Unet医学细胞分割实战
1.医学细胞数据集预处理
如图所示,数据集原始标注为单个细胞,需要运行preprocess_dsb2018.py将标注整合到一张图片中。


2.数据增强工具
GitHub - albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 ,能够同时对数据和标签进行处理,包含物体检测、图像分割等
数据读取部分代码及注释:
class Dataset(torch.utils.data.Dataset):
def __init__(self, img_ids, img_dir, mask_dir, img_ext, mask_ext, num_classes, transform=None):
"""
Args:
img_ids (list): Image ids.
img_dir: Image file directory.
mask_dir: Mask file directory.
img_ext (str): Image file extension.
mask_ext (str): Mask file extension.
num_classes (int): Number of classes.
transform (Compose, optional): Compose transforms of albumentations. Defaults to None.
Note:
Make sure to put the files as the following structure:
<dataset name>
├── images
| ├── 0a7e06.jpg
│ ├── 0aab0a.jpg
│ ├── 0b1761.jpg
│ ├── ...
|
└── masks
├── 0
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
|
├── 1
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
...
"""
self.img_ids = img_ids # 所有的图片名称
self.img_dir = img_dir # 存储图片的文件夹
self.mask_dir = mask_dir # 存储mask的文件夹
self.img_ext = img_ext # 支持的图片文件类型
self.mask_ext = mask_ext # 支持的mask图片文件类型
self.num_classes = num_classes # 类别数量
self.transform = transform # 数据增强方式
def __len__(self):
return len(self.img_ids)
def __getitem__(self, idx):
# 图片名称
img_id = self.img_ids[idx]
# 读取图片数据和mask
img = cv2.imread(os.path.join(self.img_dir, img_id + self.img_ext))
mask = []
for i in range(self.num_classes):
mask.append(cv2.imread(os.path.join(self.mask_dir, str(i),
img_id + self.mask_ext), cv2.IMREAD_GRAYSCALE)[..., None])
mask = np.dstack(mask)
# 数据增强
if self.transform is not None:
augmented = self.transform(image=img, mask=mask)#这个包比较方便,能把mask也一并做掉
img = augmented['image']#参考https://github.com/albumentations-team/albumentations
mask = augmented['mask']
# 归一化
img = img.astype('float32') / 255
img = img.transpose(2, 0, 1) # opencv和pytorch具有差异,pytorch通道数在前面
mask = mask.astype('float32') / 255
mask = mask.transpose(2, 0, 1)
return img, mask, {'img_id': img_id}3.Unet++网络架构
卷积模块VGGBLOCK:一个卷积模块由两个卷积构成,卷积核大小为3*3,步长为1.均使用batchnormalization和relu激活函数
# 卷积模块:两个3*3的卷积,BatchNorm2d和relu激活
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out如图所示:
对于下采样路径:首先经过2*2的池化层进行下采样,然后经过VGGBLOCK,依次得到 X1,0/X2,0,X3,0/X4,0,特征图大小依次为48,24,12,6
特征融合模块:以x0,1为例,由x1,0经过上采样与x0,0进行拼接,再经过卷积模块VGGBLOCK,其中特征融合后,每一层的通道数保持不变,第0层为32,第1层为64,第二层为128,第三层为256,第四层为512。特征融合模块运用了densenet的思想,融合了同一层次前面所有模块的输出和下面模块的输出上采样的结果。
模型的输出:最后再X0,4接入1*1的卷积做输出,如果需要进行监督,可以对X0,1/X0,2/X0,3也做预测。

代码如下:
import torch
from torch import nn
