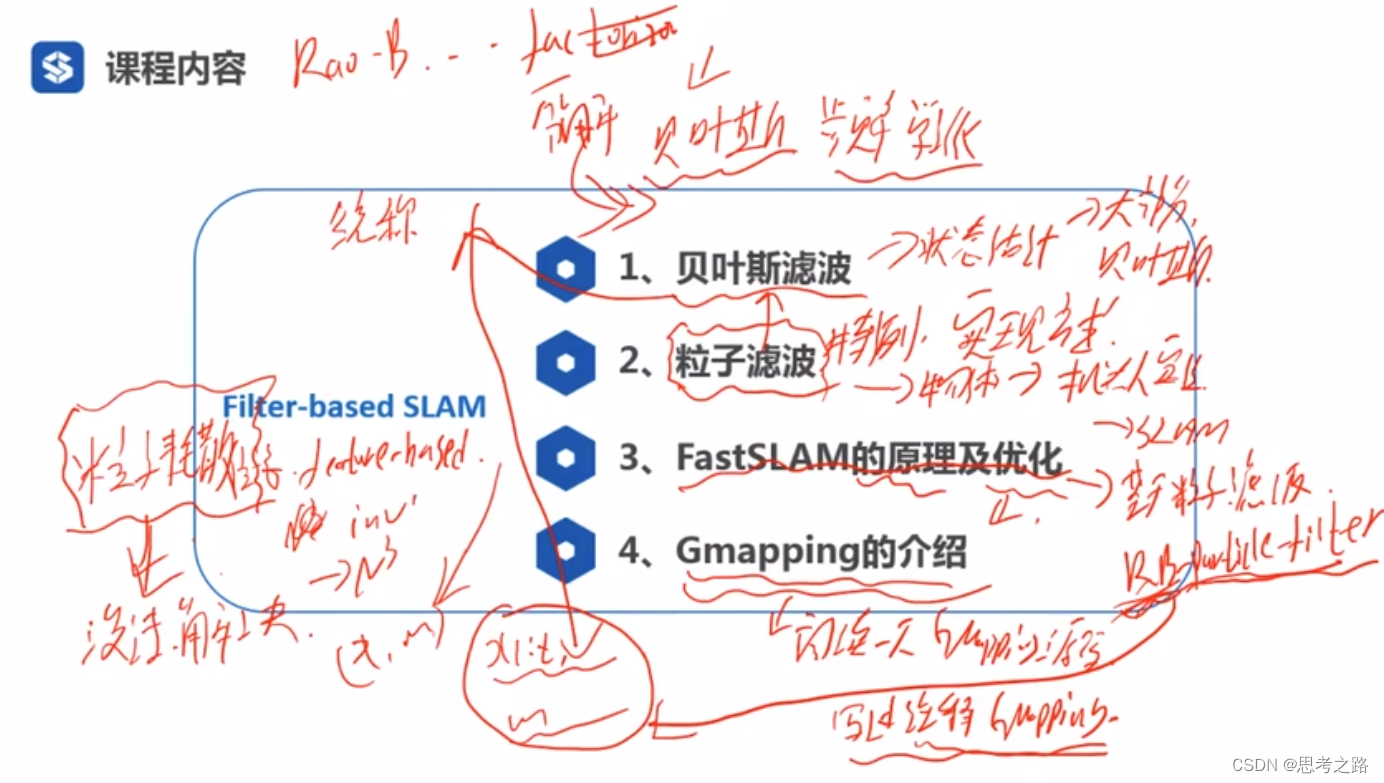
深蓝激光slam理论与实践-第五节笔记(基于滤波器的激光slam方法(Grid-based))

粒子滤波是贝叶斯滤波的特例或是实现方式,由于滤波是估计当前的位姿和地图,不能修复之前的误差,所以随着环境地图的增大,出错的可能性越来越大,主要造成这种情况的原因是粒子耗散问题,这个问题没办法解决只能缓解,因为这个原因所以粒子滤波只能在环境比较小的时候发挥比较好的效果,环境一大就会出错。
FastSLAM是基于粒子滤波的。

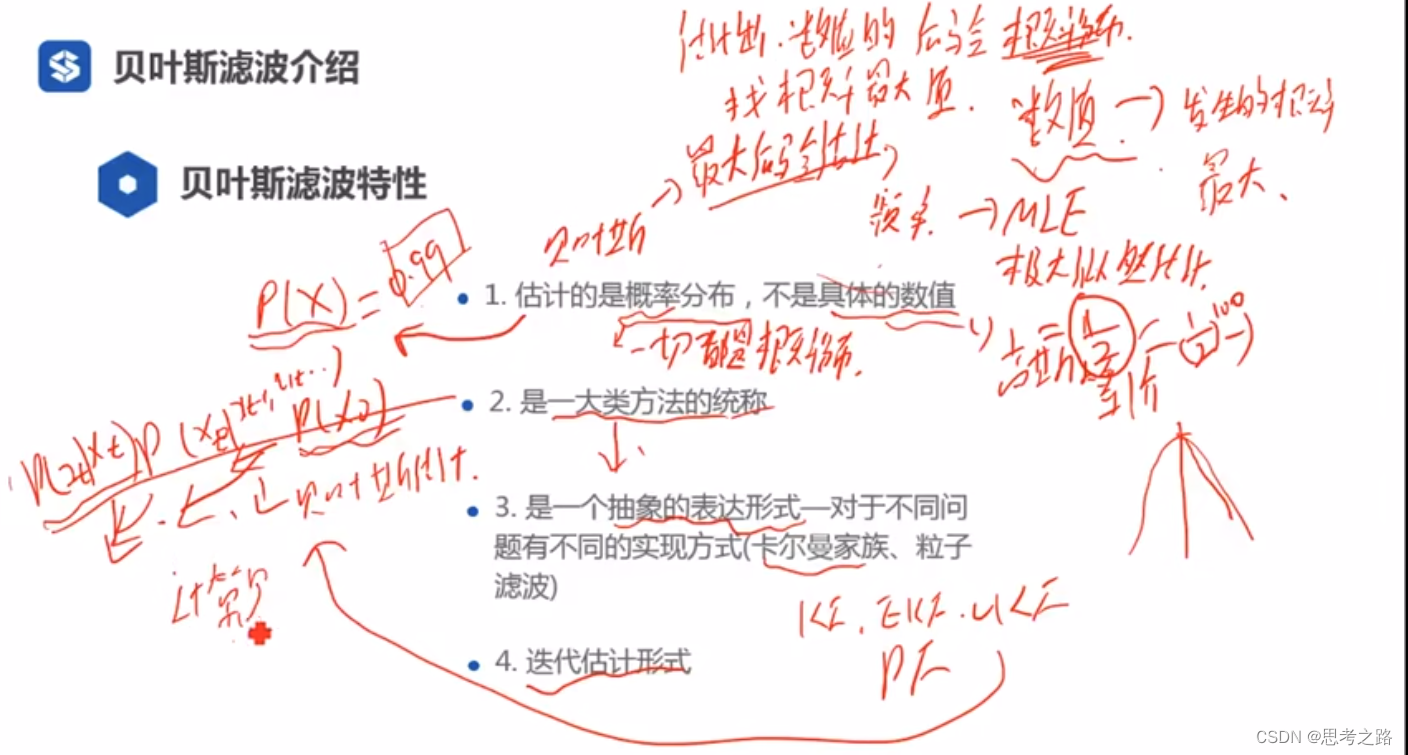
极大似然估计(MLE)是指找到一个数值使得当前发生的概率达到最大。
贝叶斯估计是指我估计出我想要的数值的最大后验概率分布,然后找到概率最大值的地方。这两种情况的高斯分布情况结果是相同的
卡尔曼滤波是贝叶斯滤波高斯,线性的特例

贝叶斯滤波:通过t-1时刻的概率分布预测t时刻的概率分布,然后通过t时刻的观测进行校正得到t时刻概率分布,这种方式也是迭代估计,例如已知x0时刻的概率通过迭代估计可以计算出任意时刻的概率分布。

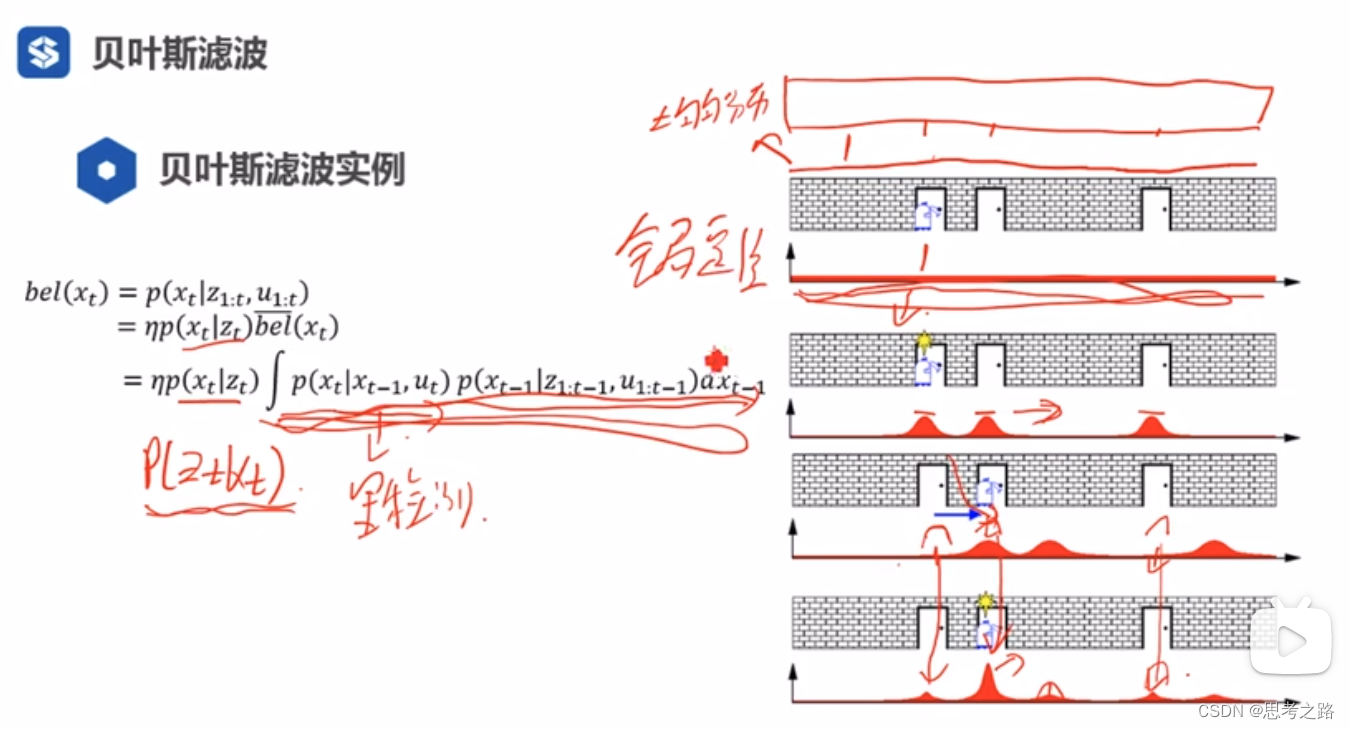
上图中的第二幅图到第三幅图是状态转移过程,并且混有噪声(xt = Axt-1 + B), 图三到 图四是观测与预测概率的卷积结果。

