MySQL的EXPLAIN执行计划深入分析
目录
一、EXPLAIN介绍
二、准备数据
三、重要的属性介绍
3.1、select_type——查询类型
SIMPLE:表示查询语句不包含子查询或union。
PRIMARY: 查询中若包含任何复杂的子查询,最外层查询则被标记为Primary。
UNION:表示此查询是UNION的第二个或后续的查询。在union, union all的第二个以及随后的select被标记为union。
DEPENDEN UNION:UNION中的第二个或后续的查询语句,使用到了外面查询结果。
UNION RESULT:从UNION表中获取的结果。
SUBQUERY:SELECT子查询语句。
DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果。
3.2、Type——表示存储引擎查询数据时采用的方式
3.3、possible_keys——表示查询时能够使用到的索引
3.4、key——表示查询时真正使用到的索引
3.5、rows——估算SQL要查询到结果需要扫描多少行记录
3.6、key_len——表示查询使用了索引的字节数量
3.7、Extra——表示额外的信息
四、参考资料
一、EXPLAIN介绍
MySQL提供了一个EXPLAIN命令,它可以对SELECT语句进行分析,并输出SELECT执行的详细信息,供开发人员有针对性的优化。例如:
| EXPLAIN select * from user where id < 3; |

说明:
- 5.6版本如果想显示filtered,则需要使用explain extended,本次演示的是5.7版本。
- 查看版本使用 select version()。
- 语句右面的“\G”是未来在cmd界面竖列展示。
二、准备数据
-- ----------------------------
-- Table structure for persion
-- ----------------------------
DROP TABLE IF EXISTS `persion`;
CREATE TABLE `persion` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`is_delete` tinyint(4) NULL DEFAULT 0 COMMENT '0:正常 1:已废弃',
`create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_age`(`age`) USING BTREE,
INDEX `idx_name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of persion
-- ----------------------------
INSERT INTO `persion` VALUES (1, '张三', 20, 0, '2022-09-12 14:22:12', '2022-09-12 14:24:36');
INSERT INTO `persion` VALUES (2, '李四', 19, 0, '2022-09-12 14:23:36', '2022-09-12 14:23:36');
INSERT INTO `persion` VALUES (3, '王五', 20, 0, '2022-09-12 14:23:43', '2022-09-12 14:23:43');
INSERT INTO `persion` VALUES (4, '赵六', 21, 0, '2022-09-12 14:23:51', '2022-09-12 14:23:51');
INSERT INTO `persion` VALUES (5, '孙七', 20, 0, '2022-09-12 14:24:13', '2022-09-12 14:24:31');
INSERT INTO `persion` VALUES (6, '周八', 22, 0, '2022-09-12 14:24:23', '2022-09-12 16:00:16');三、重要的属性介绍
3.1、select_type——查询类型
常用的值如下:
-
SIMPLE:表示查询语句不包含子查询或union。
示例语句如:explain select * from persion
-
PRIMARY: 查询中若包含任何复杂的子查询,最外层查询则被标记为Primary。
示例语句如:explain select * from persion where id = 1
Union
Select * from persion where id = 2;
-
UNION:表示此查询是UNION的第二个或后续的查询。在union, union all的第二个以及随后的select被标记为union。
示例语句如:explain select * from persion where id = 1
Union
Select * from persion where id = 2;
-
DEPENDEN UNION:UNION中的第二个或后续的查询语句,使用到了外面查询结果。
在包含UNION或者UNION ALL的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的select_type的值就是DEPENDENT UNION。
示例语句如:
explain select * from persion where id in(
select id from persion where age =19
union
select id from persion where age =20
union
select id from persion where age=21);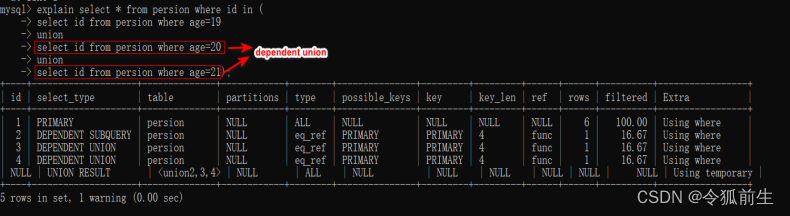
-
UNION RESULT:从UNION表中获取的结果。
示例语句如:
explain select * from persion where age= 18
Union
Select * from persion where age=19;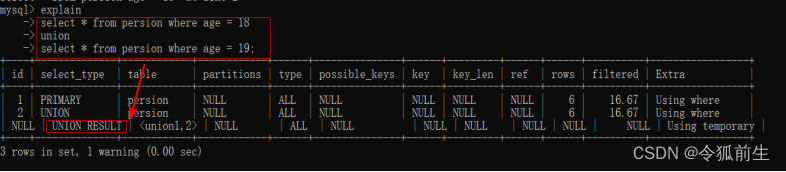
-
SUBQUERY:SELECT子查询语句。
示例语句如:
explain select * from persion where age = (select max(age) from persion);
-
DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果。
示例语句如:
explain select * from persion p1 where id =(select max(p2.id) from persion p2 where p1.age=20 );
最常见的查询类型是SIMPLE,表示我们的查询没有子查询也没有用到UNION查询。
3.2、Type——表示存储引擎查询数据时采用的方式
type是比较重要的一个属性,通过它可以判断出是全表扫描还是基于索引的部分扫描。
常用属性值如下,从上至下效率依次增强。
- ALL:表示全表扫描,性能最差。
语句如:explain select * from persion;
- Index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
语句1如:explain select * from persion oder by id;
语句2如:explain select * from persion where age = 18 order by id desc;
注意:如果使用的条件没有建立索引,则type是all。
- range:表示使用索引范围查询, 使用>、 >=、 <=、between...and、 in等等。
语句1如:explain select * from persion where id > 1;
语句2如:explain select * from persion where id between 2 and 5;
- ref: 表示使用非唯一索引进行单值查询。
前提,我们为age字段建立一个普通索引。
语句1如:explain select * from persion where age = 22;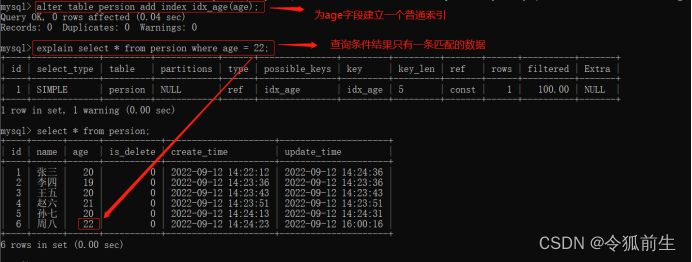
语句2如:此时如果查询age不能22,有多个的话,则type是ALL。explain select * from persion where age != 22;
explain select * from persion where age = 20;
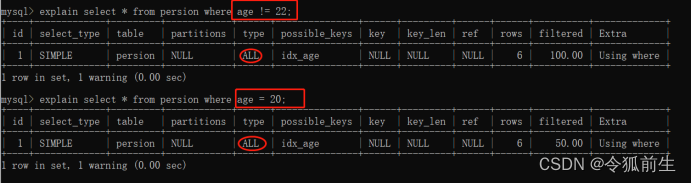
- eq_ref:一般情况下出现在多表join查询,表示前面表的记录,存在与后面表的数据有关联,存在关联关系。
前提:准备另一张表car及数据:
CREATE TABLE `car` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`persion_id` int(11) NULL DEFAULT NULL,
`car_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`car_price` decimal(10, 2) NULL DEFAULT NULL,
`is_delete` tinyint(4) NULL DEFAULT 0,
`create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` datetime NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of car
-- ----------------------------
INSERT INTO `car` VALUES (1, 1, '五菱神车', 5.00, 0, '2022-09-12 15:58:10', '2022-09-12 15:58:10');
INSERT INTO `car` VALUES (2, 2, '哈弗h6', 8.00, 0, '2022-09-12 15:58:26', '2022-09-12 15:58:26');
INSERT INTO `car` VALUES (3, 3, '吉利CS75', 10.00, 0, '2022-09-12 15:58:48', '2022-09-12 15:58:48');
INSERT INTO `car` VALUES (4, 4, '欧尚Z6', 8.00, 0, '2022-09-12 15:59:13', '2022-09-12 15:59:13');
INSERT INTO `car` VALUES (5, 5, '宋PLUS-DMI', 16.00, 0, '2022-09-12 15:59:46', '2022-09-12 15:59:46');
INSERT INTO `car` VALUES (6, 6, '汉', 23.00, 0, '2022-09-12 16:00:07', '2022-09-12 16:00:07'); 语句如:explain select * from persion p, car c where p.id=c.persion_id;
- const:表示使用主键或唯一索引做等值查询,也叫常量查询。
语句如:explain select * from persion where id = 2;
- null:表示不用访问表,直接出结果,速度最快。
语句如:explain select now();
3.3、possible_keys——表示查询时能够使用到的索引
注意:并不一定真正全部使用,显示的是索引名称。
3.4、key——表示查询时真正使用到的索引
注意:key显示的才是查询时真正使用到的索引,显示的是索引名称。
3.5、rows——估算SQL要查询到结果需要扫描多少行记录
说明:MYSQL查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少记录。原则上rows是越少效率越高,可以直观的了解到SQL效率高低。
3.6、key_len——表示查询使用了索引的字节数量
说明:通过key_len可以判断是否全部使用了组合索引,或只用到索引的最左部分的部分字段值。
Key_len的计算规则如下:
- 字符串类型
字符串长度都跟字符集有关:latin1=1、gbk=2、utf8=3、utf8mb4=4
char(n): n * 字符集长度
Varchar(n): n * 字符集长度 + 2字节(因为是可变类型,所以加2个字节)
- 数值类型
TINYINT:1个字节
SMALLINT: 2个字节
MEDIUMINT: 3个字节
INT、FLOAT: 4个字节
BIGINT、DOUBLE:8个字节
- 时间类型:
DATE: 3个字节
TIMESTAMP: 8个字节
DATETIME: 8个字节
- 字段属性:
NULL属性占用1个字节,如果一个字段设置了NOT NULL,则没有此项。
示例剖析:
示例1: Explain select * from persion where id = 1;
剖析:使用到字段id,id是int类型,所以key_len是4。
示例2:Explain select * from persion where age =18(前面给age添加过滤普通索引)。
剖析:使用到字段age,age是int类型,且DEFAULT NULL,所以key_len=4+1,是5。
示例3:explain select * from persion where name='张三';
执行语句前给表persion的字段name添加普通索引:
alter table persion add index idx_name(name);

执行语句后的结果:
剖析:使用字段name,name是varchar类型,长度都255个,且DEFAULT NULL, 表使用字符集utf8mb4, 所以key_len= 255 *4+ 2+1, 是1023。
3.7、Extra——表示额外的信息
常见的集中如下:
- Using where——查询的列未被索引覆盖,where筛选条件非索引列。在查找使用索引的情况下,需要回表去查询所需的数据。
示例:explain select * from persion where age >18;

剖析1:执行计划结果possible_keys的值是idx_age(age的索引名),但key的实际值却是NULL, 且查询出来的字段是*号表示,所以extra的值是using where,可以分析出还是需要回表将表的所有字段查询出来。
- Using index——表示查询需要通过索引,索引就可以满足所需数据。表示索引能够覆盖所有的查询字段,无需进行回表查询。
示例1:explain select id from persion where id = 1;
剖析:查询条件使用字段id, 且查询字段也是id, id字段是主键索引。所以Extra的值出现了Using index。
示例2:explain select id, age from persion where age >20;
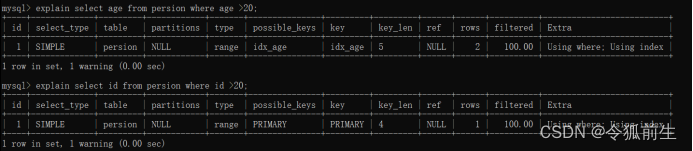
剖析:查询的列被索引覆盖,并且 where筛选条件是索引列之一。但无法直接通过索引查找来查询到符合条件的数据。
- NULL——既没有Using index,也没有Using where Using index,也没有using where.
查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引,Extra中为NULL(没有信息)。
示例:explain select id,age from persion where age =20 and id = 5;

- Using filesort——表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘。因此有Using filesort建议优化。
示例:
1、explain select * from persion order by age;
2、explain select * from persion order by age desc;

- Using temproary——查询使用到了临时表,一般出现于去重等操作。
执行计划前,我们先删掉除主键索引的全部索引。
示例1:explain select distinct(age) from persion ;
剖析:操作的字段没有索引,执行distinct(该字段)时会生成临时表。
示例2:explain select age from persion group by age;
剖析:操作的字段没有索引,执行group by (该字段)时会生成临时表,再内存中排序。
四、参考资料
- 8_EXPLAIN查询分析之select_type详解_哔哩哔哩_bilibili
- mysql explain解析一 extra中的using index,using where,using index condition - zhp_king - 博客园
- MySQL进阶系列: 一文详解explain各字段含义,分层展示的架构图_普通网友的博客