《Mycat分布式数据库架构》之数据切分实战
文章目录
- 1、引言
- 2、前期准备
- 2.1 系统环境
- 2.2 数据库集群
- 3 注意事项
- 3.1 分片原则
- 3.2 如何选择分片键
- 4 数据切分实战
- 4.1 配置访问用户及权限
- 4.2 配置逻辑库及逻辑表
- 4.3 配置分片规则
- 4.3.1 简单取模分片
- 4.3.2 哈希取模分片
- 4.3.3 枚举分片
- 4.3.4 字符串范围取模分片
前文回顾:
《Mycat分布式数据库架构》之原理及架构
《Mycat分布式数据库架构》之搭建详解
《Mycat分布式数据库架构》之配置详解
《Mycat分布式数据库架构》之数据切分和读写分离
《Mycat分布式数据库架构》之故障切换
1、引言
本文将建立一个人事管理的数据库,使用水平拆分来做实际演示,并且后期解决分片后的一些问题,比如分片导致的跨库join等问题,以达到一个进阶实战的效果 。
2、前期准备
2.1 系统环境
我的虚拟机配置如下。
系统:CentOS 7 64位
内存:3GB
硬盘:80GB
2.2 数据库集群
数据库我部署了两个数据节点,环境说明如下所示:
| ip | 角色 | 数据库 |
|---|---|---|
| 192.168.157.129 | Mycat | |
| 192.168.157.129 | Oracle | human |
| 192.168.157.130 | Oracle | human |
这里我在两台服务器上安装部署了oracle数据库,并在其中一台服务器部署了mycat。
为了方便后期切分示例演示,需要先了解数据库表结构,首先在linux中先为数据库创建用户,sqlplus命令如下。
CONNECT sys/pwd @human_res AS SYSDBA;
CREATE USER human IDENTIFIED BY human DEFAULT TABLESPACE USERS;
GRANT CONNECT,RESOURCE,CREATE VIEW TO human;
创建一个人事管理系统数据库来进行实战演示,创建表语句如下
REGIONS表:
CREATE TABLE REGIONS(
REGION_ID NUMBER PRIMARY KEY,
REGION_NAME VARCHAR2(25)
)
TABLESPACE USERS;
COUNTRIES表:
CREATE TABLE COUNTRIES(
COUNTRY_ID CHAR(2) PRIMARY KEY,
COUNTRY_NAME VARCHAR2(40),
REGION_ID NUMBER REFERENCES REGIONS(REGION_ID)
)
TABLESPACE USERS;
LOCATIONS表:
CREATE TABLE LOCATIONS(
LOCATION_ID NUMBER PRIMARY KEY,
STREET_ADDRESS VARCHAR2(40),
POSTTAL_CODE VARCHAR2(12),
CITY VARCHAR2(30) NOT NULL,
STATE_PROVINCE VARCHAR2(25),
COUNTY_ID CHAR(2) REFERENCES COUNTRIES(COUNTRY_ID)
)
TABLESPACE USERS;
DEPARTMENTS表:
CREATE TABLE DEPARTMENTS(
DEPARTMENT_ID NUMBER(4) PRIMARY KEY,
DEPARTMENT_NAME VARCHAR2(30) NOT NULL,
MANAGER_ID NUMBER(6),
LOCATION_ID NUMBER(4) REFERENCES LOCATIONS(LOCATION_ID)
)
TABLESPACE USERS;
JOBS表:
CREATE TABLE JOBS(
JOB_ID VARCHAR2(10) PRIMARY KEY,
JOB_TITLE VARCHAR2(35) NOT NULL,
MIN_SALARY NUMBER(6),
MAX_SALARY NUMBER(6)
)
TABLESPACE USERS;
EMPLOYEES表:
CREATE TABLE EMPLOYEES(
EMPLOYEE_ID NUMBER(6) PRIMARY KEY,
FIRST_NAME VARCHAR2(20),
LAST_NAME VARCHAR2(25) NOT NULL,
EMAIL VARCHAR2(25) NOT NULL UNIQUE,
PHONE_NUMBER VARCHAR2(20),
HIRE_DATE DATE NOT NULL,
JOB_ID VARCHAR2(10) NOT NULL REFERENCES JOBS(JOB_ID),
SALARY NUMBER(8,2) CHECK (SALARY>0),
COMMISSION_PCT NUMBER(2,2),
MANAGER_ID NUMBER(6,0),
DEPARTMENT_ID NUMBER(4,0) REFERENCES DEPARTMENTS(DEPARTMENT_ID)
)
TABLESPACE USERS;
JOB_HISTORY表:
CREATE TABLE JOB_HISTORY(
EMPLOYEE_ID NUMBER(6) NOT NULL REFERENCES EMPLOYEES(EMPLOYEE_ID),
START_DATE DATE NOT NULL,
END_DATE DATE NOT NULL,
JOB_ID VARCHAR2(10) NOT NULL REFERENCES JOBS(JOB_ID),
DEPARTMENT_ID NUMBER(4) REFERENCES DEPARTMENTS(DEPARTMENT_ID),
CONSTRAINT JHIST_DATE_INTERVAL CHECK (END_DATE>START_DATE),
CONSTRAINT JHIST_EMP_ID_ST_DATE_PK PRIMARY KEY (EMPLOYEE_ID,START_DATE)
)
TABLESPACE USERS;
SAL_GRADES表:
CREATE TABLE SAL_GRADES(
GRADE NUMBER PRIMARY KEY,
MIN_SALARY NUMBER(8,2),
MAX_SALARY NUMBER(8,2)
)
TABLESPACE USERS;
USERS表:
CREATE TABLE USERS(
USER_ID NUMBER(2) PRIMARY KEY,
USER_NAME CHAR(20),
PASSWORD VARCHAR2(20) NOT NULL
)
TABLESPACE USERS;
为了方便后面演示全局自增ID,这里将EMPLOYEES表的EMPLOYEE_ID设置为自增ID,如下,创建一个名为“EMPLOYEES_SEQ”的序列,起始值为100,步长为1,不缓存,不循环。
CREATE SEQUENCE EMPLOYEES_SEQ
START WITH 100
INCREMENT BY 1
NOCACHE
NOCYCLE;
接着创建触发器,如下:
CREATE OR REPLACE TRIGGER EMPLOYEES_SEQ_TRG
BEFORE INSERT ON EMPLOYEES
FOR EACH ROW
WHEN (NEW.EMPLOYEE_ID IS NULL)
BEGIN
SELECT EMPLOYEES_SEQ.NEXTVAL
INTO :NEW.EMPLOYEE_ID
FROM DUAL;
END;
我们可以使用navicat来连接mycat,这样就可以方便对数据进行操作,连接mycat的方式和连接mysql方式相同,点击连接,选择mysql,然后填写如下信息。
其中端口是在mycat的server.xml文件中配置的端口,默认8066;用户名密码也是在server.xml文件中配置的访问用户和密码,连接成功后即可看到配置的逻辑库和逻辑表,如下。
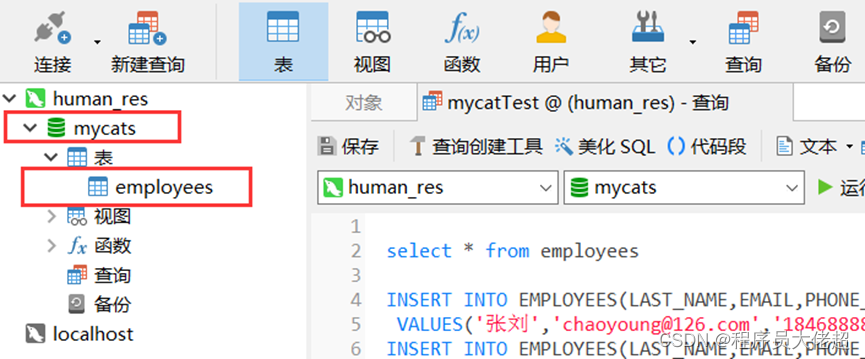
mycats 就是逻辑库,employees便是配置的逻辑表,目前对于应用程序来说和普通数据库没什么区别,无需关系底层物理数据库,只是当前逻辑数据库中只有一个表,其余表还需全部进行配置。
3 注意事项
3.1 分片原则
- 能不切分尽量不要切分。
- 选择合适的切分规则和分片键。
- 尽量避免跨分片JOIN操作。
3.2 如何选择分片键
- 尽可能的比较均匀的分配到各个数据节点中。
- 该业务字段是最频繁的或最重要的查询条件。
4 数据切分实战
4.1 配置访问用户及权限
使用server.xml配置访问用户及权限,如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">2</property>
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="processorBufferPoolType">0</property>
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">0</property>
<property name="memoryPageSize">64k</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<user name="yxc" defaultAccount="true">
<property name="password">yxc123456</property>
<property name="schemas">mycats</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">mycats</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
4.2 配置逻辑库及逻辑表
使用schema.xml配置逻辑库及逻辑表
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycats" checkSQLschema="false" sqlMaxLimit="100">
<table name="EMPLOYEES" primaryKey="EMPLOYEE_ID" dataNode="datanode01,datanode02" rule="EMPLOYEES"/>
</schema>
<dataNode name="datanode01" dataHost="host01" database="human_res" />
<dataNode name="datanode02" dataHost="host02" database="hr" />
<dataHost name="host01" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="oracle" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<!--心跳sql-->
<heartbeat>select 1 from dual</heartbeat>
<writeHost host="192.168.157.130" url="jdbc:oracle:thin:@192.168.157.130:1521:humanres" user="human" password="human">
</writeHost>
</dataHost>
<dataHost name="host02" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="oracle" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<!--心跳sql-->
<heartbeat>select 1 from dual</heartbeat>
<writeHost host="192.168.157.129" url="jdbc:oracle:thin:@192.168.157.129:1521:hr" user="human" password="human">
</writeHost>
</dataHost>
</mycat:schema>
4.3 配置分片规则
使用rule.xml 配置分片表的分片规则,根据业务可以灵活的对表使用不同的分片算法(目前已实现十余种不同的分片规则,对应所在源码包为:io.mycat.route.function),或者对表使用相同的算法但具体的参数不同。下面对常用算法分别进行演示。
4.3.1 简单取模分片
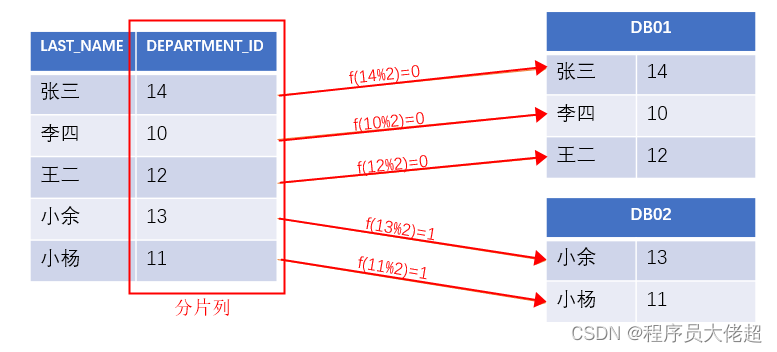
简单取模分片-PartitionByMod算法具有以下特性:
- 只能用于分片列为整数类型的表
- 分片列 mod 分片基数
- 类全名:
io.mycat.route.function.PartitionByMod
这里我使用EMPLOYEES表来进行分片演示,简单取模分片只能用于整数列,EMPLOYEE_ID已经为自增ID,所以我选择它的外键DEPARTMENT_ID作为分片列,如下,分片规则使用简单取模分片,片数为2。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="EMPLOYEES">
<rule>
<columns>DEPARTMENT_ID</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
接着向mycat逻辑库中添加数据,如下
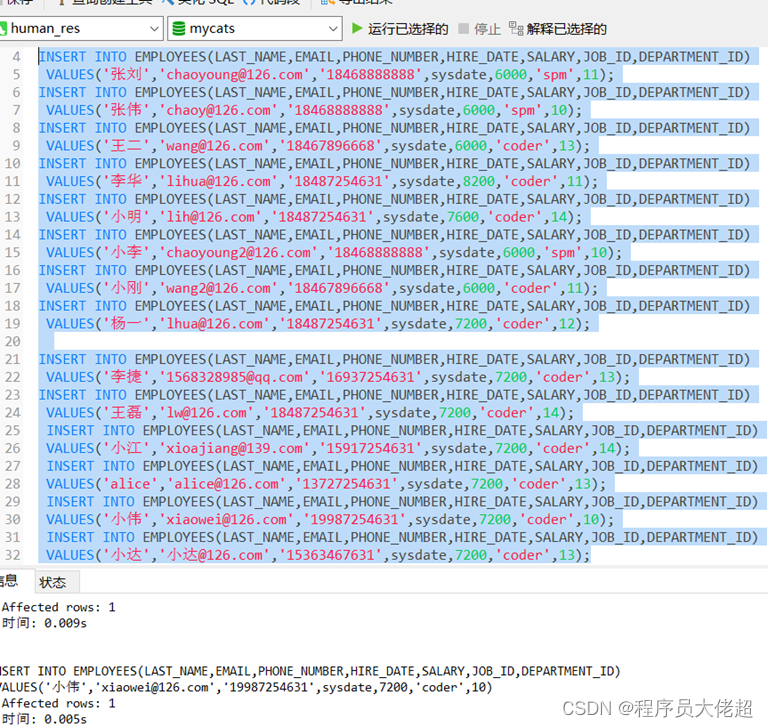
分别查看两个数据节点中的数据,根据取模算法,刚才插入的数据中DEPARTMENT_ID值为10、12、14的取模结果为0,都将插入第一个节点。第一个节点192.168.157.130中数据如下所示
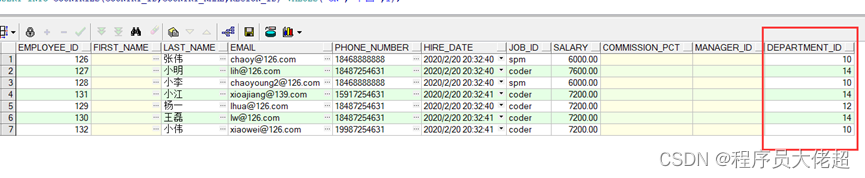
同理,11、13取模结果为1,都将插入第二个节点192.168.157.129中,如下所示。

对于EMPLOYEES这张表来说,它的主键EMPLOYEE_ID为自增ID,那这里我向mycat插入数据时,底层各节点物理数据库会各自对ID进行自增,所以会出现重复的情况,解决这个问题需要使用全局自增ID,在下文第5点中会进行讲解。
4.3.2 哈希取模分片
哈希取模算法就是计算出分片列,然后进行取模计算,从而进行分片存储,例如
Hash('chao dev')%count
哈希取模-PartitionByHashMod算法具有以下特性:
• 可以用于多种数据类型,如字符串,日期等
• hash(分片列) mod分片基数
• 类全名:io.mycat.route.function.PartitionByHashMod
这里使用EMPLOYEES表来进行分片演示,选择LAST_NAME列来作为分片列,节点数同样为2。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="EMPLOYEES">
<rule>
<columns>LAST_NAME</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByHashMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
4.3.3 枚举分片
枚举分片算法比较简单,就是指定哪些值存储什么数据节点,除此之外还有一个默认节点,没指定的值都将存储进入默认节点中,如下图所示。
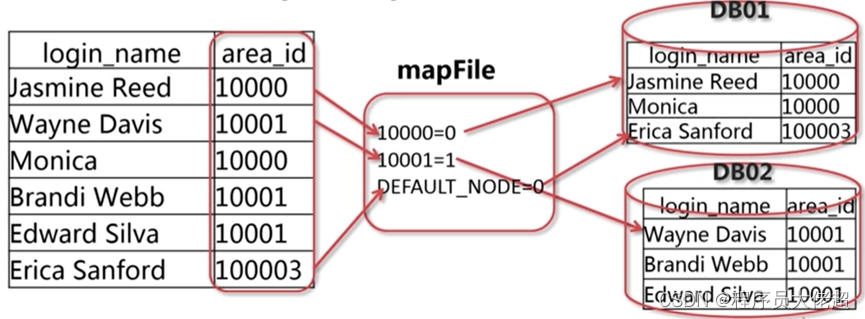
枚举分片-PartitionByFileMap算法具有以下特性:
• 可以根据可能的枚举值指定数据存储的位置
• mycat/conf目录下增加MapFile配置枚举值同对应节点的对应关系
• 类全名:io.mycat.route.function.PartitionByFileMap
这里使用EMPLOYEES表来进行分片演示,DEPARTMENT_ID列来作为分片列。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="EMPLOYEES">
<rule>
<columns>DEPARTMENT_ID</columns>
<algorithm>filemap-emp</algorithm>
</rule>
</tableRule>
<function name="filemap-emp" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-filemap-emp-init.txt</property> <!-- 配置在mycat的conf目录下-->
<property name="type">0</property><!-- 0:整数类型,非0:string类型-->
<!-- 是否使用默认节点,>=0表示启用,<0表示不启用-->
<property name="defaultNode">0</property>
</function>
</mycat:rule>
4.3.4 字符串范围取模分片
字符串范围取模分片是利用选取的字符串前N个字符来进行ASCII值来求和,然后根据求模基数计算出值,如下所示:
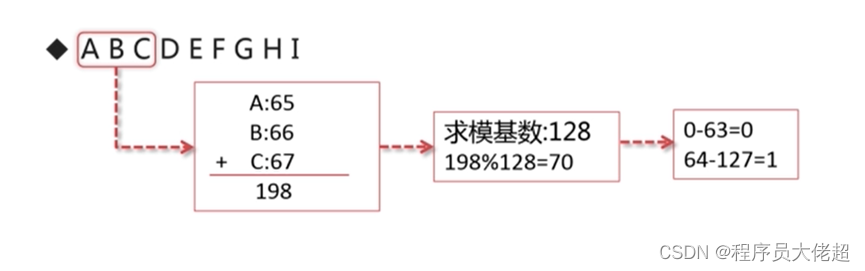
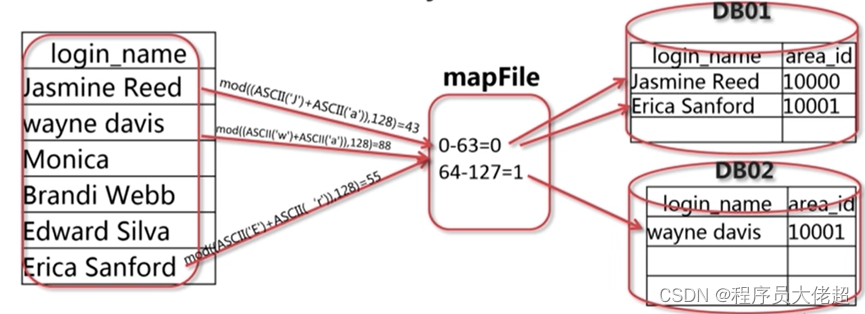
字符串范围取模分片-PartitionByPrefixPattern算法具有以下特性:
• 可以根据字符串的前N个字符确定数据存储的位置
• mycat/conf目录下增加MapFile配置枚举值同对应节点的对应关系
• 类全名:io.mycat.route.function.PartitionByPrefixPattern
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="EMPLOYEES">
<rule>
<columns>EMAIL</columns>
<algorithm>sharding-by-prefix-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-prefix-pattern" class="io.mycat.route.function.PartitionByPrefixPattern">
<property name="patternValue">128</property> <!-- 取模基数-->
<property name="prefixLength">0</property><!-- 要取的字符串长度,2代表取前两个字符->
<!-- 取模范围和数据节点的对应关系,需要配置在mycat的conf目录下-->
<property name="mapFile">prefix-partition-pattern.txt</property>
</function>
</mycat:rule>
更多技术干货,请持续关注程序员大佬超。
原创不易,转载请注明出处。