__all__ = ['UNet', 'NestedUNet']
# 卷积模块:两个3*3的卷积,BatchNorm2d和relu激活
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class UNet(nn.Module):
def __init__(self, num_classes, input_channels=3, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#scale_factor:放大的倍数 插值
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1))
output = self.final(x0_4)
return output
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
# print('input:',input.shape)
# 输入:batch_size, 3, 96, 96
x0_0 = self.conv0_0(input) # 32, 96, 96
# print('x0_0:',x0_0.shape)
x1_0 = self.conv1_0(self.pool(x0_0)) # 64, 48, 48
# print('x1_0:',x1_0.shape)
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1)) # 32, 96, 96
# print('x0_1:',x0_1.shape)
x2_0 = self.conv2_0(self.pool(x1_0)) # 128, 24, 24
# print('x2_0:',x2_0.shape)
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1)) # 64, 48, 48
# print('x1_1:',x1_1.shape)
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1)) # 32, 96, 96
# print('x0_2:',x0_2.shape)
x3_0 = self.conv3_0(self.pool(x2_0)) # 256, 12, 12
# print('x3_0:',x3_0.shape)
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1)) # 128, 24, 24
# print('x2_1:',x2_1.shape)
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1)) # 64,48,48
# print('x1_2:',x1_2.shape)
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1)) # 32,96,96
# print('x0_3:',x0_3.shape)
x4_0 = self.conv4_0(self.pool(x3_0)) # 512,6,6
# print('x4_0:',x4_0.shape)
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1)) # 256,12,12
# print('x3_1:',x3_1.shape)
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1)) # 128,24,24
# print('x2_2:',x2_2.shape)
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1)) # 64,48,48
# print('x1_3:',x1_3.shape)
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1)) # 32,96,96
# print('x0_4:',x0_4.shape)
if self.deep_supervision: # 对结果进行监督,输出中间结果
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4) # 输出结果
return output
4.模型的验证
运行val.py,相关代码及注释如下:
def main():
# 读取参数
args = parse_args()
# 读取配置文件
with open('models/%s/config.yml' % args.name, 'r') as f:
config = yaml.load(f, Loader=yaml.FullLoader)
print('-'*20)
for key in config.keys():
print('%s: %s' % (key, str(config[key])))
print('-'*20)
cudnn.benchmark = True
# create model 创建模型
print("=> creating model %s" % config['arch'])
model = archs.__dict__[config['arch']](config['num_classes'],
config['input_channels'],
config['deep_supervision'])
model = model.cuda()
# Data loading code 得到验证集图片名称
img_ids = glob(os.path.join('inputs', config['dataset'], 'images', '*' + config['img_ext']))
img_ids = [os.path.splitext(os.path.basename(p))[0] for p in img_ids]
_, val_img_ids = train_test_split(img_ids, test_size=0.2, random_state=41)
# 加载权重
model.load_state_dict(torch.load('models/%s/model.pth' %
config['name']))
# 进行验证,不进行梯度下降
model.eval()
# 加载验证集数据
val_transform = Compose([
albumentations.augmentations.geometric.resize.Resize(config['input_h'], config['input_w']),
transforms.Normalize(),
])
val_dataset = Dataset(
img_ids=val_img_ids,
img_dir=os.path.join('inputs', config['dataset'], 'images'),
mask_dir=os.path.join('inputs', config['dataset'], 'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=val_transform)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=config['batch_size'],
shuffle=False,
num_workers=config['num_workers'],
drop_last=False)
avg_meter = AverageMeter()
# 创建输出文件夹
for c in range(config['num_classes']):
os.makedirs(os.path.join('outputs', config['name'], str(c)), exist_ok=True)
# 验证部分
with torch.no_grad():
for input, target, meta in tqdm(val_loader, total=len(val_loader)):
input = input.cuda()
target = target.cuda()
# compute output
if config['deep_supervision']:
output = model(input)[-1]
else:
output = model(input)
# 计算IOU
iou = iou_score(output, target)
avg_meter.update(iou, input.size(0))
# 输出结果,经过sigmoid,模型本身的输出没有经过sigmoid
output = torch.sigmoid(output).cpu().numpy()
# 绘制输出结果
for i in range(len(output)):
for c in range(config['num_classes']):
cv2.imwrite(os.path.join('outputs', config['name'], str(c), meta['img_id'][i] + '.jpg'),
(output[i, c] * 255).astype('uint8'))
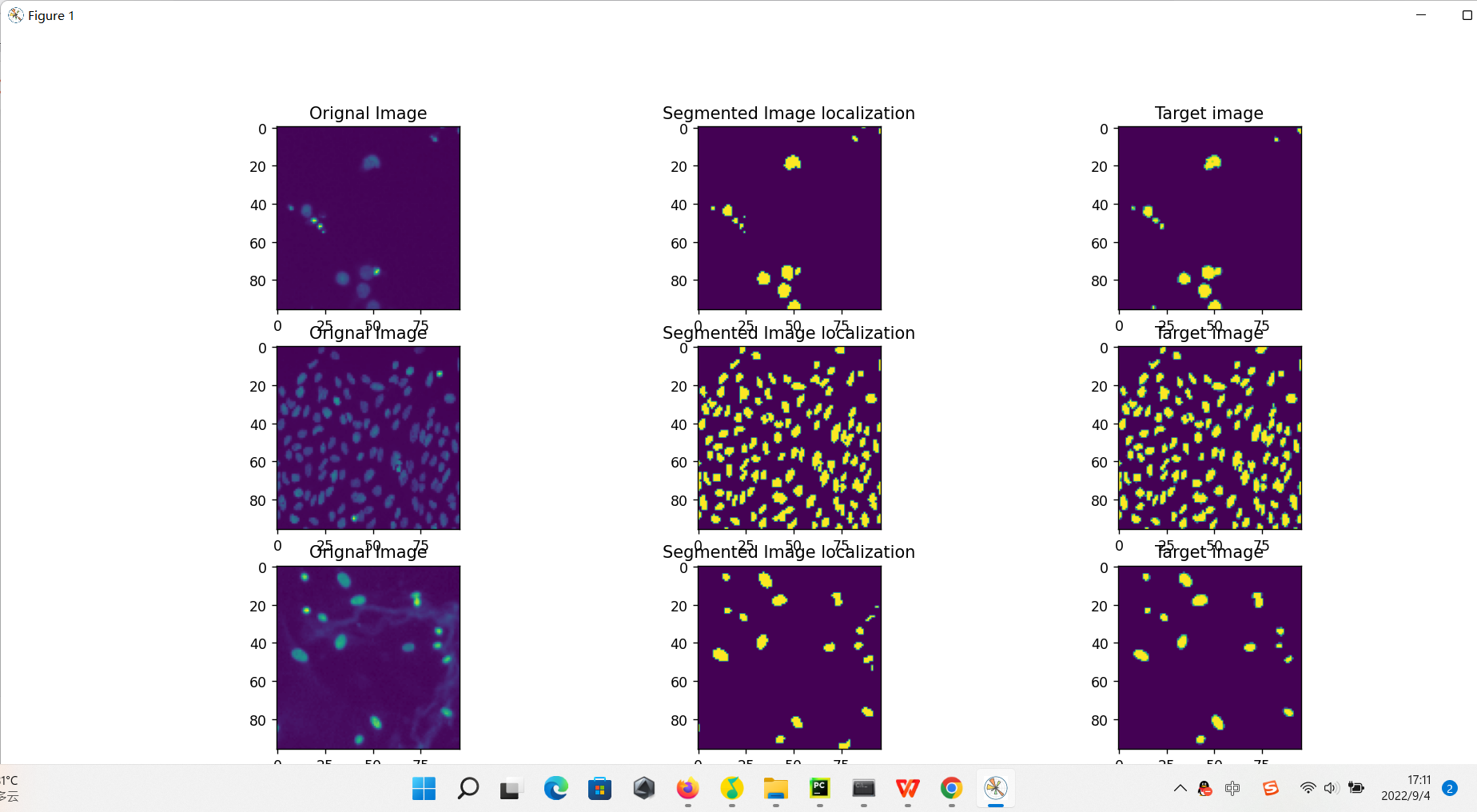
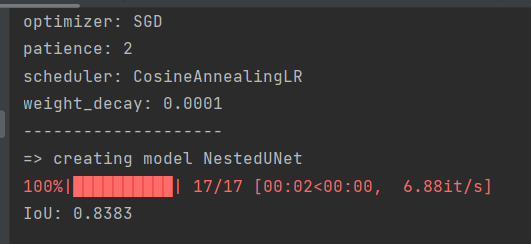
print('IoU: %.4f' % avg_meter.avg)
# 绘制图像:包含预测和标签
plot_examples(input, target, model,num_examples=3)
torch.cuda.empty_cache()
def plot_examples(datax, datay, model,num_examples=6):
fig, ax = plt.subplots(nrows=num_examples, ncols=3, figsize=(18,4*num_examples))
m = datax.shape[0]
for row_num in range(num_examples):
image_indx = np.random.randint(m)
image_arr = model(datax[image_indx:image_indx+1]).squeeze(0).detach().cpu().numpy()
ax[row_num][0].imshow(np.transpose(datax[image_indx].cpu().numpy(), (1,2,0))[:,:,0])
ax[row_num][0].set_title("Orignal Image")
ax[row_num][1].imshow(np.squeeze((image_arr > 0.40)[0,:,:].astype(int)))
ax[row_num][1].set_title("Segmented Image localization")
ax[row_num][2].imshow(np.transpose(datay[image_indx].cpu().numpy(), (1,2,0))[:,:,0])
ax[row_num][2].set_title("Target image")
plt.show()
if __name__ == '__main__':
main()预测结果: