype: object
当需要对不同部分进行有差别的替换时,可以利用子组的方法,并且此时可以通过传入自定义的替换函数来分别进行处理,注意group(k)代表匹配到的第k个子组(圆括号之间的内容):
s = pd.Series(['上海市黄浦区方浜中路249号',
'上海市宝山区密山路5号',
'北京市昌平区北农路2号'])
pat = '(\w+市)(\w+区)(\w+路)(\d+号)'
city = {'上海市': 'Shanghai', '北京市': 'Beijing'}
district = {'昌平区': 'CP District',
'黄浦区': 'HP District',
'宝山区': 'BS District'}
road = {'方浜中路': 'Mid Fangbin Road',
'密山路': 'Mishan Road',
'北农路': 'Beinong Road'}
def my_func(m):
str_city = city[m.group(1)]
str_district = district[m.group(2)]
str_road = road[m.group(3)]
str_no = 'No. ' + m.group(4)[:-1]
return ' '.join([str_city,
str_district,
str_road,
str_no])
s.str.replace(pat, my_func, regex=True)
0 Shanghai HP District Mid Fangbin Road No. 249
1 Shanghai BS District Mishan Road No. 5
2 Beijing CP District Beinong Road No. 2
dtype: object
这里的数字标识并不直观,可以使用命名子组更加清晰地写出子组代表的含义:
# 将各个子组进行命名
pat = '(?P<市名>\w+市)(?P<区名>\w+区)(?P<路名>\w+路)(?P<编号>\d+号)'
def my_func(m):
str_city = city[m.group('市名')]
str_district = district[m.group('区名')]
str_road = road[m.group('路名')]
str_no = 'No. ' + m.group('编号')[:-1]
return ' '.join([str_city,
str_district,
str_road,
str_no])
s.str.replace(pat, my_func, regex=True)
0 Shanghai HP District Mid Fangbin Road No. 249
1 Shanghai BS District Mishan Road No. 5
2 Beijing CP District Beinong Road No. 2
dtype: object
这里虽然看起来有些繁杂,但是实际数据处理中对应的替换,一般都会通过代码来获取数据从而构造字典映射,在具体写法上会简洁的多。
8.3.5 提取
str.extract进行提取:提取既可以认为是一种返回具体元素值(而不是布尔值或元素对应的索引位置)的匹配操作,也可以认为是一种特殊的拆分操作。前面提到的str.split例子中会把分隔符去除,这并不是用户想要的效果,这时候就可以用str.extract进行提取:
s.str.split('[市区路]')
Out[43]:
0 [上海, 黄浦, 方浜中, 249号]
1 [上海, 宝山, 密山, 5号]
dtype: object
pat = '(\w+市)(\w+区)(\w+路)(\d+号)'
s.str.extract(pat)
Out[78]:
0 1 2 3
0 上海市 黄浦区 方浜中路 249号
1 上海市 宝山区 密山路 5号
2 北京市 昌平区 北农路 2号
通过子组的命名,可以直接对新生成DataFrame的列命名:
pat = '(?P<市名>\w+市)(?P<区名>\w+区)(?P<路名>\w+路)(?P<编号>\d+号)'
s.str.extract(pat)
Out[79]:
市名 区名 路名 编号
0 上海市 黄浦区 方浜中路 249号
1 上海市 宝山区 密山路 5号
2 北京市 昌平区 北农路 2号
str.extractall:不同于str.extract只匹配一次,它会把所有符合条件的模式全部匹配出来,如果存在多个结果,则以多级索引的方式存储:
s = pd.Series(['A135T15,A26S5','B674S2,B25T6'], index = ['my_A','my_B'])
pat = '[A|B](\d+)[T|S](\d+)'
s.str.extractall(pat)
Out[83]:
0 1
match
my_A 0 135 15
1 26 5
my_B 0 674 2
1 25 6
pat_with_name = '[A|B](?P<name1>\d+)[T|S](?P<name2>\d+)'
s.str.extractall(pat_with_name)
Out[84]:
name1 name2
match
my_A 0 135 15
1 26 5
my_B 0 674 2
1 25 6
str.findall:功能类似于str.extractall,区别在于前者把结果存入列表中,而后者处理为多级索引,每个行只对应一组匹配,而不是把所有匹配组合构成列表。
s.str.findall(pat)
my_A [(135, 15), (26, 5)]
my_B [(674, 2), (25, 6)]
dtype: object
8.4、常用字符串函数
除了上述介绍的五类字符串操作有关的函数之外,str对象上还定义了一些实用的其他方法,在此进行介绍。
8.4.1 字母型函数
upper, lower, title, capitalize, swapcase这五个函数主要用于字母的大小写转化,从下面的例子中就容易领会其功能:
s = pd.Series(['lower', 'CAPITALS', 'this is a sentence', 'SwApCaSe'])
s.str.upper()
Out[87]:
0 LOWER
1 CAPITALS
2 THIS IS A SENTENCE
3 SWAPCASE
dtype: object
s.str.lower()
Out[88]:
0 lower
1 capitals
2 this is a sentence
3 swapcase
dtype: object
s.str.title() # 首字母大写
Out[89]:
0 Lower
1 Capitals
2 This Is A Sentence
3 Swapcase
dtype: object
s.str.capitalize() # 句首大写
Out[90]:
0 Lower
1 Capitals
2 This is a sentence
3 Swapcase
dtype: object
s.str.swapcase() # 将大写转换为小写,将小写转换为大写。
Out[91]:
0 LOWER
1 capitals
2 THIS IS A SENTENCE
3 sWaPcAsE
dtype: object
s.str.casefold() # 去除字符串中所有大小写区别
0 lower
1 capitals
2 this is a sentence
3 swapcase
8.4.2 数值型函数
这里着重需要介绍的是pd.to_numeric方法,它虽然不是str对象上的方法,但是能够对字符格式的数值进行快速转换和筛选。其主要参数包括:
errors:非数值的处理模式。对于不能转换为数值的有三种errors选项:raise:直接报错,默认选项coerce:设为缺失值ignore:保持原来的字符串。
downcast:转换类型,转成 ‘integer’, ‘signed’, ‘unsigned’, 或 ‘float’的最小dtype。比如可以转成float32就不会转成float64。
s = pd.Series(['1', '2.2', '2e', '??', '-2.1', '0'])
pd.to_numeric(s, errors='ignore')
Out[93]:
0 1
1 2.2
2 2e
3 ??
4 -2.1
5 0
dtype: object
pd.to_numeric(s, errors='coerce')
Out[94]:
0 1.0
1 2.2
2 NaN
3 NaN
4 -2.1
5 0.0
dtype: float64
在数据清洗时,可以利用coerce的设定,快速查看非数值型的行:
s[pd.to_numeric(s, errors='coerce').isna()]
Out[95]:
2 2e
3 ??
dtype: object
8.4.3 统计型函数
count和len的作用分别是返回出现正则模式的次数和字符串的长度:
s = pd.Series(['cat rat fat at', 'get feed sheet heat'])
s.str.count('[r|f]at|ee') # |左右两种子串都匹配了两次
Out[97]:
0 2
1 2
dtype: int64
s.str.len()
Out[98]:
0 14
1 19
dtype: int64
8.4.4 格式型函数
格式型函数主要分为两类,第一种是除空型,第二种是填充型。其中,第一类函数一共有三种,它们分别是strip, rstrip, lstrip,分别代表去除两侧空格、右侧空格和左侧空格。这些函数在数据清洗时是有用的,特别是列名含有非法空格的时候。
my_index = pd.Index([' col1', 'col2 ', ' col3 '])
my_index.str.strip().str.len()
Out[100]: Int64Index([4, 4, 4], dtype='int64')
my_index.str.rstrip().str.len()
Out[101]: Int64Index([5, 4, 5], dtype='int64')
my_index.str.lstrip().str.len()
Out[102]: Int64Index([4, 5, 5], dtype='int64')
对于填充型函数而言,pad是最灵活的,它可以选定字符串长度、填充的方向和填充内容:
s = pd.Series(['a','b','c'])
s.str.pad(5,'left','*')
Out[104]:
0 ****a
1 ****b
2 ****c
dtype: object
s.str.pad(5,'right','*')
Out[105]:
0 a****
1 b****
2 c****
dtype: object
s.str.pad(5,'both','*')
Out[106]:
0 **a**
1 **b**
2 **c**
dtype: object
上述的三种情况可以分别用rjust, ljust, center来等效完成,需要注意ljust是指右侧填充而不是左侧填充:
s.str.rjust(5, '*')
Out[107]:
0 ****a
1 ****b
2 ****c
dtype: object
s.str.ljust(5, '*')
Out[108]:
0 a****
1 b****
2 c****
dtype: object
s.str.center(5, '*')
Out[109]:
0 **a**
1 **b**
2 **c**
dtype: object
在读取excel文件时,经常会出现数字前补0的需求,例如证券代码读入的时候会把"000007"作为数值7来处理,pandas中除了可以使用上面的左侧填充函数进行操作之外,还可用zfill来实现。
s = pd.Series([7, 155, 303000]).astype('string')
s.str.pad(6,'left','0')
Out[111]:
0 000007
1 000155
2 303000
dtype: string
s.str.rjust(6,'0')
Out[112]:
0 000007
1 000155
2 303000
dtype: string
s.str.zfill(6)
Out[113]:
0 000007
1 000155
2 303000
dtype: string
8.5 练习
Ex1:房屋信息数据集
现有一份房屋信息数据集如下:
df = pd.read_excel('../data/house_info.xls', usecols=['floor','year','area','price'])
df.head(3)
Out[115]:
floor year area price
0 高层(共6层) 1986年建 58.23㎡ 155万
1 中层(共20层) 2020年建 88㎡ 155万
2 低层(共28层) 2010年建 89.33㎡ 365万
- 将year列改为整数年份存储。
- 将floor列替换为Level, Highest两列,其中的元素分别为string类型的层类别(高层、中层、低层)与整数类型的最高层数。
- 计算房屋每平米的均价avg_price,以***元/平米的格式存储到表中,其中***为整数
- 将
year列改为整数年份存储。
"""
整个序列需要先转成Nullable类型的String类型,取出年份,再将年份转为Int64类型。
注意,转换的类型是Int64不是int,否则报错。即使astype加参数errors='ignore'跳过缺失值,
转成int后,序列还有缺失值所以,还是变成了object。
而整个序列转为Int,就还是Int类型,缺失值变成了 pd.NA 。
"""
df = df.convert_dtypes()
df['year']=df['year'].str.replace('\D','',regex=True).astype('Int64')
df.loc[df.year.notna()]['year'].head()
0 1986
1 2020
2 2010
3 2014
4 2015
Name: year, Length: 12850, dtype: Int64
参考答案:
不知道为啥
pd.to_numeric(df.year.str[:-2],downcast="integer")类型为float32,不应该是整型么
df.year = pd.to_numeric(df.year.str[:-2]).astype('Int64')
df.loc[df.year.notna()]['year']
- 将
floor列替换为Level, Highest两列,其中的元素分别为string类型的层类别(高层、中层、低层)与整数类型的最高层数。
pat = '(?P<Level>\w+层)(?P<Highest>\(\w+层)'
df2=df['floor'].str.extract(pat) # 拆分成两列,第二列还是(共6层得形式,所以还的替换一次
df=pd.concat([df,df2],axis=1).convert_dtypes() # 新增列拼接在后面,再次转为Nullable类型
df['Highest']=df['Highest'].str.replace('\D+','',regex=True).astype('Int64')
df=df[['Level','Highest','year','area','price']]
df.head()
Level Highest year area price
0 高层 6 1986 58.23㎡ 155万
1 中层 20 2020 88㎡ 155万
2 低层 28 2010 89.33㎡ 365万
3 低层 20 2014 82㎡ 308万
4 高层 1 2015 98㎡ 117万
# 参考答案。感觉是第二个字段加了中文的()可以准备匹配出数字,但是不好直接命令子组了
pat = '(\w层)(共(\d+)层)'
new_cols = df.floor.str.extract(pat).rename(
columns={0:'Level', 1:'Highest'})
df = pd.concat([df.drop(columns=['floor']), new_cols], 1)
df.head(3)
Out[163]:
year area price Level Highest
0 1986 58.23㎡ 155万 高层 6
1 2020 88㎡ 155万 中层 20
2 2010 89.33㎡ 365万 低层 28
- 计算房屋每平米的均价
avg_price,以***元/平米的格式存储到表中,其中***为整数。
"""
str.findall返回的结果都是列表,只能用apply取值去掉列表形式
参考答案用pd.to_numeric(df.area.str[:-1])更简洁
由于area和price都没有缺失值,所以可以直接转类型
"""
df['new_area']=df['area'].str.findall(r'\d+.\d+|\d+').apply(lambda x:float(x[0]))
df['new_price']=df['price'].str.replace('\D+','',regex=True).astype('int64')
df.eval('avg_price=10000*new_price/new_area',inplace=True)
# 最后均价这一列小数转整型直接用.astype('int')就行,我还准备.apply(lambda x:int(round(x,0)))
# 最后数字+元/平米写法更简单
df['avg_price']=df['avg_price'].astype('int').astype('string')+'元/平米'
del df['new_area'],df['new_price']
df.head()
Level Highest year area price avg_price
0 高层 6 1986 58.23㎡ 155万 26618元/平米
1 中层 20 2020 88㎡ 155万 17613元/平米
2 低层 28 2010 89.33㎡ 365万 40859元/平米
3 低层 20 2014 82㎡ 308万 37560元/平米
4 高层 1 2015 98㎡ 117万 11938元/平米
# 参考答案
s_area = pd.to_numeric(df.area.str[:-1])
s_price = pd.to_numeric(df.price.str[:-1])
df['avg_price'] = ((s_price/s_area)*10000).astype(
'int').astype('string') + '元/平米'
df.head(3)
Out[167]:
year area price Level Highest avg_price
0 1986 58.23㎡ 155万 高层 6 26618元/平米
1 2020 88㎡ 155万 中层 20 17613元/平米
2 2010 89.33㎡ 365万 低层 28 40859元/平米
Ex2:《权力的游戏》剧本数据集
现有一份权力的游戏剧本数据集如下:
df = pd.read_csv('../data/script.csv')
df.head(3)
Out[115]:
Out[117]:
Release Date Season Episode Episode Title Name Sentence
0 2011-04-17 Season 1 Episode 1 Winter is Coming waymar royce What do you expect? They're savages. One lot s...
1 2011-04-17 Season 1 Episode 1 Winter is Coming will I've never seen wildlings do a thing like this...
2 2011-04-17 Season 1 Episode 1 Winter is Coming waymar royce
- 计算每一个Episode的台词条数。
- 以空格为单词的分割符号,请求出单句台词平均单词量最多的前五个人。
- 若某人的台词中含有问号,那么下一个说台词的人即为回答者。若上一人台词中含有 𝑛 个问号,则认为回答者回答了 𝑛 个问题,请求出回答最多问题的前五个人。
- 计算每一个
Episode的台词条数。
df.columns =df.columns.str.strip() # 列名中有空格
df.groupby(['Season','Episode'])['Sentence'].count().sort_values(ascending=False).head()
season Episode
Season 7 Episode 5 505
Season 3 Episode 2 480
Season 4 Episode 1 475
Season 3 Episode 5 440
Season 2 Episode 2 432
- 以空格为单词的分割符号,请求出单句台词平均单词量最多的前五个人。
# str.count是可以计算每个字符串被正则匹配了多少次,+1就是单词数
df['len_words']=df['Sentence'].str.count(r' ')+1
df.groupby(['Name'])['len_words'].mean().sort_values(ascending=False).head()
Name
male singer 109.000000
slave owner 77.000000
manderly 62.000000
lollys stokeworth 62.000000
dothraki matron 56.666667
Name: len_words, dtype: float64
- 若某人的台词中含有问号,那么下一个说台词的人即为回答者。若上一人台词中含有 n n n个问号,则认为回答者回答了 n n n个问题,请求出回答最多问题的前五个人。
df['Sentence'].str.count(r'\?') # 计算每人提问数
ls=pd.concat([pd.Series(0),ls]).reset_index(drop=True)# 首行填0
del ls[23911] # 末行删去
df['len_questions']=ls
df.groupby(['Name'])['len_questions'].sum().sort_values(ascending=False).head()
Name
tyrion lannister 527
jon snow 374
jaime lannister 283
arya stark 265
cersei lannister 246
Name: len_questions, dtype: int64
# 参考答案
s = pd.Series(df.Sentence.values, index=df.Name.shift(-1))
s.str.count('\?').groupby('Name').sum().sort_values(ascending=False).head()
第九章 分类数据
import numpy as np
import pandas as pd
9.1 cat对象
9.1.1 cat对象的属性
在pandas中提供了category类型,使用户能够处理分类类型的变量,将一个普通序列转换成分类变量可以使用astype方法。
df = pd.read_csv('data/learn_pandas.csv',
usecols = ['Grade', 'Name', 'Gender', 'Height', 'Weight'])
s = df.Grade.astype('category')
s.head()
Out[5]:
0 Freshman
1 Freshman
2 Senior
3 Sophomore
4 Sophomore
Name: Grade, dtype: category
Categories (4, object): ['Freshman', 'Junior', 'Senior', 'Sophomore']
在一个分类类型的Series中定义了cat对象,它和上一章中介绍的str对象类似,定义了一些属性和方法来进行分类类别的操作。
s.cat
Out[6]: <pandas.core.arrays.categorical.CategoricalAccessor object at 0x000002B7974C20A0>
cat的属性:
cat.categories:查看类别的本身,它以Index类型存储cat.ordered:类别是否有序cat.codes:访问类别编号。每一个序列的类别会被赋予唯一的整数编号,它们的编号取决于cat.categories中的顺序
s.cat.categories
Out[7]: Index(['Freshman', 'Junior', 'Senior', 'Sophomore'], dtype='object')
s.cat.ordered
Out[8]: False
s.cat.codes.head()
Out[9]:
0 0
1 0
2 2
3 3
4 3
dtype: int8
9.1.2 类别的增加、删除和修改
通过cat对象的categories属性能够完成对类别的查询,那么应该如何进行“增改查删”的其他三个操作呢?
【NOTE】类别不得直接修改
在第三章中曾提到,索引Index类型是无法用index_obj[0] = item来修改的,而categories被存储在Index中,因此pandas在cat属性上定义了若干方法来达到相同的目的。
add_categories:增加类别
s = s.cat.add_categories('Graduate') # 增加一个毕业生类别
s.cat.categories
Index(['Freshman', 'Junior', 'Senior', 'Sophomore', 'Graduate'], dtype='object')
remove_categories:删除类别。同时所有原来序列中的该类会被设置为缺失。
s = s.cat.remove_categories('Freshman')
s.cat.categories
Out[13]: Index(['Junior', 'Senior', 'Sophomore', 'Graduate'], dtype='object')
s.head()
Out[14]:
0 NaN
1 NaN
2 Senior
3 Sophomore
4 Sophomore
Name: Grade, dtype: category
Categories (4, object): ['Junior', 'Senior', 'Sophomore', 'Graduate']
set_categories:直接设置序列的新类别,原来的类别中如果存在元素不属于新类别,那么会被设置为缺失。相当于索引重设。
s = s.cat.set_categories(['Sophomore','PhD']) # 新类别为大二学生和博士
s.cat.categories
Out[16]: Index(['Sophomore', 'PhD'], dtype='object')
s.head()
Out[17]:
0 NaN
1 NaN
2 NaN
3 Sophomore
4 Sophomore
Name: Grade, dtype: category
Categories (2, object): ['Sophomore', 'PhD']
remove_unused_categories:删除未出现在序列中的类别
s = s.cat.remove_unused_categories() # 移除了未出现的博士生类别
s.cat.categories
Index(['Sophomore'], dtype='object')
rename_categories:修改序列的类别。注意,这个方法会对原序列的对应值也进行相应修改。例如,现在把Sophomore改成中文的本科二年级学生:
s = s.cat.rename_categories({'Sophomore':'本科二年级学生'})
s.head()
0 NaN
1 NaN
2 NaN
3 本科二年级学生
4 本科二年级学生
Name: Grade, dtype: category
Categories (1, object): ['本科二年级学生']
9.2 有序分类
9.2.1 序的建立
有序类别和无序类别可以通过as_unordered和reorder_categories互相转化。reorder_categories传入的参数必须是由当前序列的无序类别构成的列表,不能够新增或减少原先的类别,且必须指定参数ordered=True,否则方法无效。例如,对年级高低进行相对大小的类别划分,然后再恢复无序状态:
s = df.Grade.astype('category')
s = s.cat.reorder_categories(['Freshman', 'Sophomore',
'Junior', 'Senior'],ordered=True)
s.head()
Out[24]:
0 Freshman
1 Freshman
2 Senior
3 Sophomore
4 Sophomore
Name: Grade, dtype: category
Categories (4, object): ['Freshman' < 'Sophomore' < 'Junior' < 'Senior']
s.cat.as_unordered().head()
Out[25]:
0 Freshman
1 Freshman
2 Senior
3 Sophomore
4 Sophomore
Name: Grade, dtype: category
Categories (4, object): ['Freshman', 'Sophomore', 'Junior', 'Senior']
如果不想指定
ordered=True参数,那么可以先用s.cat.as_ordered()转化为有序类别,再利用reorder_categories进行具体的相对大小调整。
9.2.2 排序和比较
在第二章中,曾提到了字符串和数值类型序列的排序。前者按照字母顺序排序,后者按照数值大小排序。
分类变量排序,只需把列的类型修改为category后,再赋予相应的大小关系,就能正常地使用sort_index和sort_values。例如,对年级进行排序:
df.Grade = df.Grade.astype('category')
df.Grade = df.Grade.cat.reorder_categories(['Freshman', 'Sophomore', 'Junior', 'Senior'],ordered=True)
df.sort_values('Grade').head() # 值排序
Out[28]:
Grade Name Gender Height Weight
0 Freshman Gaopeng Yang Female 158.9 46.0
105 Freshman Qiang Shi Female 164.5 52.0
96 Freshman Changmei Feng Female 163.8 56.0
88 Freshman Xiaopeng Han Female 164.1 53.0
81 Freshman Yanli Zhang Female 165.1 52.0
df.set_index('Grade').sort_index().head() # 索引排序
Out[29]:
Name Gender Height Weight
Grade
Freshman Gaopeng Yang Female 158.9 46.0
Freshman Qiang Shi Female 164.5 52.0
Freshman Changmei Feng Female 163.8 56.0
Freshman Xiaopeng Han Female 164.1 53.0
Freshman Yanli Zhang Female 165.1 52.0
由于序的建立,因此就可以进行比较操作,方便后续索引操作。分类变量的比较操作分为两类:
==或!=关系的比较,比较的对象可以是标量或者同长度的Series(或list)。(无序时也可以比较)>,>=,<,<=四类大小关系的比较,比较的对象和第一种类似,但是所有参与比较的元素必须属于原序列的categories,同时要和原序列具有相同的索引。
res1 = df.Grade == 'Sophomore'
res1.head()
Out[31]:
0 False
1 False
2 False
3 True
4 True
Name: Grade, dtype: bool
res2 = df.Grade == ['PhD']*df.shape[0]
res2.head()
Out[33]:
0 False
1 False
2 False
3 False
4 False
Name: Grade, dtype: bool
res3 = df.Grade <= 'Sophomore'
res3.head()
Out[35]:
0 True
1 True
2 False
3 True
4 True
Name: Grade, dtype: bool
# sample(frac=1)表示将序列随机打乱。打乱之后索引也是乱序的,直接比较会出错,必须重置索引。
res4 = df.Grade <= df.Grade.sample(frac=1).reset_index(drop=True)
res4.head()
Out[37]:
0 True
1 True
2 False
3 True
4 True
Name: Grade, dtype: bool
9.3 区间类别
9.3.1 利用cut和qcut进行区间构造
区间是一种特殊的类别,在实际数据分析中,区间序列往往是通过cut和qcut方法进行构造的,这两个函数能够把原序列的数值特征进行装箱,即用区间位置来代替原来的具体数值。
cut函数常用参数有:
bins:最重要的参数。- 如果传入整数
n,则表示把整个传入数组按照最大和最小值等间距地分为n段。默认right=True,即区间是左开右闭,需要在调整时把最小值包含进去。(在pandas中的解决方案是在值最小的区间左端点再减去0.001*(max-min)。) - 也可以传入列表,表示按指定区间分割点分割。
- 如果传入整数
如果对序列
[1,2]划分为2个箱子时,第一个箱子的范围(0.999,1.5],第二个箱子的范围是(1.5,2]。
如果需要指定区间为左闭右开,需要把right参数设置为False,相应的区间调整方法是在值最大的区间右端点再加上0.001*(max-min)。
s = pd.Series([1,2])
# bin传入整数
pd.cut(s, bins=2)
Out[39]:
0 (0.999, 1.5]
1 (1.5, 2.0]
dtype: category
Categories (2, interval[float64]): [(0.999, 1.5] < (1.5, 2.0]]
pd.cut(s, bins=2, right=False)
Out[40]:
0 [1.0, 1.5)
1 [1.5, 2.001)
dtype: category
Categories (2, interval[float64]): [[1.0, 1.5) < [1.5, 2.001)]
# bin传入分割点列表(使用`np.infty`可以表示无穷大):
pd.cut(s, bins=[-np.infty, 1.2, 1.8, 2.2, np.infty])
Out[41]:
0 (-inf, 1.2]
1 (1.8, 2.2]
dtype: category
Categories (4, interval[float64]): [(-inf, 1.2] < (1.2, 1.8] < (1.8, 2.2] < (2.2, inf]]
labels:区间的名字retbins:是否返回分割点(默认不返回)
默认
retbins=Flase时,返回每个元素所属区间的列表
retbins=True时,返回的是元组,两个元素分别是元素所属区间和分割点。所属区间可再次用索引取值
s = df.Weight
res = pd.cut(s, bins=3, labels=['small', 'mid','big'],retbins=True)
res[0][:2]
Out[44]:
0 small
1 big
dtype: category
Categories (2, object): ['small' < 'big']
res[1] # 该元素为返回的分割点
Out[45]: array([0.999, 1.5 , 2. ])
qcut函数。其用法cut几乎没有差别,只是把bins参数变成q参数(quantile)。q为整数n时,指按照n等分位数把数据分箱q为浮点列表时,表示相应的分位数分割点。
s = df.Weight
pd.qcut(s, q=3).head()
Out[47]:
0 (33.999, 48.0]
1 (55.0, 89.0]
2 (55.0, 89.0]
3 (33.999, 48.0]
4 (55.0, 89.0]
Name: Weight, dtype: category
Categories (3, interval[float64]): [(33.999, 48.0] < (48.0, 55.0] < (55.0, 89.0]]
pd.qcut(s, q=[0,0.2,0.8,1]).head()
Out[48]:
0 (44.0, 69.4]
1 (69.4, 89.0]
2 (69.4, 89.0]
3 (33.999, 44.0]
4 (69.4, 89.0]
Name: Weight, dtype: category
Categories (3, interval[float64]): [(33.999, 44.0] < (44.0, 69.4] < (69.4, 89.0]]
9.3.2 一般区间的构造
pandas的单个区间用Interval表示,对于某一个具体的区间而言,其具备三个要素,即左端点、右端点和端点的开闭状态。
- 开闭状态:包含四种,即
right(左开右闭), left(左闭右开), both(两边都闭), neither(两边都开)。
my_interval = pd.Interval(0, 1, 'right')
my_interval
Out[50]: Interval(0, 1, closed='right')
- 区间属性:包含
left,mid,right,length,closed,,分别表示左中右端点、长度和开闭状态。- 使用
in可以判断元素是否属于区间 - 用
overlaps可以判断两个区间是否有交集:
- 使用
0.5 in my_interval
True
my_interval_2 = pd.Interval(0.5, 1.5, 'left')
my_interval.overlaps(my_interval_2)
True
pd.IntervalIndex对象有四类方法生成,分别是from_breaks, from_arrays, from_tuples, interval_range,它们分别应用于不同的情况:
from_breaks:类似于cut或qcut函数,只不过后两个是通过计算得到的分割点,而前者是直接传入自定义的分割点:
pd.IntervalIndex.from_breaks([1,3,6,10], closed='both')
IntervalIndex([[1, 3], [3, 6], [6, 10]],
closed='both',
dtype='interval[int64]')
from_arrays:分别传入左端点和右端点的列表,适用于有交集并且知道起点和终点的情况:
pd.IntervalIndex.from_arrays(left = [1,3,6,10], right = [5,4,9,11], closed = 'neither')
IntervalIndex([(1, 5), (3, 4), (6, 9), (10, 11)],
closed='neither',
dtype='interval[int64]')
from_tuples:传入起点和终点元组构成的列表:
pd.IntervalIndex.from_tuples([(1,5),(3,4),(6,9),(10,11)], closed='neither')
IntervalIndex([(1, 5), (3, 4), (6, 9), (10, 11)],
closed='neither',
dtype='interval[int64]')
interval_range:生成等差区间。其参数有四个:start, end, periods, freq。分别表示等差区间的起点、终点、区间个数和区间长度。其中三个量确定的情况下,剩下一个量就确定了,从而就能构造出相应的区间:
pd.interval_range(start=1,end=5,periods=8) # 启起点终点和区间个数
Out[57]:
IntervalIndex([(1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0], (3.0, 3.5], (3.5, 4.0], (4.0, 4.5], (4.5, 5.0]],
closed='right',
dtype='interval[float64]')
pd.interval_range(end=5,periods=8,freq=0.5) # 启起点终点和区间长度
Out[58]:
IntervalIndex([(1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0], (3.0, 3.5], (3.5, 4.0], (4.0, 4.5], (4.5, 5.0]],
closed='right',
dtype='interval[float64]')
【练一练】
无论是interval_range还是下一章时间序列中的date_range都是给定了等差序列中四要素中的三个,从而确定整个序列。请回顾等差数列中的首项、末项、项数和公差的联系,写出interval_range中四个参数之间的恒等关系。
除此之外,如果直接使用pd.IntervalIndex([...], closed=...),把Interval类型的列表组成传入其中转为区间索引,那么所有的区间会被强制转为指定的closed类型,因为pd.IntervalIndex只允许存放同一种开闭区间的Interval对象。
my_interval
Out[59]: Interval(0, 1, closed='right')
my_interval_2
Out[60]: Interval(0.5, 1.5, closed='left')
pd.IntervalIndex([my_interval, my_interval_2], closed='left')
Out[61]:
IntervalIndex([[0.0, 1.0), [0.5, 1.5)],
closed='left',
dtype='interval[float64]')
9.3.3 区间的属性与方法
IntervalIndex上也定义了一些有用的属性和方法。同时,如果想要具体利用cut或者qcut的结果进行分析,那么需要先将其转为该种索引类型:
s=df.Weight
id_interval = pd.IntervalIndex(pd.cut(s, 3)) # 返回的是每个元素所属区间,用具体数值(x,y]表示
id_interval[:3]
IntervalIndex([(33.945, 52.333], (52.333, 70.667], (70.667, 89.0]],
closed='right',
name='Weight',
dtype='interval[float64]')
- 与单个
Interval类型相似,IntervalIndex有若干常用属性:left, right, mid, length,分别表示左右端点、两 点均值和区间长度。
id_demo = id_interval[:5] # 选出前5个展示
id_demo
Out[64]:
IntervalIndex([(33.945, 52.333], (52.333, 70.667], (70.667, 89.0], (33.945, 52.333], (70.667, 89.0]],
closed='right',
name='Weight',
dtype='interval[float64]')
id_demo.left # 获取这五个区间的左端点
Out[65]: Float64Index([33.945, 52.333, 70.667, 33.945, 70.667], dtype='float64')
id_demo.right # 获取这五个区间的右端点
Out[66]: Float64Index([52.333, 70.667, 89.0, 52.333, 89.0], dtype='float64')
id_demo.mid
Out[67]: Float64Index([43.138999999999996, 61.5, 79.8335, 43.138999999999996, 79.8335], dtype='float64')
id_demo.length
Out[68]:
Float64Index([18.387999999999998, 18.334000000000003, 18.333,
18.387999999999998, 18.333],
dtype='float64')
IntervalIndex还有两个常用方法:contains:逐个判断每个区间是否包含某元素overlaps:是否和一个pd.Interval对象有交集。
id_demo.contains(50)
Out[69]: array([ True, False, False, True, False])
id_demo.overlaps(pd.Interval(40,60))
Out[70]: array([ True, True, False, True, False])
9.4 练习
Ex1: 统计未出现的类别
在第五章中介绍了crosstab函数,在默认参数下它能够对两个列的组合出现的频数进行统计汇总:
df = pd.DataFrame({'A':['a','b','c','a'], 'B':['cat','cat','dog','cat']})
pd.crosstab(df.A, df.B)
Out[72]:
B cat dog
A
a 2 0
b 1 0
c 0 1
但事实上有些列存储的是分类变量,列中并不一定包含所有的类别,此时如果想要对这些未出现的类别在crosstab结果中也进行汇总,则可以指定dropna参数为False:
df.B = df.B.astype('category').cat.add_categories('sheep')
pd.crosstab(df.A, df.B, dropna=False)
Out[74]:
B cat dog sheep
A
a 2 0 0
b 1 0 0
c 0 1 0
请实现一个带有dropna参数的my_crosstab函数来完成上面的功能。
Ex2: 钻石数据集
现有一份关于钻石的数据集,其中carat, cut, clarity, price分别表示克拉重量、切割质量、纯净度和价格,样例如下:
df = pd.read_csv('../data/diamonds.csv')
df.head(3)
Out[76]:
carat cut clarity price
0 0.23 Ideal SI2 326
1 0.21 Premium SI1 326
2 0.23 Good VS1 327
- 分别对
df.cut在object类型和category类型下使用nunique函数,并比较它们的性能。 - 钻石的切割质量可以分为五个等级,由次到好分别是
Fair, Good, Very Good, Premium, Ideal,纯净度有八个等级,由次到好分别是I1, SI2, SI1, VS2, VS1, VVS2, VVS1, IF,请对切割质量按照由好到次的顺序排序,相同切割质量的钻石,按照纯净度进行由次到好的排序。 - 分别采用两种不同的方法,把
cut, clarity这两列按照由好到次的顺序,映射到从0到n-1的整数,其中n表示类别的个数。 - 对每克拉的价格分别按照分位数(q=[0.2, 0.4, 0.6, 0.8])与[1000, 3500, 5500, 18000]割点进行分箱得到五个类别
Very Low, Low, Mid, High, Very High,并把按这两种分箱方法得到的category序列依次添加到原表中。 - 第4问中按照整数分箱得到的序列中,是否出现了所有的类别?如果存在没有出现的类别请把该类别删除。
- 对第4问中按照分位数分箱得到的序列,求每个样本对应所在区间的左右端点值和长度。
先看看数据结构:
df.info()
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 carat 53940 non-null float64
1 cut 53940 non-null object
2 clarity 53940 non-null object
3 price 53940 non-null int64
dtypes: float64(1), int64(1), object(2)
- 比较两种操作的性能
%time df.cut.unique()
Wall time: 5.98 ms
array(['Ideal', 'Premium', 'Good', 'Very Good', 'Fair'], dtype=object)
%time df.cut.astype('category').unique()
Wall time: 8.01 ms # 转换类型加统计类别,一共8ms
['Ideal', 'Premium', 'Good', 'Very Good', 'Fair']
Categories (5, object): ['Ideal', 'Premium', 'Good', 'Very Good', 'Fair']
df.cut=df.cut.astype('category')
%time df.cut.unique() # 类别属性统计,2ms
Wall time: 2 ms
['Ideal', 'Premium', 'Good', 'Very Good', 'Fair']
Categories (5, object): ['Ideal', 'Premium', 'Good', 'Very Good', 'Fair']
- 对切割质量按照由好到次的顺序排序,相同切割质量的钻石,按照纯净度进行由次到好的排序。
ls_cut=['Fair', 'Good', 'Very Good', 'Premium', 'Ideal']
ls_clarity=['I1','SI2', 'SI1', 'VS2', 'VS1', 'VVS2', 'VVS1', 'IF']
df.cut=df.cut.astype('category').cat.reorder_categories(ls_cut,ordered=True) # 转换后还是得进行替换
df.clarity=df.clarity.astype('category').cat.reorder_categories(ls_clarity,ordered=True)
df.sort_values(['cut','clarity'],ascending=[False,True]).head(3)
carat cut clarity price
315 0.96 Ideal I1 2801
535 0.96 Ideal I1 2826
551 0.97 Ideal I1 2830
- 分别采用两种不同的方法,把 cut, clarity 这两列按照 由好到次 的顺序,映射到从0到n-1的整数,其中n表示类别的个数。
# 第一种是将类别重命名为整数
dict1=dict(zip(ls_cut,[x for x in range (4,-1,-1)]))
dict2=dict(zip(ls_clarity,[x for x in range (7,-1,-1)]))
df.cut=df.cut.cat.rename_categories(dict1)
df.clarity=df.clarity.cat.rename_categories(dict2)
df.head(3)
carat cut clarity price
0 0.23 0 6 326
1 0.21 1 5 326
2 0.23 3 3 327
# 第二种应该是报错object属性,然后直接进行替换
df = pd.read_csv('data/diamonds.csv')
for i,j in enumerate(ls_cut[::-1]):
df.loc[df.cut==j,'cut']=i
for k,l in enumerate(ls_clarity[::-1]):
df.loc[df.clarity==l,'clarity']=k
df.head(3)
carat cut clarity price
0 0.23 0 6 326
1 0.21 1 5 326
2 0.23 3 3 327
- 对每克拉的价格分别按照分位数(q=[0.2, 0.4, 0.6, 0.8])与[1000, 3500, 5500, 18000]割点进行分箱得到五个类别
Very Low, Low, Mid, High, Very High,并把按这两种分箱方法得到的category序列依次添加到原表中。
# retbins=True返回的是元组,第一个才是要的序列,第二个元素是分割点
avg=df.price/df.carat
df['price_quantile']=pd.qcut(avg, q=[0,0.2,0.4,0.6,0.8,1],
labels=['Very Low', 'Low', 'Mid', 'High', 'Very High'],retbins=True)[0]
df['price_list']=pd.cut(avg, bins=[-np.infty,1000, 3500, 5500, 18000,np.infty],
labels=['Very Low', 'Low', 'Mid', 'High', 'Very High'],retbins=True)[0]
df.head()
carat cut clarity price price_quantile price_list
0 0.23 0 6 326 Very Low Low
1 0.21 1 5 326 Very Low Low
2 0.23 3 3 327 Very Low Low
3 0.29 1 4 334 Very Low Low
4 0.31 3 6 335 Very Low Low
分割点分别是:
array([ 1051.16 , 2295. , 3073.29, 4031.68, 5456.34, 17828.84])
array([ -inf, 1000., 3500., 5500., 18000., inf])
- 第4问中按照整数分箱得到的序列中,是否出现了所有的类别?如果存在没有出现的类别请把该类别删除。
df['price_list'].cat.categories # 原先设定的类别数
Index(['Very Low', 'Low', 'Mid', 'High', 'Very High'], dtype='object')
df['price_list'].cat.remove_unused_categories().cat.categories # 移除未出现的类别
Index(['Low', 'Mid', 'High'], dtype='object') # 首尾两个类别未出现
avg.sort_values() # 可见首尾区间确实是没有的
31962 1051.162791
15 1078.125000
4 1080.645161
28285 1109.090909
13 1109.677419
...
26998 16764.705882
27457 16928.971963
27226 17077.669903
27530 17083.177570
27635 17828.846154
- 对第4问中按照分位数分箱得到的序列,求每个样本对应所在区间的左右端点值和长度。
# 分割时区间不能有命名,否则字符串传入错误。
id_interval=pd.IntervalIndex(
pd.qcut(avg, q=[0,0.2,0.4,0.6,0.8,1],retbins=True)[0]
)
id_interval.left
id_interval.right
id_interval.length
第十章 时序数据
import numpy as np
import pandas as pd
10.1 时序中的基本对象
时间序列的概念在日常生活中十分常见,但对于一个具体的时序事件而言,可以从多个时间对象的角度来描述。例如2020年9月7日周一早上8点整需要到教室上课,这个课会在当天早上10点结束,其中包含了哪些时间概念?
-
会出现时间戳(Date times)的概念,即’2020-9-7 08:00:00’和’2020-9-7 10:00:00’这两个时间点分别代表了上课和下课的时刻,在
pandas中称为Timestamp。同时,一系列的时间戳可以组成DatetimeIndex,而将它放到Series中后,Series的类型就变为了datetime64[ns],如果有涉及时区则为datetime64[ns, tz],其中tz是timezone的简写。 -
会出现时间差(Time deltas)的概念,即上课需要的时间,两个
Timestamp做差就得到了时间差,pandas中利用Timedelta来表示。类似的,一系列的时间差就组成了TimedeltaIndex, 而将它放到Series中后,Series的类型就变为了timedelta64[ns]。 -
会出现时间段(Time spans)的概念,即在8点到10点这个区间都会持续地在上课,在
pandas利用Period来表示。类似的,一系列的时间段就组成了PeriodIndex, 而将它放到Series中后,Series的类型就变为了Period。 -
会出现日期偏置(Date offsets)的概念,假设你只知道9月的第一个周一早上8点要去上课,但不知道具体的日期,那么就需要一个类型来处理此类需求。再例如,想要知道2020年9月7日后的第30个工作日是哪一天,那么时间差就解决不了你的问题,从而
pandas中的DateOffset就出现了。同时,pandas中没有为一列时间偏置专门设计存储类型,理由也很简单,因为需求比较奇怪,一般来说我们只需要对一批时间特征做一个统一的特殊日期偏置。
通过这个简单的例子,就能够容易地总结出官方文档中的这个表格:
| 概念 | 单元素类型 | 数组类型 | pandas数据类型 |
|---|---|---|---|
| Date times | Timestamp | DatetimeIndex | datetime64[ns] |
| Time deltas | Timedelta | TimedeltaIndex | timedelta64[ns] |
| Time spans | Period | PeriodIndex | period[freq] |
| Date offsets | DateOffset | None | None |
由于时间段对象Period/PeriodIndex的使用频率并不高,因此将不进行讲解,而只涉及时间戳序列、时间差序列和日期偏置的相关内容。
10.2 时间戳
10.2.1 Timestamp的构造与属性
单个时间戳的生成利用pd.Timestamp实现,一般而言的常见日期格式都能被成功地转换:
ts = pd.Timestamp('2020/1/1')
ts
Out[4]: Timestamp('2020-01-01 00:00:00')
ts = pd.Timestamp('2020-1-1 08:10:30')
ts
Out[6]: Timestamp('2020-01-01 08:10:30')
通过year, month, day, hour, min, second可以获取具体的数值:
ts.year
Out[7]: 2020
ts.month
Out[8]: 1
ts.day
Out[9]: 1
ts.hour
Out[10]: 8
ts.minute
Out[11]: 10
ts.second
Out[12]: 30
# 获取当前时间
now=pd.Timestamp.now()
在pandas中,时间戳的最小精度为纳秒ns,由于使用了64位存储,可以表示的时间范围大约可以如下计算:
T
i
m
e
R
a
n
g
e
=
2
64
1
0
9
×
60
×
60
×
24
×
365
≈
585
(
Y
e
a
r
s
)
\rm Time\,Range = \frac{2^{64}}{10^9\times 60\times 60\times 24\times 365} \approx 585 (Years)
TimeRange=109×60×60×24×365264≈585(Years)
通过pd.Timestamp.max和pd.Timestamp.min可以获取时间戳表示的范围,可以看到确实表示的区间年数大小正如上述计算结果:
pd.Timestamp.max
Out[13]: Timestamp('2262-04-11 23:47:16.854775807')
pd.Timestamp.min
Out[14]: Timestamp('1677-09-21 00:12:43.145225')
pd.Timestamp.max.year - pd.Timestamp.min.year
Out[15]: 585
10.2.2 Datetime序列的生成
pandas.to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, format=None,
exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=True)
pandas.to_datetime将arg转换为日期时间。
arg:可以是argint、float、str、datetime、list、tuple、一维数组、Series、DataFrame/dict-like等要转换为日期时间的对象。如果提供了 DataFrame,则该方法至少需要以下列:“年”、“月”、“日”。errors:
- ‘raise’:默认值,无效解析将引发异常
- ‘raise’:无效解析将返回输入
- ‘coerce’:无效解析将被设置为NaTdayfirst:如果 arg 是 str 或类似列表时使用,表示日期解析顺序,默认为 False。如果为 True,则首先解析日期,例如“10/11/12”被解析为 2012-11-10。如果无法根据给定的 dayfirst 选项解析分隔日期字符串,会显示警告。yearfirst:如果 arg 是 str 或类似列表时使用,表示日期解析顺序,默认为 False。如果为 True,则首先解析年份,例如“10/11/12”被解析为2010-11-12。无法正确解析时会显示警告。(如果 dayfirst 和 yearfirst 都为 True,则 yearfirst 优先(与 dateutil 相同)。)utcbool:默认None,控制时区相关的解析、本地化和转换。请参阅:pandas 有关时区转换和本地化的一般文档format:str格式,默认None。时间戳的格式不满足转换时,可以强制使用format进行匹配。unitstr:默认“ns”。它是arg (D,s,ms,us,ns) 的表示单位,可以是整数或浮点数。这将基于原点。例如,使用 unit=‘ms’ 和 origin=‘unix’ (默认值),这将计算到 unix 开始的毫秒数。
to_datetime能够把一列时间戳格式的对象转换成为datetime64[ns]类型的时间序列:
pd.to_datetime(['2020-1-1', '2020-1-3', '2020-1-6'])
DatetimeIndex(['2020-01-01', '2020-01-03', '2020-01-06'], dtype='datetime64[ns]', freq=None)
在极少数情况,时间戳的格式不满足转换时,可以强制使用format进行匹配:
temp = pd.to_datetime(['2020\\1\\1','2020\\1\\3'],format='%Y\\%m\\%d')
temp
DatetimeIndex(['2020-01-01', '2020-01-03'], dtype='datetime64[ns]', freq=None)
注意上面由于传入的是列表,而非pandas内部的Series,因此返回的是DatetimeIndex,如果想要转为datetime64[ns]的序列,需要显式用Series转化:
pd.Series(temp).head()
0 2020-01-01
1 2020-01-03
dtype: datetime64[ns]
下面的序列本身就是Series,所以不需要再转化。
df = pd.read_csv('../data/learn_pandas.csv')
s = pd.to_datetime(df.Test_Date)
s.head()
0 2019-10-05
1 2019-09-04
2 2019-09-12
3 2020-01-03
4 2019-11-06
Name: Test_Date, dtype: datetime64[ns]
- 把表的多列时间属性拼接转为时间序列的
to_datetime,此时的列名必须和以下给定的时间关键词列名一致:
df_date_cols = pd.DataFrame({'year': [2020, 2020],
'month': [1, 1],
'day': [1, 2],
'hour': [10, 20],
'minute': [30, 50],
'second': [20, 40]})
pd.to_datetime(df_date_cols)
0 2020-01-01 10:30:20
1 2020-01-02 20:50:40
dtype: datetime64[ns]
date_range是一种生成连续间隔时间的一种方法,其重要的参数为start, end, freq, periods,它们分别表示开始时间,结束时间,时间间隔,时间戳个数。其中,四个中的三个参数决定了,那么剩下的一个就随之确定了。这里要注意,开始或结束日期如果作为端点则它会被包含:
pd.date_range('2020-1-1','2020-1-21', freq='10D') # 包含
Out[25]: DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21'], dtype='datetime64[ns]', freq='10D')
pd.date_range('2020-1-1','2020-2-28', freq='10D')
Out[26]:
DatetimeIndex(['2020-01-01', '2020-01-11', '2020-01-21', '2020-01-31',
'2020-02-10', '2020-02-20'],
dtype='datetime64[ns]', freq='10D')
pd.date_range('2020-1-1',
'2020-2-28', periods=6) # 由于结束日期无法取到,freq不为10天
Out[27]:
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-12 14:24:00',
'2020-01-24 04:48:00', '2020-02-04 19:12:00',
'2020-02-16 09:36:00', '2020-02-28 00:00:00'],
dtype='datetime64[ns]', freq=None)
这里的freq参数与DateOffset对象紧密相关,将在第四节介绍其具体的用法。
【练一练】
Timestamp上定义了一个value属性,其返回的整数值代表了从1970年1月1日零点到给定时间戳相差的纳秒数,请利用这个属性构造一个随机生成给定日期区间内日期序列的函数。
ls=['2020-01-01','2020-02-20']
def dates(ls,n):
min=pd.Timestamp(ls[0]).value/10**9
max=pd.Timestamp(ls[1]).value/10**9
times=np.random.randint(min,max+1,n)
return pd.to_datetime(times,unit='s')
dates(ls,10)
DatetimeIndex(['2020-02-16 09:25:30', '2020-01-29 07:00:04',
'2020-01-21 12:26:02', '2020-02-08 20:34:08',
'2020-02-15 00:18:33', '2020-02-11 02:18:07',
'2020-01-12 21:48:59', '2020-01-12 00:39:24',
'2020-02-14 20:55:20', '2020-01-26 15:44:13'],
dtype='datetime64[ns]', freq=None)
asfreq:改变序列采样频率的方法,能够根据给定的freq对序列进行类似于reindex的操作:
s = pd.Series(np.random.rand(5),
index=pd.to_datetime([
'2020-1-%d'%i for i in range(1,10,2)]))
s.head()
Out[29]:
2020-01-01 0.836578
2020-01-03 0.678419
2020-01-05 0.711897
2020-01-07 0.487429
2020-01-09 0.604705
dtype: float64
s.asfreq('D').head()
Out[30]:
2020-01-01 0.836578
2020-01-02 NaN
2020-01-03 0.678419
2020-01-04 NaN
2020-01-05 0.711897
Freq: D, dtype: float64
s.asfreq('12H').head()
Out[31]:
2020-01-01 00:00:00 0.836578
2020-01-01 12:00:00 NaN
2020-01-02 00:00:00 NaN
2020-01-02 12:00:00 NaN
2020-01-03 00:00:00 0.678419
Freq: 12H, dtype: float64
【NOTE】datetime64[ns] 序列的极值与均值
前面提到了datetime64[ns]本质上可以理解为一个整数,即从1970年1月1日零点到给定时间戳相差的纳秒数。所以对于一个datetime64[ns]序列,可以使用max, min, mean,来取得最大时间戳、最小时间戳和“平均”时间戳。
10.2.3 dt对象
如同category, string的序列上定义了cat, str来完成分类数据和文本数据的操作,在时序类型的序列上定义了dt对象来完成许多时间序列的相关操作。这里对于datetime64[ns]类型而言,可以大致分为三类操作:取出时间相关的属性、判断时间戳是否满足条件、取整操作。
- 第一类操作的常用属性包括:
date, time, year, month, day, hour, minute, second, microsecond, nanosecond, dayofweek, dayofyear, weekofyear, daysinmonth, quarter,其中daysinmonth, quarter分别表示该月一共有几天和季度。
s = pd.Series(pd.date_range('2020-1-1','2020-1-3', freq='D'))
s.dt.date
Out[33]:
0 2020-01-01
1 2020-01-02
2 2020-01-03
dtype: object
s.dt.time
Out[34]:
0 00:00:00
1 00:00:00
2 00:00:00
dtype: object
s.dt.day
Out[35]:
0 1
1 2
2 3
dtype: int64
s.dt.daysinmonth
Out[36]:
0 31
1 31
2 31
dtype: int64
在这些属性中,经常使用的是dayofweek,它返回了周中的星期情况,周一为0、周二为1,以此类推。此外,还可以通过month_name, day_name返回英文的月名和星期名,注意它们是方法而不是属性:
s.dt.dayofweek
Out[37]:
0 2
1 3
2 4
dtype: int64
s.dt.month_name()
Out[38]:
0 January
1 January
2 January
dtype: object
s.dt.day_name()
Out[39]:
0 Wednesday
1 Thursday
2 Friday
dtype: object
- 第二类判断操作主要用于测试是否为月/季/年的第一天或者最后一天:
s.dt.is_year_start # 还可选 is_quarter/month_start
Out[40]:
0 True
1 False
2 False
dtype: bool
s.dt.is_year_end # 还可选 is_quarter/month_end
Out[41]:
0 False
1 False
2 False
dtype: bool
- 第三类的取整操作包含
round, ceil, floor,它们的公共参数为freq,常用的包括H, min, S(小时、分钟、秒),所有可选的freq可参考此处。
s = pd.Series(pd.date_range('2020-1-1 20:35:00',
'2020-1-1 22:35:00',
freq='45min'))
s
Out[43]:
0 2020-01-01 20:35:00
1 2020-01-01 21:20:00
2 2020-01-01 22:05:00
dtype: datetime64[ns]
s.dt.round('1H')
Out[44]:
0 2020-01-01 21:00:00
1 2020-01-01 21:00:00
2 2020-01-01 22:00:00
dtype: datetime64[ns]
s.dt.ceil('1H')
Out[45]:
0 2020-01-01 21:00:00
1 2020-01-01 22:00:00
2 2020-01-01 23:00:00
dtype: datetime64[ns]
s.dt.floor('1H')
Out[46]:
0 2020-01-01 20:00:00
1 2020-01-01 21:00:00
2 2020-01-01 22:00:00
dtype: datetime64[ns]
10.2.4 时间戳的切片与索引
一般而言,时间戳序列作为索引使用。如果想要选出某个子时间戳序列,有两种方法:
- 利用
dt对象和布尔条件联合使用 - 利用切片,后者常用于连续时间戳。
s = pd.Series(np.random.randint(2,size=366), index=pd.date_range('2020-01-01','2020-12-31'))
idx = pd.Series(s.index).dt
s.head()
2020-01-01 0
2020-01-02 1
2020-01-03 1
2020-01-04 0
2020-01-05 0
Freq: D, dtype: int32
Example1:每月的第一天或者最后一天
s[(idx.is_month_start|idx.is_month_end).values].head() # 必须要写.values
Out[50]:
2020-01-01 1
2020-01-31 0
2020-02-01 1
2020-02-29 1
2020-03-01 0
dtype: int32
Example2:双休日
s[idx.dayofweek.isin([5,6]).values].head()
Out[51]:
2020-01-04 1
2020-01-05 0
2020-01-11 0
2020-01-12 1
2020-01-18 1
dtype: int32
Example3:取出单日值
s['2020-01-01']
Out[52]: 1
s['20200101'] # 自动转换标准格式
Out[53]: 1
Example4:取出七月
s['2020-07'].head()
Out[54]:
2020-07-01 0
2020-07-02 1
2020-07-03 0
2020-07-04 0
2020-07-05 0
Freq: D, dtype: int32
Example5:取出5月初至7月15日
s['2020-05':'2020-7-15'].head()
Out[55]:
2020-05-01 0
2020-05-02 1
2020-05-03 0
2020-05-04 1
2020-05-05 1
Freq: D, dtype: int32
s['2020-05':'2020-7-15'].tail()
Out[56]:
2020-07-11 0
2020-07-12 0
2020-07-13 1
2020-07-14 0
2020-07-15 1
Freq: D, dtype: int32
10.3 时间差
10.3.1 Timedelta的生成
pandas.Timedelta(value=<object object>, unit=None, **kwargs)
unit:字符串格式,默认 ‘ns’。如果输入是整数,则表示输入的单位。
可能的值有:
- ‘W’, ‘D’, ‘T’, ‘S’, ‘L’, ‘U’, or ‘N’
- ‘days’ or ‘day’
- ‘hours’, ‘hour’, ‘hr’, or ‘h’
- ‘minutes’, ‘minute’, ‘min’, or ‘m’
- ‘seconds’, ‘second’, or ‘sec’
- 毫秒‘milliseconds’, ‘millisecond’, ‘millis’, or ‘milli’
- 微秒‘microseconds’, ‘microsecond’, ‘micros’, or ‘micro’
- 纳秒 ‘nanoseconds’, ‘nanosecond’, ‘nanos’, ‘nano’, or ‘ns’.
- 时间差可以理解为两个时间戳的差,可以通过pd.Timedelta来构造:
pd.Timestamp('20200102 08:00:00')-pd.Timestamp('20200101 07:35:00')
Out[57]: Timedelta('1 days 00:25:00')
pd.Timedelta(days=1, minutes=25) # 需要注意加s
Out[58]: Timedelta('1 days 00:25:00')
pd.Timedelta('1 days 25 minutes') # 字符串生成
Out[59]: Timedelta('1 days 00:25:00')
pd.Timedelta(1, "d")
Out[58]: Timedelta('1 days 00:00:00')
- 生成时间差序列的主要方式是 pd.to_timedelta ,其类型为 timedelta64[ns] :
s = pd.to_timedelta(df.Time_Record)
s.head()
Out[61]:
0 0 days 00:04:34
1 0 days 00:04:20
2 0 days 00:05:22
3 0 days 00:04:08
4 0 days 00:05:22
Name: Time_Record, dtype: timedelta64[ns]
- 与
date_range一样,时间差序列也可以用timedelta_range来生成,它们两者具有一致的参数:
pd.timedelta_range('0s', '1000s', freq='6min')
Out[62]: TimedeltaIndex(['0 days 00:00:00', '0 days 00:06:00', '0 days 00:12:00'], dtype='timedelta64[ns]', freq='6T')
pd.timedelta_range('0s', '1000s', periods=3)
Out[63]: TimedeltaIndex(['0 days 00:00:00', '0 days 00:08:20', '0 days 00:16:40'], dtype='timedelta64[ns]', freq=None)
- 对于
Timedelta序列,同样也定义了dt对象,上面主要定义了的属性包括days, seconds, mircroseconds(毫秒), nanoseconds(纳秒),它们分别返回了对应的时间差特征。需要注意的是,这里的seconds不是指单纯的秒,而是对天数取余后剩余的秒数:
s.dt.seconds.head()
Out[64]:
0 274
1 260
2 322
3 248
4 322
Name: Time_Record, dtype: int64
如果不想对天数取余而直接对应秒数,可以使用total_seconds
s.dt.total_seconds().head()
Out[65]:
0 274.0
1 260.0
2 322.0
3 248.0
4 322.0
Name: Time_Record, dtype: float64
与时间戳序列类似,取整函数也是可以在dt对象上使用的:
pd.to_timedelta(df.Time_Record).dt.round('min').head()
Out[66]:
0 0 days 00:05:00
1 0 days 00:04:00
2 0 days 00:05:00
3 0 days 00:04:00
4 0 days 00:05:00
Name: Time_Record, dtype: timedelta64[ns]
10.2.2 Timedelta的运算
- 单个时间差的常用运算,有三类:与标量的乘法运算、与时间戳的加减法运算、与时间差的加减法与除法运算:
td1 = pd.Timedelta(days=1)
td2 = pd.Timedelta(days=3)
ts = pd.Timestamp('20200101')
td1 * 2
Out[70]: Timedelta('2 days 00:00:00')
td2 - td1
Out[71]: Timedelta('2 days 00:00:00')
ts + td1
Out[72]: Timestamp('2020-01-02 00:00:00')
ts - td1
Out[73]: Timestamp('2019-12-31 00:00:00')
- 时间差的序列的运算,和上面方法相同:
td1 = pd.timedelta_range(start='1 days', periods=5)
td2 = pd.timedelta_range(start='12 hours',
freq='2H',
periods=5)
ts = pd.date_range('20200101', '20200105')
td1,td2,ts
TimedeltaIndex(['1 days', '2 days', '3 days', '4 days', '5 days'], dtype='timedelta64[ns]', freq='D')
TimedeltaIndex(['0 days 12:00:00', '0 days 14:00:00', '0 days 16:00:00',
'0 days 18:00:00', '0 days 20:00:00'], dtype='timedelta64[ns]', freq='2H')
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05'],
dtype='datetime64[ns]', freq='D')
td1 * 5
Out[77]: TimedeltaIndex(['5 days', '10 days', '15 days', '20 days', '25 days'], dtype='timedelta64[ns]', freq='5D')
td1 * pd.Series(list(range(5))) # 逐个相乘
Out[78]:
0 0 days
1 2 days
2 6 days
3 12 days
4 20 days
dtype: timedelta64[ns]
td1 - td2
Out[79]:
TimedeltaIndex(['0 days 12:00:00', '1 days 10:00:00', '2 days 08:00:00',
'3 days 06:00:00', '4 days 04:00:00'],
dtype='timedelta64[ns]', freq=None)
td1 + pd.Timestamp('20200101')
Out[80]:
DatetimeIndex(['2020-01-02', '2020-01-03', '2020-01-04', '2020-01-05',
'2020-01-06'],dtype='datetime64[ns]', freq='D')
td1 + ts # 逐个相加
Out[81]:
DatetimeIndex(['2020-01-02', '2020-01-04', '2020-01-06', '2020-01-08',
'2020-01-10'],
dtype='datetime64[ns]', freq=None)
10.4 日期偏置
10.4.1 Offset对象
日期偏置是一种和日历相关的特殊时间差,例如回到第一节中的两个问题:如何求2020年9月第一个周一的日期,以及如何求2020年9月7日后的第30个工作日是哪一天。
DateOffset 类有10个属性,假设
s=pd.offsets.WeekOfMonth(week=0,weekday=0),则:
s.base:<WeekOfMonth: week=0, weekday=0>,返回 n=1 且所有其他属性一样的副本s.kwds:{‘week’: 0, ‘weekday’: 0}s.wek/s.weekday:顾名思义有14个方法,包括:
- DateOffset.is_month_start、DateOffset.is_month_end、DateOffset.is_quarter_start、DateOffset.is_quarter_end、DateOffset.is_year_start、DateOffset.is_year_end等等。
pandas.tseries.offsets.WeekOfMonth(week,weekday):描述每月的日期,例如“每月第二周的星期二”。
- 有两个参数:
week:整型,表示一个月的第几周。例如 0 是一个月的第 1 周,1 是第 2 周,以此类推。weekday:整型,取值为[0,1,…6],表示周一到周日,默认取值为0(星期一)
pandas.tseries.offsets.BusinessDay(n):相当于
pd.offsets.BDay(n),DateOffset 子类,表示可能的 n 个工作日。
pd.Timestamp('20200831') + pd.offsets.WeekOfMonth(week=0,weekday=0)
Out[82]: Timestamp('2020-09-07 00:00:00')
pd.Timestamp('20200907') + pd.offsets.BDay(30)
Out[83]: Timestamp('2020-10-19 00:00:00')
从上面的例子中可以看到,Offset对象在pd.offsets中被定义。当使用+时获取离其最近的下一个日期,当使用-时获取离其最近的上一个日期:
pd.Timestamp('20200831') - pd.offsets.WeekOfMonth(week=0,weekday=0)
Out[84]: Timestamp('2020-08-03 00:00:00')
pd.Timestamp('20200907') - pd.offsets.BDay(30)
Out[85]: Timestamp('2020-07-27 00:00:00')
pd.Timestamp('20200907') + pd.offsets.MonthEnd()
Out[86]: Timestamp('2020-09-30 00:00:00')
常用的日期偏置如下可以查阅这里的DateOffset 文档描述。在文档罗列的Offset中,需要介绍一个特殊的Offset对象CDay。CDay 或 CustomBusinessDay 类提供了一个参数化的 BusinessDay 类,可用于创建自定义的工作日日历,该日历说明当地假期和当地周末惯例。
其中的holidays, weekmask参数能够分别对自定义的日期和星期进行过滤,前者传入了需要过滤的日期列表,后者传入的是三个字母的星期缩写构成的星期字符串,其作用是只保留字符串中出现的星期:
my_filter = pd.offsets.CDay(n=1,weekmask='Wed Fri',holidays=['20200109'])
dr = pd.date_range('20200108', '20200111')
dr.to_series().dt.dayofweek
Out[89]:
2020-01-08 2
2020-01-09 3
2020-01-10 4
2020-01-11 5
Freq: D, dtype: int64
[i + my_filter for i in dr]
Out[90]:
[Timestamp('2020-01-10 00:00:00'),
Timestamp('2020-01-10 00:00:00'),
Timestamp('2020-01-15 00:00:00'),
Timestamp('2020-01-15 00:00:00')]
上面的例子中,n表示增加一天CDay,dr中的第一天为20200108,但由于下一天20200109被排除了,并且20200110是合法的周五,因此转为20200110,其他后面的日期处理类似。
【CAUTION】不要使用部分
Offset
在当前版本下由于一些bug,不要使用Day级别以下的Offset对象,比如Hour, Second等,请使用对应的Timedelta对象来代替。
10.4.2 偏置字符串
前面提到了关于date_range的freq取值可用Offset对象,同时在pandas中几乎每一个Offset对象绑定了日期偏置字符串(frequencies strings/offset aliases),可以指定Offset对应的字符串来替代使用。下面举一些常见的例子。
Offset aliases:pd.date_range函数中的freq参数,为常见时间序列频率提供了许多字符串别名。 也称为偏移别名Offset aliases。偏移别名列表点此参看(大概27个)。
pd.date_range('20200101','20200331', freq='MS') # 月初
Out[91]: DatetimeIndex(['2020-01-01', '2020-02-01', '2020-03-01'], dtype='datetime64[ns]', freq='MS')
pd.date_range('20200101','20200331', freq='M') # 月末
Out[92]: DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31'], dtype='datetime64[ns]', freq='M')
pd.date_range('20200101','20200110', freq='B') # 工作日
Out[93]:
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-06',
'2020-01-07', '2020-01-08', '2020-01-09', '2020-01-10'],
dtype='datetime64[ns]', freq='B')
pd.date_range('20200101','20200201', freq='W-MON') # 周一
Out[94]: DatetimeIndex(['2020-01-06', '2020-01-13', '2020-01-20', '2020-01-27'], dtype='datetime64[ns]', freq='W-MON')
pd.date_range('20200101','20200201',
freq='WOM-1MON') # 每月第一个周一
Out[95]: DatetimeIndex(['2020-01-06'], dtype='datetime64[ns]', freq='WOM-1MON')
上面的这些字符串,等价于使用如下的 Offset 对象:
pd.date_range('20200101','20200331',
freq=pd.offsets.MonthBegin())
Out[96]: DatetimeIndex(['2020-01-01', '2020-02-01', '2020-03-01'], dtype='datetime64[ns]', freq='MS')
pd.date_range('20200101','20200331',
freq=pd.offsets.MonthEnd())
Out[97]: DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31'], dtype='datetime64[ns]', freq='M')
pd.date_range('20200101','20200110', freq=pd.offsets.BDay())
Out[98]:
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-06',
'2020-01-07', '2020-01-08', '2020-01-09', '2020-01-10'],
dtype='datetime64[ns]', freq='B')
pd.date_range('20200101','20200201',
freq=pd.offsets.CDay(weekmask='Mon'))
Out[99]: DatetimeIndex(['2020-01-06', '2020-01-13', '2020-01-20', '2020-01-27'], dtype='datetime64[ns]', freq='C')
pd.date_range('20200101','20200201',
freq=pd.offsets.WeekOfMonth(week=0,weekday=0))
Out[100]: DatetimeIndex(['2020-01-06'], dtype='datetime64[ns]', freq='WOM-1MON')
【CAUTION】关于时区问题的说明
各类时间对象的开发,除了使用python内置的datetime模块,pandas还利用了dateutil模块,很大一部分是为了处理时区问题。总所周知,我国是没有夏令时调整时间一说的,但有些国家会有这种做法,导致了相对而言一天里可能会有23/24/25个小时,也就是relativedelta,这使得Offset对象和Timedelta对象有了对同一问题处理产生不同结果的现象,其中的规则也较为复杂,官方文档的写法存在部分描述错误,并且难以对描述做出统一修正,因为牵涉到了Offset相关的很多组件。因此,本教程完全不考虑时区处理,如果对时区处理的时间偏置有兴趣了解讨论,可以联系我或者参见这里的讨论。
10.5、时序中的滑窗与分组
10.5.1 滑动窗口
所谓时序的滑窗函数,即把滑动窗口windows用freq关键词代替,下面给出一个具体的应用案例:在股票市场中有一个指标为BOLL指标,它由中轨线、上轨线、下轨线这三根线构成,具体的计算方法分别是N日均值线、N日均值加两倍N日标准差线、N日均值减两倍N日标准差线。利用rolling对象计算N=30的BOLL指标可以如下写出:
import matplotlib.pyplot as plt
idx = pd.date_range('20200101', '20201231', freq='B')
np.random.seed(2020)
data = np.random.randint(-1,2,len(idx)).cumsum() # 随机游动构造模拟序列,cumsum表示累加
s = pd.Series(data,index=idx)
s.head()
Out[106]:
2020-01-01 -1
2020-01-02 -2
2020-01-03 -1
2020-01-06 -1
2020-01-07 -2
Freq: B, dtype: int32
r = s.rolling('30D')# rolling可以指定freq或者offset对象
plt.plot(s) # 蓝色线
Out[108]: [<matplotlib.lines.Line2D at 0x2116d887eb0>]
plt.title('BOLL LINES')
Out[109]: Text(0.5, 1.0, 'BOLL LINES')
plt.plot(r.mean()) #橙色线
Out[110]: [<matplotlib.lines.Line2D at 0x2116d8eeb80>]
plt.plot(r.mean()+r.std()*2) # 绿色线
Out[111]: [<matplotlib.lines.Line2D at 0x2116d87efa0>]
plt.plot(r.mean()-r.std()*2) # 红色线
Out[112]: [<matplotlib.lines.Line2D at 0x2116d90d2e0>]
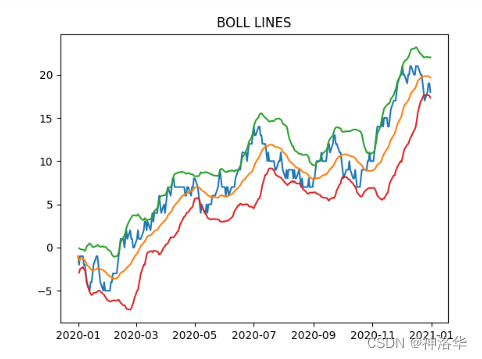
这里需要注意的是,pandas没有实现非固定采样频率的时间序列滑窗,及此时无法通过传入freq字段来得到滑窗结果。例如统计近7个工作日的交易总额。此时可以通过传入多个函数的组合来实现此功能。
首先选出所有工作日,接着用普通滑窗进行7日滑窗加和,最后用reindex()恢复索引,对于双休日使用前一个工作日的结果进行填充。
select_bday=s[~s.index.to_series().dt.dayofweek.isin([5,6])]
bday_sum=select_bday.rolling(7,min_periods=1).sum()
result=bday_sum.reindex().ffill()
result
2020-01-01 -1.0
2020-01-02 -3.0
2020-01-03 -4.0
2020-01-06 -5.0
2020-01-07 -7.0
...
2020-12-25 136.0
2020-12-28 133.0
2020-12-29 131.0
2020-12-30 130.0
2020-12-31 128.0
Freq: B, Length: 262, dtype: float64
shift, diff, pct_change是一组类滑窗函数,它们的公共参数为 periods=n ,默认为1,分别表示取向前第 n 个元素的值、与向前第 n 个元素做差(与 Numpy 中不同,后者表示 n 阶差分)、与向前第 n 个元素相比计算增长率。这里的 n 可以为负,表示反方向的类似操作。
对于shift函数而言,作用在datetime64为索引(不是value)的序列上时,可以指定freq单位进行滑动:
s.shift(freq='50D').head()
Out[113]:
2020-02-20 -1
2020-02-21 -2
2020-02-22 -1
2020-02-25 -1
2020-02-26 -2
dtype: int32
另外,datetime64[ns]的序列进行diff(前后做差)后就能够得到timedelta64[ns]的序列,这能够使用户方便地观察有序时间序列的间隔:
my_series = pd.Series(s.index)
my_series.head()
Out[115]:
0 2020-01-01
1 2020-01-02
2 2020-01-03
3 2020-01-06
4 2020-01-07
dtype: datetime64[ns]
my_series.diff(1).head()
Out[116]:
0 NaT
1 1 days
2 1 days
3 3 days
4 1 days
dtype: timedelta64[ns]
10.5.2 重采样
DataFrame.resample(rule, axis=0, closed=None, label=None, convention=‘start’, kind=None, loffset=None, base=None, on=None, level=None, origin=‘start_day’, offset=None)
常用参数有:
rule:DateOffset, Timedelta or str类型。表示偏移量字符串或对象axis:{0 or ‘index’, 1 or ‘columns’}, default 0。使用哪个轴进行上采样或下采样closed:{‘right’, ‘left’},默认None。表示bin 区间的哪一侧是闭合的。所有offsets的默认值为“left”,但“M”、“A”、“Q”、“BM”、“BA”、“BQ”和“W”均默认为“right”。label:{‘right’, ‘left’}, 默认 None。hich bin edge label to label bucket with,所有offsets的默认值为“left”,但“M”、“A”、“Q”、“BM”、“BA”、“BQ”和“W”均默认为“right”。convention{:‘start’, ‘end’, ‘s’, ‘e’}, default ‘start’。仅针对 PeriodIndex,控制是使用rule的开始还是结尾。on:字符串类型,可选。对于 DataFrame,使用列而不是索引进行重采样。列必须类似于日期时间。level:str 或 int,可选表示多重索引MultiIndex的级别,这个级别的索引必须类似于日期时间。origin参数有5种取值:
‘epoch’:从 1970-01-01开始算起‘start’:原点是时间序列的第一个值‘start_day’:默认值,表示原点是时间序列第一天的午夜。'end':原点是时间序列的最后一个值(1.3.0版本才有)‘end_day’:原点是序列最后一天的午夜(1.3.0版本才有)offset:Timedelta 或 str,默认为 None,表示对时间原点的偏移量,很有用。
closed和计算有关,label和显示有关,closed才有开闭。
label指这个区间值算出来了,索引放区间的左端点还是右端点,closed是指算的时候左端点或右端点是不是包含。
- 重采样对象resample和第四章中分组对象
groupby的用法类似,resample是针对时间序列的分组计算而设计的分组对象。例如,对上面的序列计算每10天的均值:
s.resample('10D').mean().head()
Out[117]:
2020-01-01 -2.000000
2020-01-11 -3.166667
2020-01-21 -3.625000
2020-01-31 -4.000000
2020-02-10 -0.375000
Freq: 10D, dtype: float64
- 可以通过
apply方法自定义处理函数:
s.resample('10D').apply(lambda x:x.max()-x.min()).head() # 极差
Out[118]:
2020-01-01 3
2020-01-11 4
2020-01-21 4
2020-01-31 2
2020-02-10 4
Freq: 10D, dtype: int32
在resample中要特别注意组边界值的处理情况,默认情况下起始值的计算方法是从最小值时间戳对应日期的午夜00:00:00开始增加freq,直到不超过该最小时间戳的最大时间戳,由此对应的时间戳为起始值,然后每次累加freq参数作为分割结点进行分组,区间情况为左闭右开。下面构造一个不均匀的例子:
idx = pd.date_range('20200101 8:26:35', '20200101 9:31:58', freq='77s')
data = np.random.randint(-1,2,len(idx)).cumsum()
s = pd.Series(data,index=idx)
s.head()
Out[122]:
2020-01-01 08:26:35 -1
2020-01-01 08:27:52 -1
2020-01-01 08:29:09 -2
2020-01-01 08:30:26 -3
2020-01-01 08:31:43 -4
Freq: 77S, dtype: int32
下面对应的第一个组起始值为08:24:00,其是从当天0点增加72个freq=7 min得到的,如果再增加一个freq则超出了序列的最小时间戳08:26:35:
s.resample('7min').mean().head()
Out[123]:
2020-01-01 08:24:00 -1.750000 # 起始值,终点值包含最后一个值
2020-01-01 08:31:00 -2.600000
2020-01-01 08:38:00 -2.166667
2020-01-01 08:45:00 0.200000
2020-01-01 08:52:00 2.833333
Freq: 7T, dtype: float64
有时候,用户希望从序列的最小时间戳开始依次增加freq进行分组,此时可以指定origin参数为start:
s.resample('7min', origin='start').mean().head()
Out[124]:
2020-01-01 08:26:35 -2.333333
2020-01-01 08:33:35 -2.400000
2020-01-01 08:40:35 -1.333333
2020-01-01 08:47:35 1.200000
2020-01-01 08:54:35 3.166667
Freq: 7T, dtype: float64
在返回值中,要注意索引一般是取组的第一个时间戳,但M, A, Q, BM, BA, BQ, W这七个是取对应区间的最后一个时间戳。如果想要得到正常索引,用’MS’就行。
s = pd.Series(np.random.randint(2,size=366),
index=pd.date_range('2020-01-01',
'2020-12-31'))
s.resample('M').mean().head()
Out[126]:
2020-01-31 0.451613
2020-02-29 0.448276
2020-03-31 0.516129
2020-04-30 0.566667
2020-05-31 0.451613
Freq: M, dtype: float64
s.resample('MS').mean().head() # 结果一样,但索引是跟正常一样
Out[127]:
2020-01-01 0.451613
2020-02-01 0.448276
2020-03-01 0.516129
2020-04-01 0.566667
2020-05-01 0.451613
Freq: MS, dtype: float64
- 对于 DataFrame 对象,关键字
on可用于指定列而不是索引以进行重采样:
d = {'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50]}
df = pd.DataFrame(d)
df['week_starting'] = pd.date_range('01/01/2018',
periods=8,
freq='W')
df
price volume week_starting
0 10 50 2018-01-07
1 11 60 2018-01-14
2 9 40 2018-01-21
3 13 100 2018-01-28
4 14 50 2018-02-04
5 18 100 2018-02-11
6 17 40 2018-02-18
7 19 50 2018-02-25
df.resample('M', on='week_starting').mean()
price volume
week_starting
2018-01-31 10.75 62.5
2018-02-28 17.00 60.0
- 对于具有 MultiIndex 的 DataFrame,关键字
level可用于指定需要在哪个级别进行重采样。
days = pd.date_range('1/1/2000', periods=4, freq='D')
d2 = {'price': [10, 11, 9, 13, 14, 18, 17, 19],
'volume': [50, 60, 40, 100, 50, 100, 40, 50]}
df2 = pd.DataFrame(
d2,
index=pd.MultiIndex.from_product(
[days, ['morning', 'afternoon']]
)
)
df2
price volume
2000-01-01 morning 10 50
afternoon 11 60
2000-01-02 morning 9 40
afternoon 13 100
2000-01-03 morning 14 50
afternoon 18 100
2000-01-04 morning 17 40
afternoon 19 50
df2.resample('D', level=0).sum()
price volume
2000-01-01 21 110
2000-01-02 22 140
2000-01-03 32 150
2000-01-04 36 90
- 根据固定时间戳调整 bin 的开始:
start, end = '2000-10-01 23:30:00', '2000-10-02 00:30:00'
rng = pd.date_range(start, end, freq='7min')
ts = pd.Series(np.arange(len(rng)) * 3, index=rng)
ts
2000-10-01 23:30:00 0
2000-10-01 23:37:00 3
2000-10-01 23:44:00 6
2000-10-01 23:51:00 9
2000-10-01 23:58:00 12
2000-10-02 00:05:00 15
2000-10-02 00:12:00 18
2000-10-02 00:19:00 21
2000-10-02 00:26:00 24
Freq: 7T, dtype: int64
ts.resample('17min').sum()
2000-10-01 23:14:00 0
2000-10-01 23:31:00 9
2000-10-01 23:48:00 21
2000-10-02 00:05:00 54
2000-10-02 00:22:00 24
Freq: 17T, dtype: int64
ts.resample('17min', origin='epoch').sum()
2000-10-01 23:18:00 0
2000-10-01 23:35:00 18
2000-10-01 23:52:00 27
2000-10-02 00:09:00 39
2000-10-02 00:26:00 24
Freq: 17T, dtype: int64
ts.resample('17min', origin='2000-01-01').sum()
2000-10-01 23:24:00 3
2000-10-01 23:41:00 15
2000-10-01 23:58:00 45
2000-10-02 00:15:00 45
Freq: 17T, dtype: int64
- 如果要使用偏移 Timedelta 调整 bin 的开始,则以下两行是等效的:
ts.resample('17min', origin='start').sum()
ts.resample('17min', offset='23h30min').sum()
2000-10-01 23:30:00 9
2000-10-01 23:47:00 21
2000-10-02 00:04:00 54
2000-10-02 00:21:00 24
Freq: 17T, dtype: int64
10.6 练习
Ex1:太阳辐射数据集
现有一份关于太阳辐射的数据集:
df = pd.read_csv('../data/solar.csv', usecols=['Data','Time','Radiation','Temperature'])
df.head(3)
Out[129]:
Data Time Radiation Temperature
0 9/29/2016 12:00:00 AM 23:55:26 1.21 48
1 9/29/2016 12:00:00 AM 23:50:23 1.21 48
2 9/29/2016 12:00:00 AM 23:45:26 1.23 48
- 将
Datetime, Time合并为一个时间列Datetime,同时把它作为索引后排序。 - 每条记录时间的间隔显然并不一致,请解决如下问题:
- 找出间隔时间的前三个最大值所对应的三组时间戳。
- 是否存在一个大致的范围,使得绝大多数的间隔时间都落在这个区间中?如果存在,请对此范围内的样本间隔秒数画出柱状图,设置
bins=50。
- 求如下指标对应的
Series:- 温度与辐射量的6小时滑动相关系数
- 以三点、九点、十五点、二十一点为分割,该观测所在时间区间的温度均值序列
- 每个观测6小时前的辐射量(一般而言不会恰好取到,此时取最近时间戳对应的辐射量)
import numpy as np
import pandas as pd
- 将
Datetime, Time合并为一个时间列Datetime,同时把它作为索引后排序。
data=pd.to_datetime(df.Data) # 本身是object对象,要先转为时间序列
times=pd.to_timedelta(df.Time)
df.Data=data+times
del df['Time']
df=df.set_index('Data').sort_index() # 如果写的是set_index(df.Data),那么Data作为索引之外,这个列还另外保留
df
Radiation Temperature
Data
2016-09-01 00:00:08 2.58 51
2016-09-01 00:05:10 2.83 51
2016-09-01 00:20:06 2.16 51
2016-09-01 00:25:05 2.21 51
2016-09-01 00:30:09 2.25 51
... ... ...
2016-12-31 23:35:02 1.22 41
2016-12-31 23:40:01 1.21 41
2016-12-31 23:45:04 1.21 42
2016-12-31 23:50:03 1.19 41
2016-12-31 23:55:01 1.21 41
- 每条记录时间的间隔显然并不一致,请解决如下问题:
- 找出间隔时间的前三个最大值所对应的三组时间戳。
# 第一次做错了,不是找三组时间戳
idxmax3=pd.Series(df.index).diff(1).sort_values(ascending=False).index[:3]
df.reset_index().Data[idxmax3,idxmax3-1]
25923 2016-12-08 11:10:42
24522 2016-12-01 00:00:02
7417 2016-10-01 00:00:19
Name: Data, dtype: datetime64[ns]
idxmax3=pd.Series(df.index).diff(1).sort_values(ascending=False).index[:3]
list(zip(df.reset_index().Data[idxmax3],df.reset_index().Data[idxmax3-1]))
[(Timestamp('2016-12-08 11:10:42'), Timestamp('2016-12-05 20:45:53')),
(Timestamp('2016-12-01 00:00:02'), Timestamp('2016-11-29 19:05:02')),
(Timestamp('2016-10-01 00:00:19'), Timestamp('2016-09-29 23:55:26'))]
参考答案:
s = df.index.to_series().reset_index(drop=True).diff().dt.total_seconds()
max_3 = s.nlargest(3).index
df.index[max_3.union(max_3-1)]
Out[215]:
DatetimeIndex(['2016-09-29 23:55:26', '2016-10-01 00:00:19',
'2016-11-29 19:05:02', '2016-12-01 00:00:02',
'2016-12-05 20:45:53', '2016-12-08 11:10:42'],
dtype='datetime64[ns]', name='Datetime', freq=None)
- 是否存在一个大致的范围,使得绝大多数的间隔时间都落在这个区间中?如果存在,请对此范围内的样本间隔秒数画出柱状图,设置
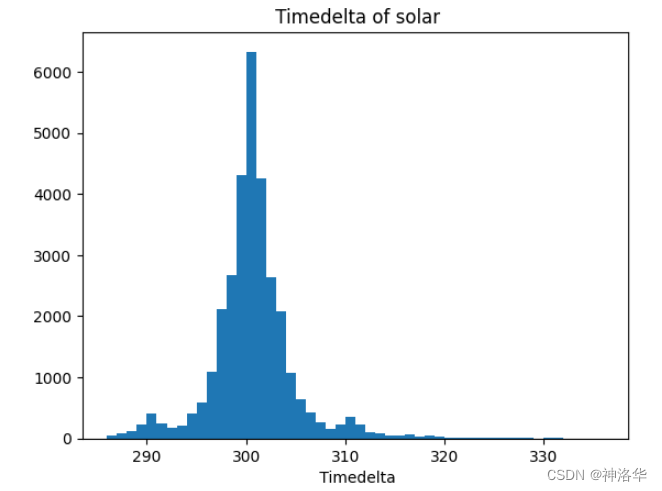
bins=50。
# 将df的indexydiff做差,转为秒数后排序。再求几个分位数确定取值区间
s=pd.Series(df.index).diff(1).dt.total_seconds().sort_values(ascending=False)
s.quantile(0.9),s.quantile(0.95),s.quantile(0.99),s.quantile(0.01),s.quantile(0.03),s.quantile(0.05)
(304.0, 309.0, 337.15999999999985, 285.0, 290.0, 292.0)
%pylab inline
_ = plt.hist(ss[(s.values<337)&(s.values>285)],bins=50)
plt.xlabel(' Timedelta')
plt.title(" Timedelta of solar")
- 求如下指标对应的
Series:- 温度与辐射量的6小时滑动相关系数
- 以三点、九点、十五点、二十一点为分割,该观测所在时间区间的温度均值序列
- 每个观测6小时前的辐射量(一般而言不会恰好取到,此时取最近时间戳对应的辐射量)
df.Radiation.rolling('6H').corr(df.Temperature).tail()
Data
2016-12-31 23:35:02 0.416187
2016-12-31 23:40:01 0.416565
2016-12-31 23:45:04 0.328574
2016-12-31 23:50:03 0.261883
2016-12-31 23:55:01 0.262406
dtype: float64
df['Temperature'].resample('6H',offset='3H').mean().head()
Data
2016-08-31 21:00:00 51.218750
2016-09-01 03:00:00 50.033333
2016-09-01 09:00:00 59.379310
2016-09-01 15:00:00 57.984375
2016-09-01 21:00:00 51.393939
Freq: 6H, Name: Temperature, dtype: float64
最后一题参考答案:
# 非常慢
my_dt = df.index.shift(freq='-6H')
int_loc = [df.index.get_indexer([i], method='nearest') for i in my_dt]
int_loc = np.array(int_loc).reshape(-1)
res = df.Radiation.iloc[int_loc]
res.index = df.index
res.tail(3)
# 纸质版上介绍了merge_asof,性能差距可以达到3-4个数量级
target = pd.DataFrame(
{
"Time": df.index.shift(freq='-6H'),
"Datetime": df.index,
}
)
res = pd.merge_asof(
target,
df.reset_index().rename(columns={"Datetime": "Time"}),
left_on="Time",
right_on="Time",
direction="nearest"
).set_index("Datetime").Radiation
res.tail(3)
Out[224]:
Datetime
2016-12-31 23:45:04 9.33
2016-12-31 23:50:03 8.49
2016-12-31 23:55:01 5.84
Name: Radiation, dtype: float64
Ex2:水果销量数据集
现有一份2019年每日水果销量记录表:
df = pd.read_csv('../data/fruit.csv')
df.head(3)
Out[131]:
Date Fruit Sale
0 2019-04-18 Peach 15
1 2019-12-29 Peach 15
2 2019-06-05 Peach 19
- 统计如下指标:
- 每月上半月(15号及之前)与下半月葡萄销量的比值
- 每月最后一天的生梨销量总和
- 每月最后一天工作日的生梨销量总和
- 每月最后五天的苹果销量均值
- 按月计算周一至周日各品种水果的平均记录条数,行索引外层为水果名称,内层为月份,列索引为星期。
- 按天计算向前10个工作日窗口的苹果销量均值序列,非工作日的值用上一个工作日的结果填充。
import numpy as np
import pandas as pd
- 统计如下指标:
- 每月上半月(15号及之前)与下半月葡萄销量的比值
- 每月最后一天的生梨销量总和
- 每月最后一天工作日的生梨销量总和
- 每月最后五天的苹果销量均值
# 每月上半月(15号及之前)与下半月葡萄销量的比值
df.Date=pd.to_datetime(df.Date)
sale=df.query('Fruit == "Grape"').groupby([df.Date.dt.month,df.Date.dt.day<=15])['Sale'].sum()
sale.columns=['Month','15Dayes','Sale'] # 为啥这么改没用啊
sale=pd.DataFrame(sale)
sale=sale.unstack(1).rename_axis(index={'Date':'Month'},
columns={'Date':'15Days'}).stack(1).reset_index() # unstack主要是两个索引都是Date无法直接重命名
sale.head() # 每个月上下半月的销量
Month 15Days Sale
0 1 False 10503
1 1 True 12341
2 2 False 10001
3 2 True 10106
4 3 False 12814
# 使用自定义聚合函数,分组后每组就上半月和下半月两个值,根据索引位置判断求比值时的分子分母顺序
sale.groupby(sale['Month'])['Sale'].agg(
lambda x: x.max()/x.min() if x.idxmax()>x.idxmin() else x.min()/x.max())
Month
1 1.174998
2 1.010499
3 0.776338
4 1.026345
5 0.900534
6 0.980136
7 1.350960
8 1.091584
9 1.116508
10 1.020784
11 1.275911
12 0.989662
Name: Sale, dtype: float64
# 每月最后一天的生梨销量总和
df[df.Date.dt.is_month_end].loc[df.Fruit=='Pear'].groupby('Date')['Sale'].sum()
Date
2019-01-31 847
2019-02-28 774
2019-03-31 761
2019-04-30 648
2019-05-31 616
# 每月最后一天工作日的生梨销量总和
ls=df.Date+pd.offsets.BMonthEnd()
my_filter=pd.to_datetime(ls.unique())
df[df.Date.isin(my_filter)].loc[df.Fruit=='Pear'].groupby('Date')['Sale'].sum()
Date
2019-01-31 847
2019-02-28 774
2019-03-29 510
2019-04-30 648
2019-05-31 616
# 每月最后五天的苹果销量均值
start, end = '2019-01-01', '2019-12-31'
end = pd.date_range(start, end, freq='M')
end=end.repeat(5) # 每月最后一天的日期列表,重复5次方便做差
td= pd.Series(pd.timedelta_range(start='0 days', periods=5),)
td=pd.concat([td]*12) # 日期偏置,最后一天减去0-4天
end5=(end-td).reset_index(drop=True) # 每个月最后5天的列表
apple5=df[df.Date.isin(end5)].query("Fruit == 'Apple'") # 每月最后五天苹果销量
apple5.groupby(apple5.Date.dt.month)['Sale'].mean().head()
Date
1 65.313725
2 54.061538
3 59.325581
4 65.795455
5 57.465116
# 参考答案:
target_dt = df.drop_duplicates().groupby(df.Date.drop_duplicates(
).dt.month)['Date'].nlargest(5).reset_index(drop=True)
res = df.set_index('Date').loc[target_dt].reset_index(
).query("Fruit == 'Apple'")
res = res.groupby(res.Date.dt.month)['Sale'].mean(
).rename_axis('Month')
res.head()
Out[236]:
Month
1 65.313725
2 54.061538
3 59.325581
4 65.795455
5 57.465116
Name: Sale, dtype: float64
- 按月计算周一至周日各品种水果的平均记录条数,行索引外层为水果名称,内层为月份,列索引为星期。
result=pd.DataFrame(df.groupby([df.Date.dt.month,df.Date.
dt.dayofweek,df.Fruit])['Sale'].count()) # 分组统计
result=result.unstack(1).rename_axis(index={'Date':'Month'},
columns={'Date':'Week'}) # 两个index名字都是Date,只能转一个到列,分开来改名字.
result=result.swaplevel(0,1,axis=0).droplevel(0,axis=1)
result.head() # 索引名有空再改吧
Week 0 1 2 3 4 5 6
Fruit Month
Apple 1 46 50 50 45 32 42 23
Banana 1 27 29 24 42 36 24 35
Grape 1 42 75 53 63 36 57 46
Peach 1 67 78 73 88 59 49 72
Pear 1 39 69 51 54 48 36 40
- 按天计算向前10个工作日窗口的苹果销量均值序列,非工作日的值用上一个工作日的结果填充。
# 工作日苹果销量按日期排序
select_bday=df[~df.Date.dt.dayofweek.isin([5,6])].query('Fruit=="Apple"').set_index('Date').sort_index()
select_bday=select_bday.groupby(select_bday.index)['Sale'].sum() # 每天的销量汇总
select_bday.head()
Date
2019-01-01 189
2019-01-02 482
2019-01-03 890
2019-01-04 550
2019-01-07 494
# 此时已经是工作日,正常滑窗。结果重设索引,对周末进行向后填充。
select_bday.rolling('10D').mean().reindex(df.Date.unique()).sort_index().ffill().head()
Date
2019-01-01 189.000000
2019-01-02 335.500000
2019-01-03 520.333333
2019-01-04 527.750000
2019-01-05 527.750000
终于都做完了。不过《pandas数据处理与分析》这本书还有三章…,慢慢刷了。