不同编码格式(Unicode、多字节字符)vs环境下使用printf、scanf应注意事项
事件起因:
因需要格式化一个字符串,格式化字符串的方式方法很多,特别在MFC环境下,有CString的Format,有sprintf等,由于我们需要使用安全版本,所以选择了sprintf_s,本次由于是使用dll模块,所以新建了一个mfc测试程序测试我们的sprintf_s,测试通过后,再修改到dll模块里,然后将模块发送出去,结果客户方说不行,调了1个来小时,发现是编码格式问题。
解决方案:
由于客户运行环境是Unicode环境,所以应该使用swprintf_s函数来代替。
一般多字节环境我们平时使用较多,比较熟悉,这里不做介绍,这里主要介绍下在Unicode环境下使用printf和scanf函数。
一、_stprintf_s
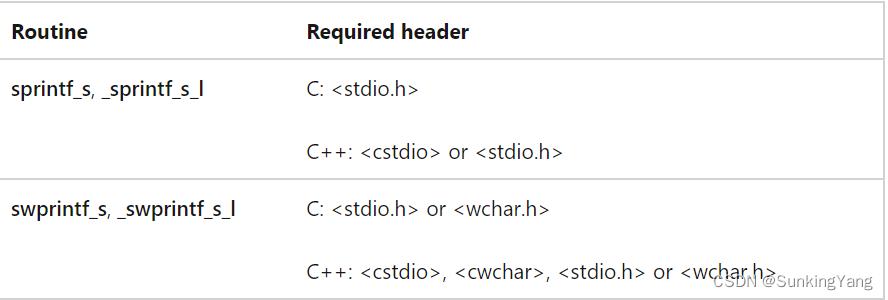
- 需要头文件:<TCHAR.H>
- MSDN上对_stprintf_s函数的定义如图:

头文件:
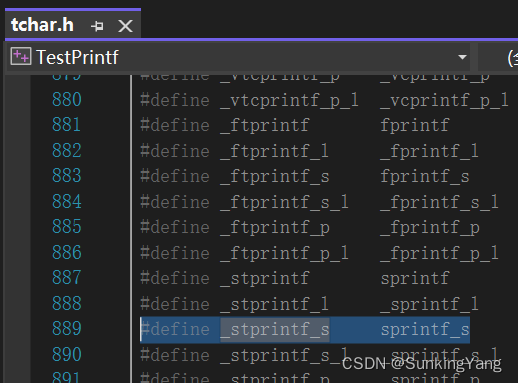
对应头文件里代码为:
#ifdef UNICODE
#define _stprintf_s swprintf_s
#else
#define _stprintf_s sprintf_s
其中:
- 前面的t表示编码,后面的_s表示检查内存溢出,前面的_表示非标准库函数。
- 从上我们可以看出,_stprintf _s和_stscanf_s是为适应不同编码而定义的两个宏,在不同的编码环境下他们所表示的函数是不同的。
- _s是security 的意思,具体含义参见后面的Security Remarks部分。
//ANSI 版本
int sprintf_s( char *buffer, size_t sizeOfBuffer, const char*format [, argument] ...);
//UNICODE版本
int swprintf _s(wchar_t *buffer, size_t sizeOfBuffer, const wchar_t *format[,argument]J..);
这个函数的主要作用是将若干个argument按照format格式存到buffer 中。
- buffer:输出的字符
- sizeOfBuffer: buffer 的长度,以能存放的字符数计算,而不是已占用的字节数计算。这很重要。一个UNICODE字符占用2个字节。
- format:格式字符串,比如%s
- argument:可选参数
二、_stscanf_s
对应头文件里代码为:
#ifdef UNICODE
#define _stscanf_s swscanf_s
#else
#define _stscanf_s sscanf_s
//ANSI 版本
int sscanf_s( const char *buffer, const char*format [, argument ] ... );
//UNICODE版本
int swscanf_s( const wchar_t *buffer, const wchar_t *format [, argument ] ...);
这个函数的主要作用是从 buffer 中读取指定格式( format)的字符到相应的argument 中。参数同上。
几个需要注意的细节:
- 为了让编译器识别Unicode字符串,必须以在前面加一个“L”,定义宽字节类型方法如下:L“ABC”,表示字符串“ABC”是用UNICODE编码的。
- char与 wchar t的区别: char中存放的是单字节型的字符,wchar_t中存放的是双字节型的字符,TCHAR在定义了_UNICODE时等同于wchar_t,在未定义
_UNICODE时等同于char。
总结:
在我们使用过程中,尽量使用宏定义函数,而不用收编码环境影响。