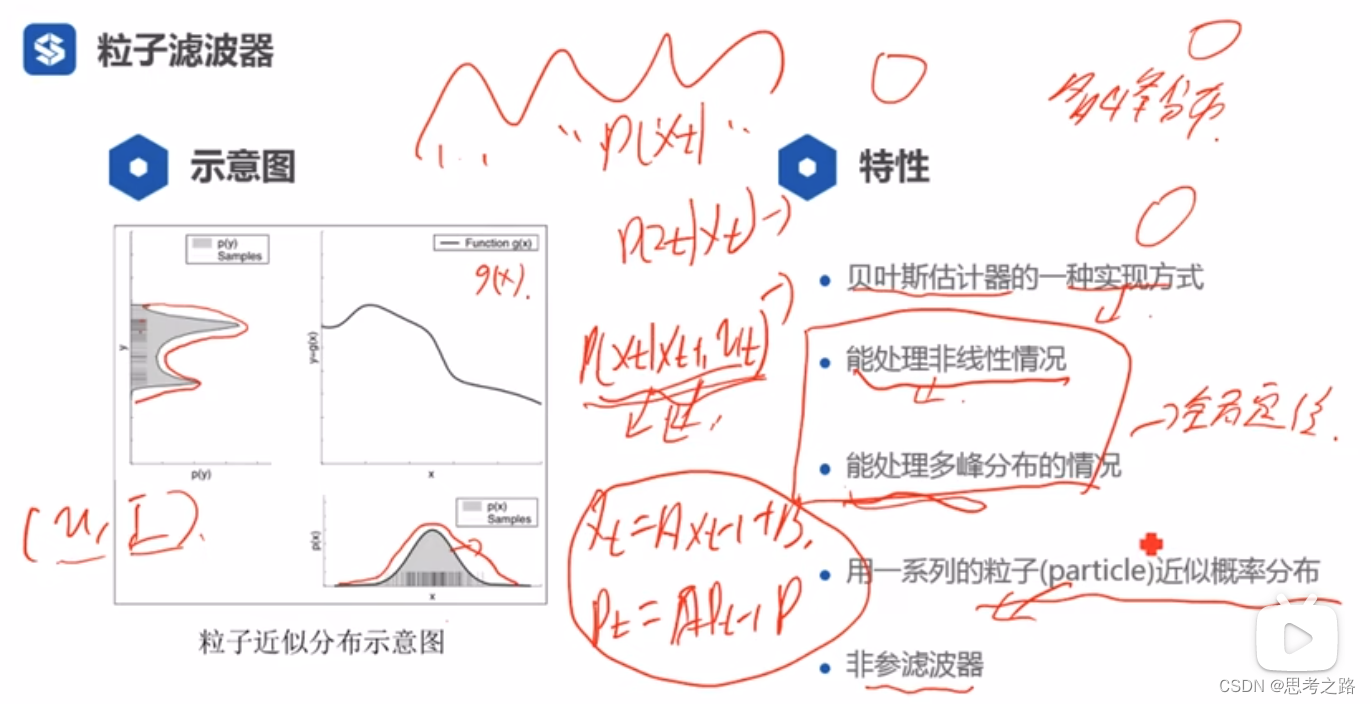
非线性情况处理:由下图最左边的图可以看到,高峰处粒子数多,低峰处粒子数少,很适合机器人进行定位和建图,因为机器人的定位和建图是非线性的。
多峰分布:用于全局定位,当观测信息不够时,机器人的位置在几个峰处都是有可能的。
非参滤波器:高斯滤波器通过均值和方差来确定分布,而粒子滤波是由一些列粒子来表示分布的,它是没有参数的。
总上所述:粒子滤波的这些特性很适合处理机器人一些问题,所以很适用与机器人的定位和建图。
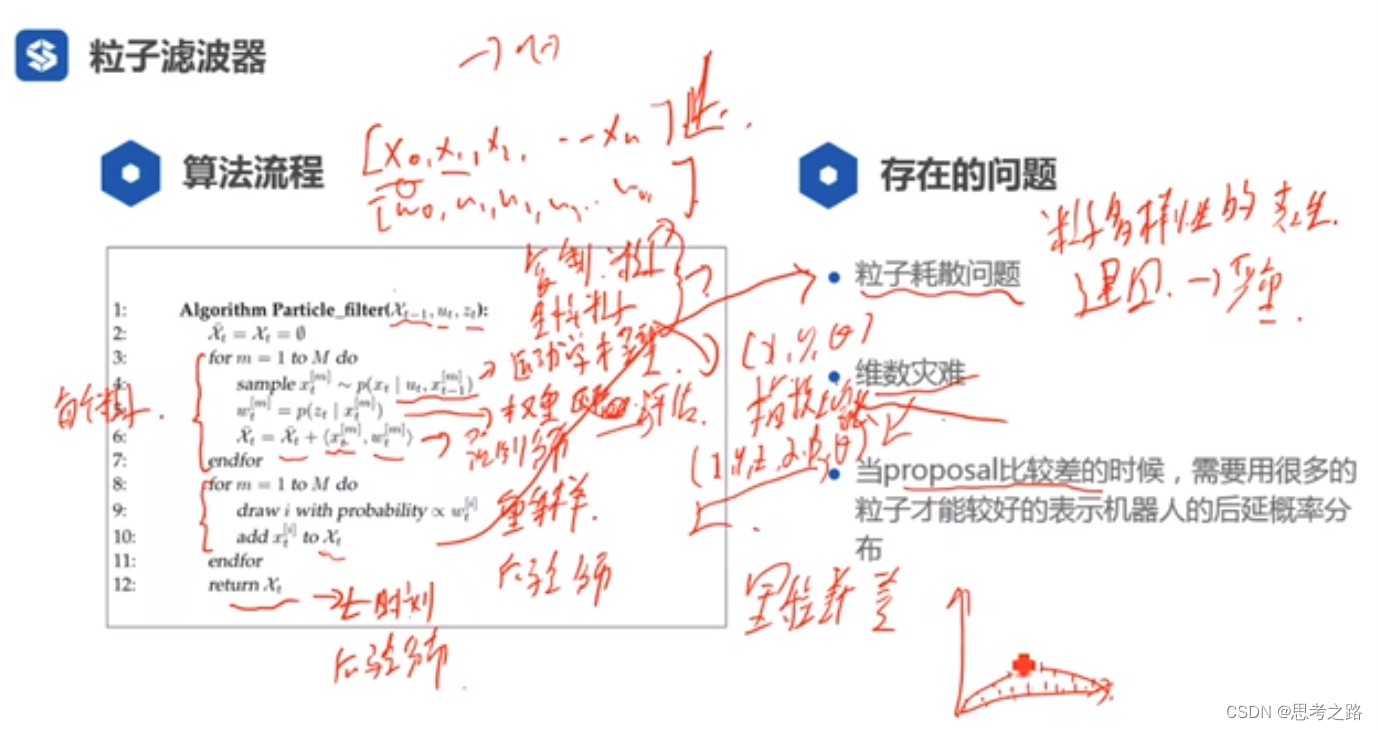
用i个粒子进行状态传播,然后通过观测来评估每个粒子的权重,最后通过重采样进行机器人位值概率的校正,即粒子的重新分布(去除低权重的粒子,高权重的地方多撒些粒子)。
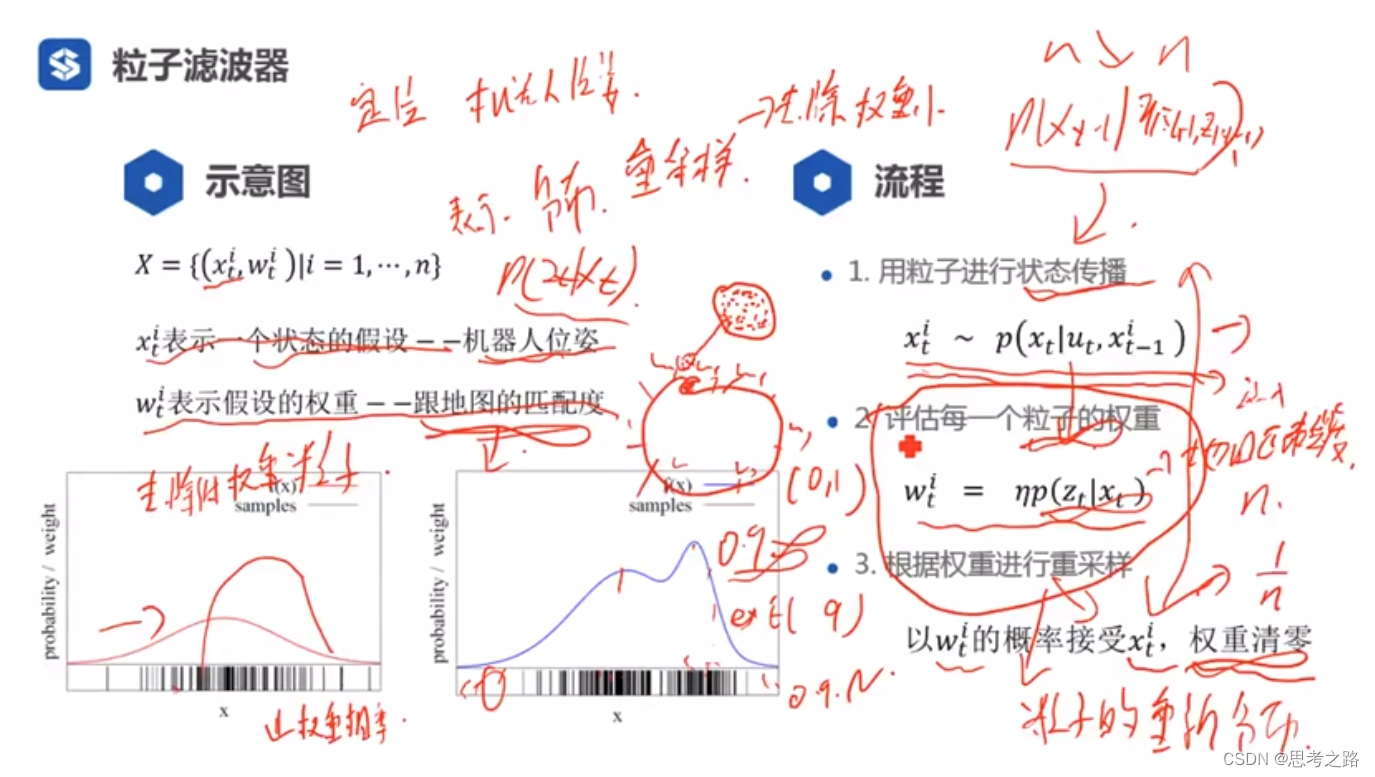
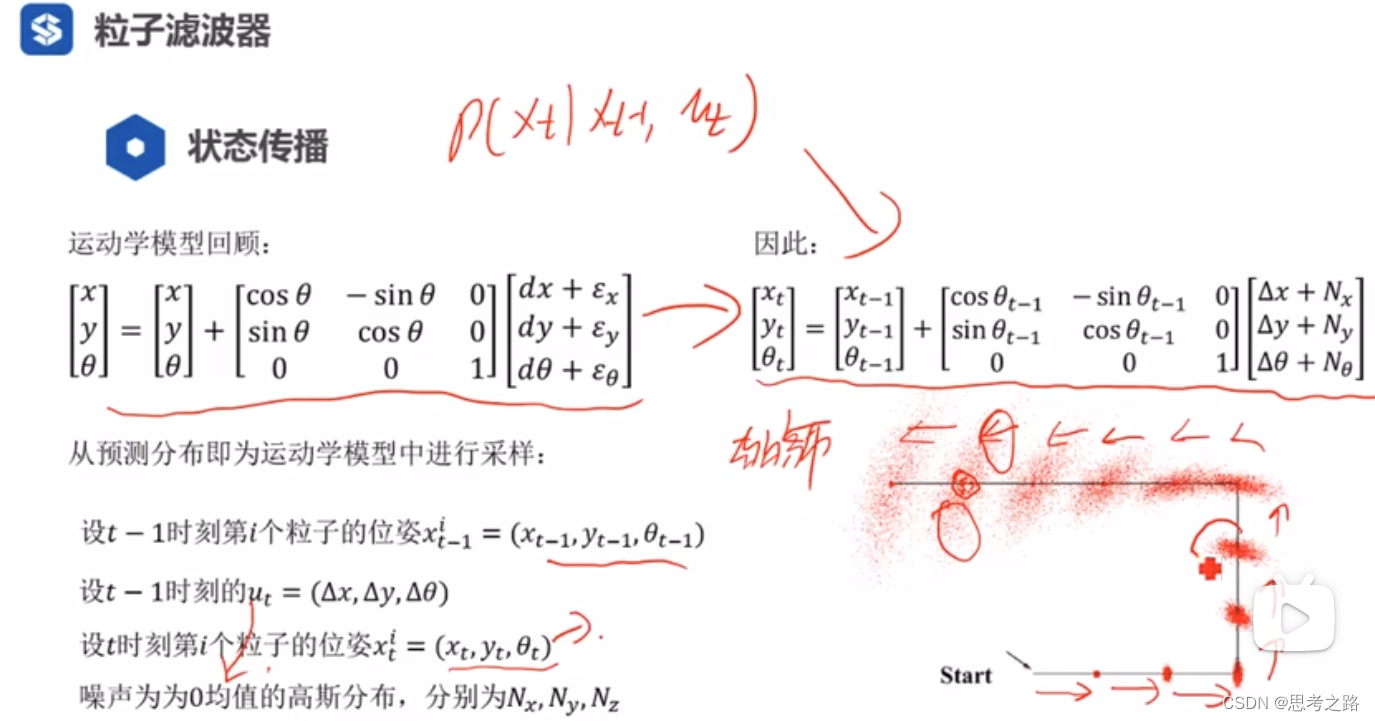
传播模型:已知t-1时刻的分布,通过传播模型(运动模型)进行传播得到预测的t时刻的概率分布。在没有观测模型的情况下,通过传播模型每个粒子越传,扩散的越大,最终趋于均匀分布,通过评估粒子的权重(观测),根据权重进行重采样,将权重小的地方的粒子去除,权重大的地方的粒子进行复制,此时粒子的状态传播图由聚集转为扩散又转为聚集(粒子团)。


权重w:实际分布和预测分布的差别,区别越大权重越小,区别越小权重越大(说明我的预测分布能很好的反映实际分布,我们的粒子是从预测分布进行采样的,要用的实际上是实际分布,实际分布又不知道,但预测分布与实际分布的差我们我们可以知道(观测模型)。
每一次重采样之后,都会进行权重更新,权重归一化,都相等(1/N)。
不重采样的原因:粒子耗散问题。
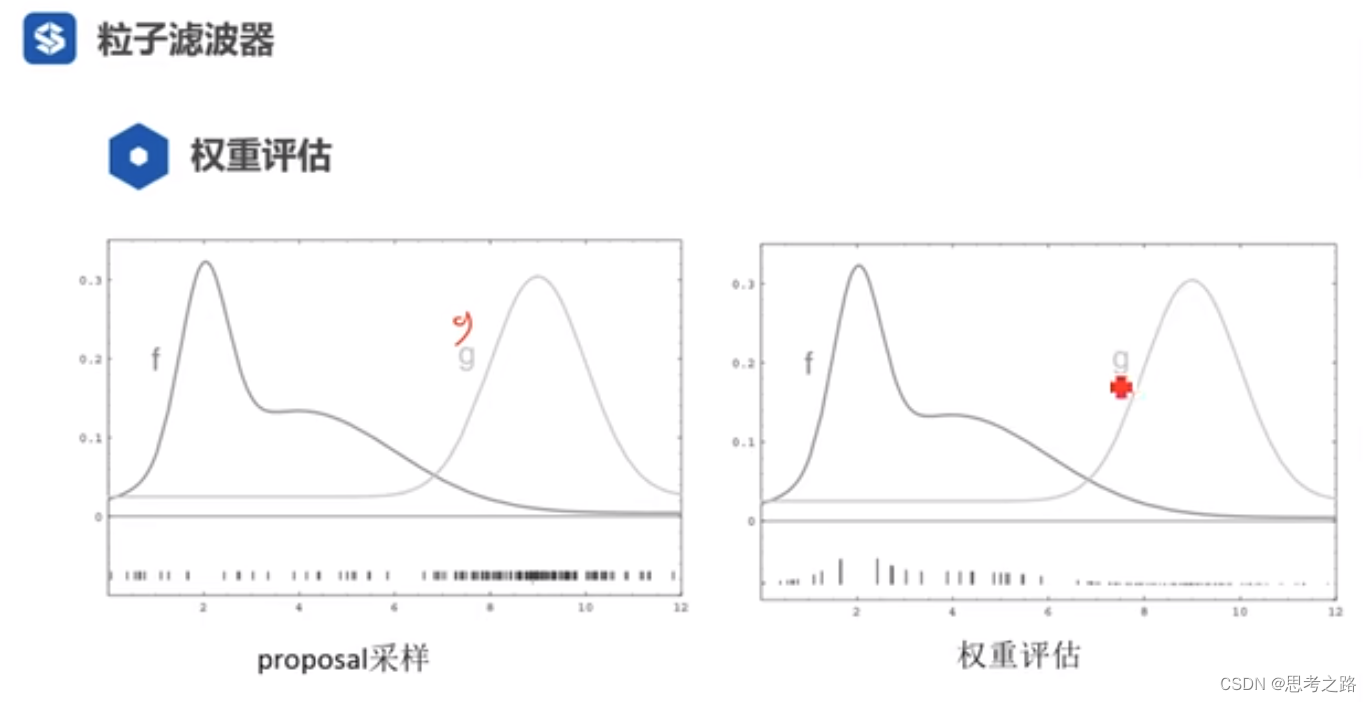
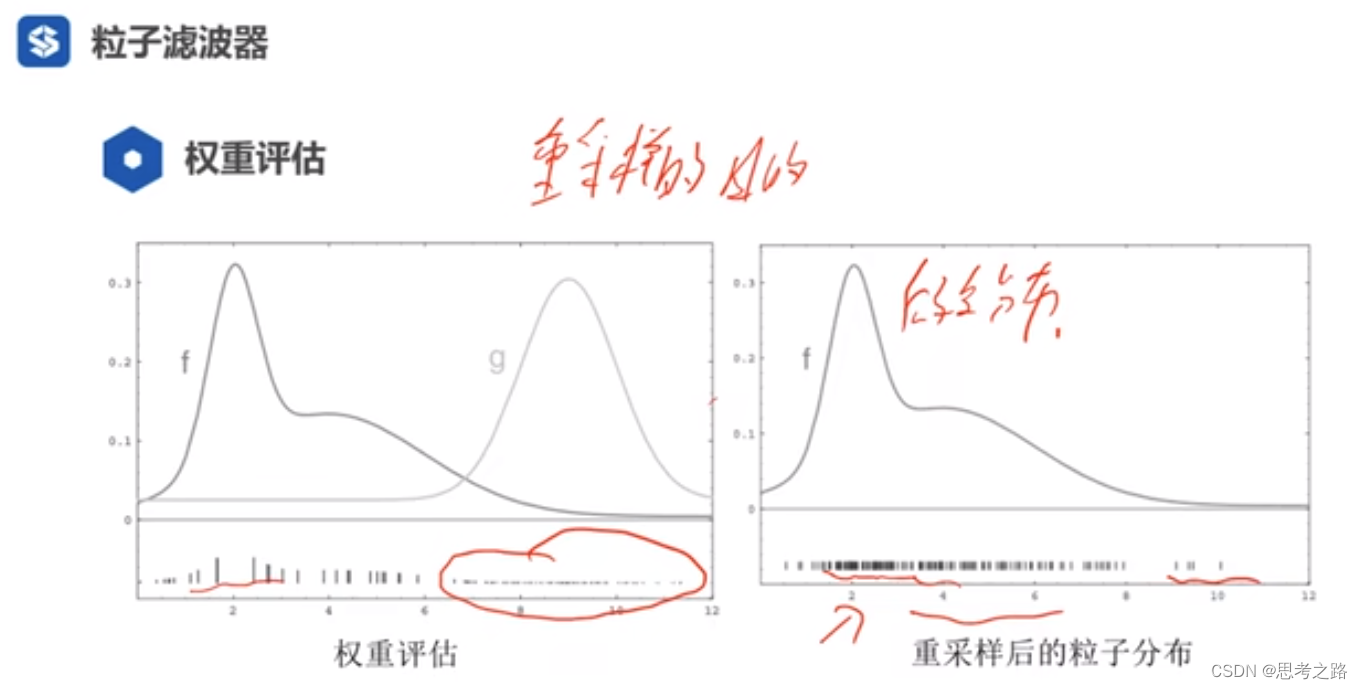
g 表示proposal分布(用粒子群来表示分布),权重评估是实际分布与预测分布的比值,横坐标相同时f(后验分布)与g(先验分布)的比值符合右图。由右图可以看出权重评估的分布和f的分布很像,不是粒子的密度,而是峰值,即权重的大小反映了后验概率分布。
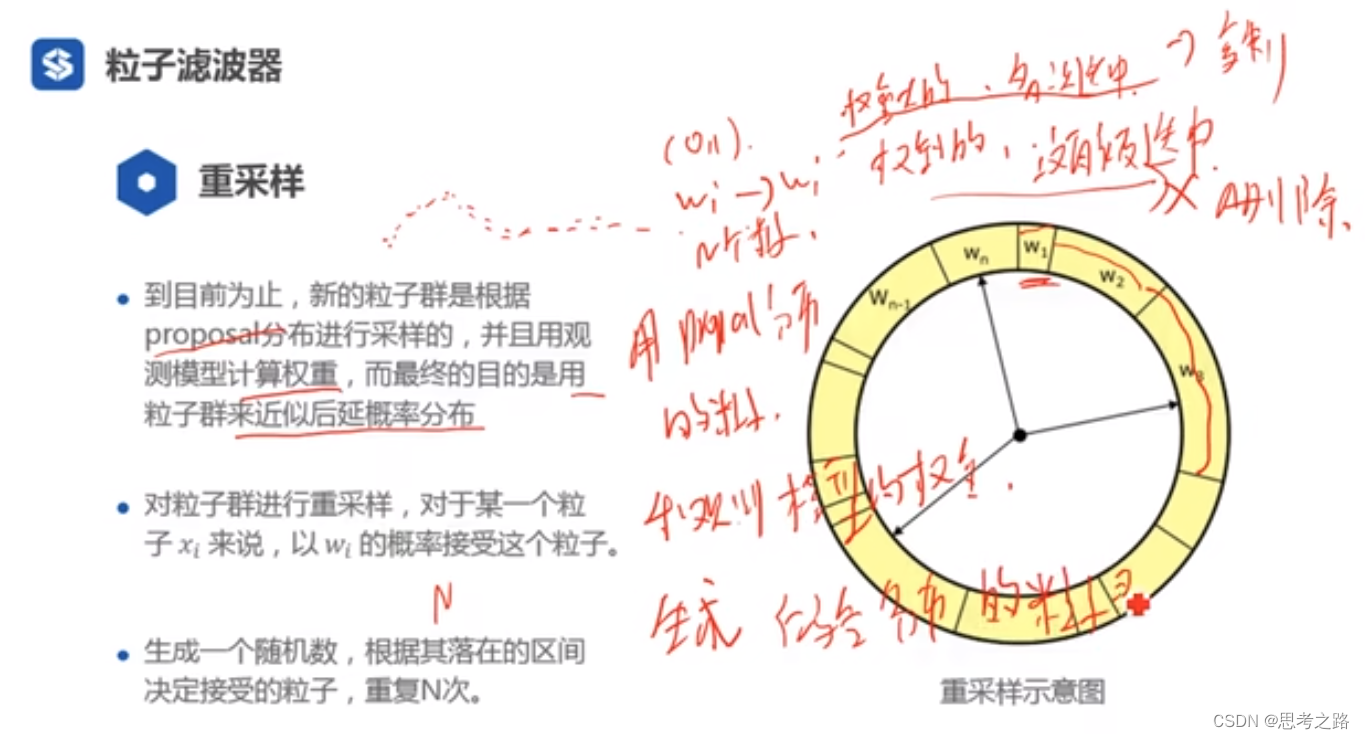
重采样:用proposal分布的粒子和观测模型的权重生成符合我们后验概率的粒子群(用粒子来表示分布,权重大的地方粒子多)。目的:让粒子的分布更符合我们的后验分布
总结:粒子滤波和贝叶斯率波都是为了估计机器人的状态。
粒子耗散:粒子多样性的丧失,在建图中是致命的,而粒子多样性的丧失是由重采样造成的,重采样是有一定的概率的,假设每个粒子的权重都相同,然后一直进行重采样,每次重采样都有粒子会被丢掉,粒子会被复制,当采样趋于很大的时候,所有的粒子都由同一个粒子复制而来,重采样的过程是复制好粒子,丢掉差粒子,粒子数不变。这个问题对定位来说不是问题但是对于建图来说是灾难性的,这就是Gmapping对环境大的地方建图效果差的原因。
维度灾难:对于平面上运动,三维x, y ,
t
h
e
t
a
theta
theta就可以,六维的话,要覆盖的粒子会特别多,复制的粒子会呈指数形增长,所以视觉估计里面就用不到粒子滤波,因为视觉估计中的维数高。
当proposal比较差的时候,即里程计差,此时的里程计模型就是个扁平的模型,我们要覆盖这个模型的话(对改模型有个好的分布),需要很多粒子,所以我们需要尽可能优化proposal分布,若分布不是扁平,此时需要几个粒子来表示该分布,这是粒子滤波优化的方向。

u1:t 和z1:t是传感器数据



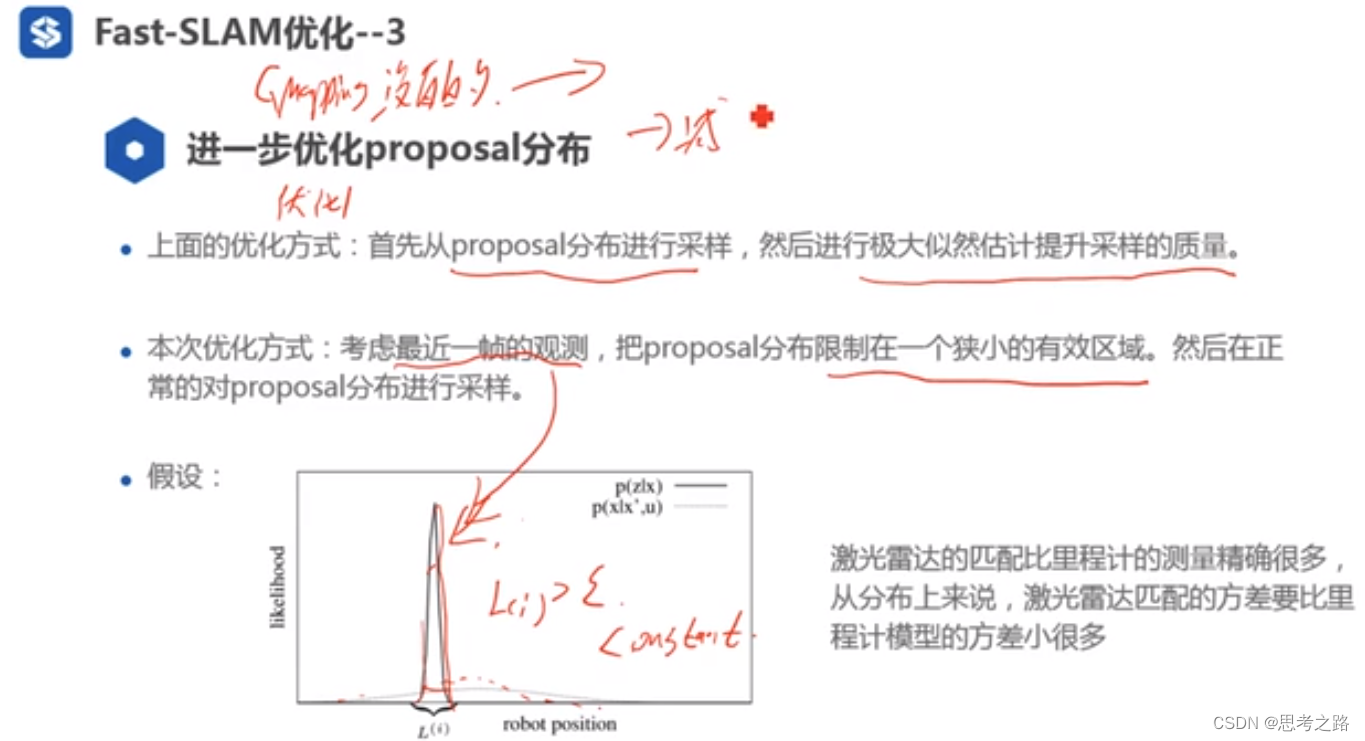
当propsal分布比较差时,先对得到的预测分布进行采样然后用scan-matching优化位姿,得到更优的位姿。

以下的对proposal的优化是Gmapping没有的,通过最近一帧的观测将proposal分布限制在一个狭小的区域,然后对该分布进行采样,其是也是为了减小粒子数来表示该分布,较差的proposal分布需要很多的粒子来表示该分布,当proposal分布限制在小区域范围时,所需的粒子也会减少




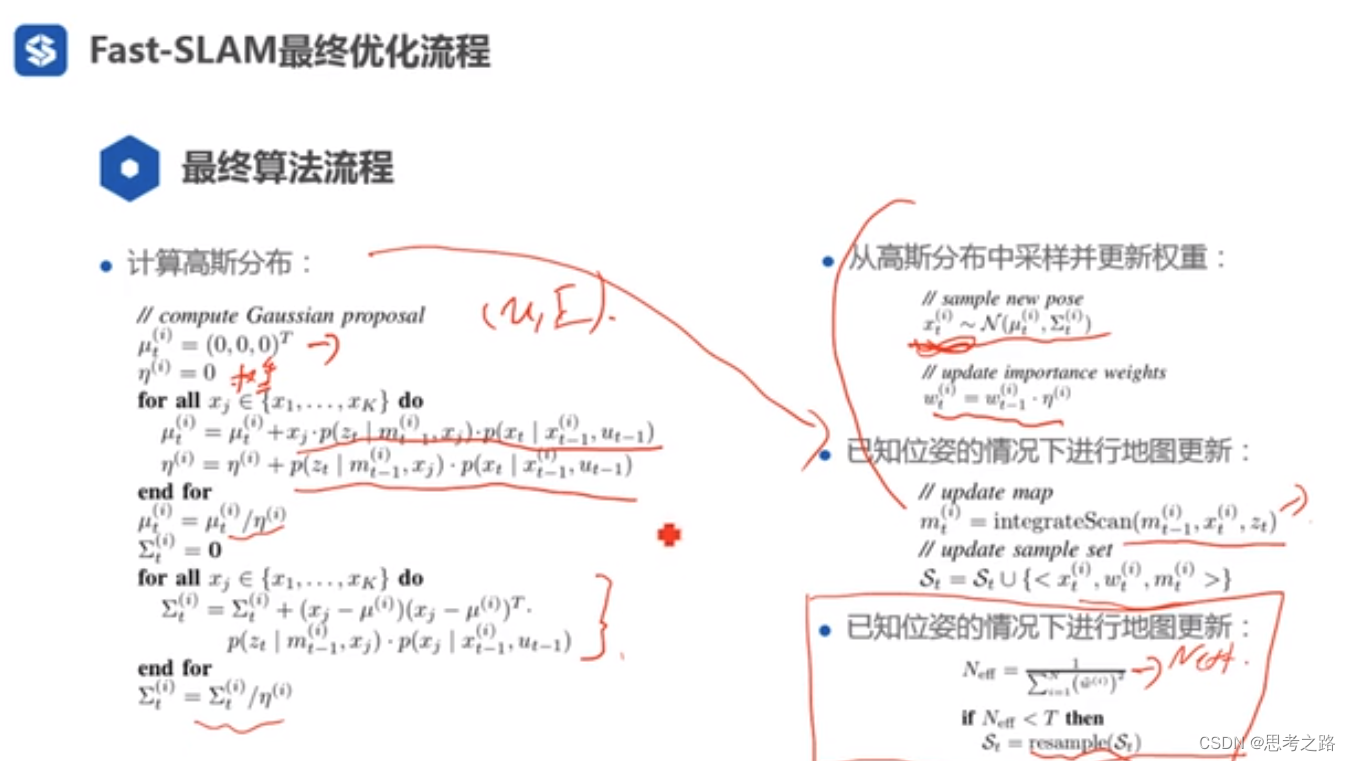



Gmapping代码解读: