跳表论文解读
跳表出现背景:
利用二叉树可以表示各种抽象数据类型,比如字典(TreeMap)和有序列表.当元素是随机插入时,这种数据结构可以拥有很好的性能.但当元素是大量顺序插入时,这种数据结构会退化为线性时间复杂度.解决这种问题的一种方法是打乱元素顺序,但这样做在要求快速响应的场景下十分吃力.因此出现了平衡树的概念,平衡树通过不断平衡左右子树的高度来确保优秀的性能.而跳表,可以作为一种基于概率的平衡树的替代品,并且它拥有更简单的操作
跳表的实现思路:
考虑一种有序链表:
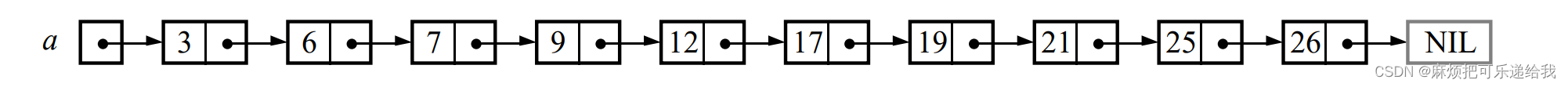
在这样一个链表中查找元素的时间复杂度为O(n).然而,当我们每两个节点都有额外加上的一个指针,这个指针指向它前面两个节点处的位置,即

那么在这样一条链表上查找元素的时间复杂度为O(n/2+1)
如果每四个节点都有一个指向前面四个节点处位置的指针,那么查找的时间复杂度将降低为O(n/4+2)

.以此类推,如果每2i个节点都有一个指向前面2i位置的指针,如下图,每个(20)节点都有指向前面一个节点的指针(图中所有节点都有),每2个(21)节点都有指向前面两个位置处的指针(图中6,9,17,21,26节点有),每4(22)个节点都有指向前面四个位置处的指针(图中9,21节点有),每8(23)个节点都有指向前面八个位置处的指针(图中21节点有)

那么在这种链表中查找元素的时间复杂度为O(log2 n),一个拥有k个指针的节点被定义为k级节点,在这种数据结构中,50%节点 是level 1, 25% 节点是 level 2, 12.5%节点是level 3…但是,如果数据结构仅仅被设计成这样,进行查找是没有任何问题的,但进行插入和删除将变得不可实践.怎么解决这个问题呢?如果我们允许每个节点的level可以被随机选择,但是比例不变,会发生什么?那么,就有可能出现下面这种情况

降低了限制因素后(每个节点的level是固定的),插入和删除变得可行
跳表查找,插入,删除的具体实现
跳表的最大level被限制为小于MaxLevel这个常量,这个常量根据不同的数据量可以自由配置.而跳表的level等于此时跳表的最大level,比如一开始跳表的level是1.
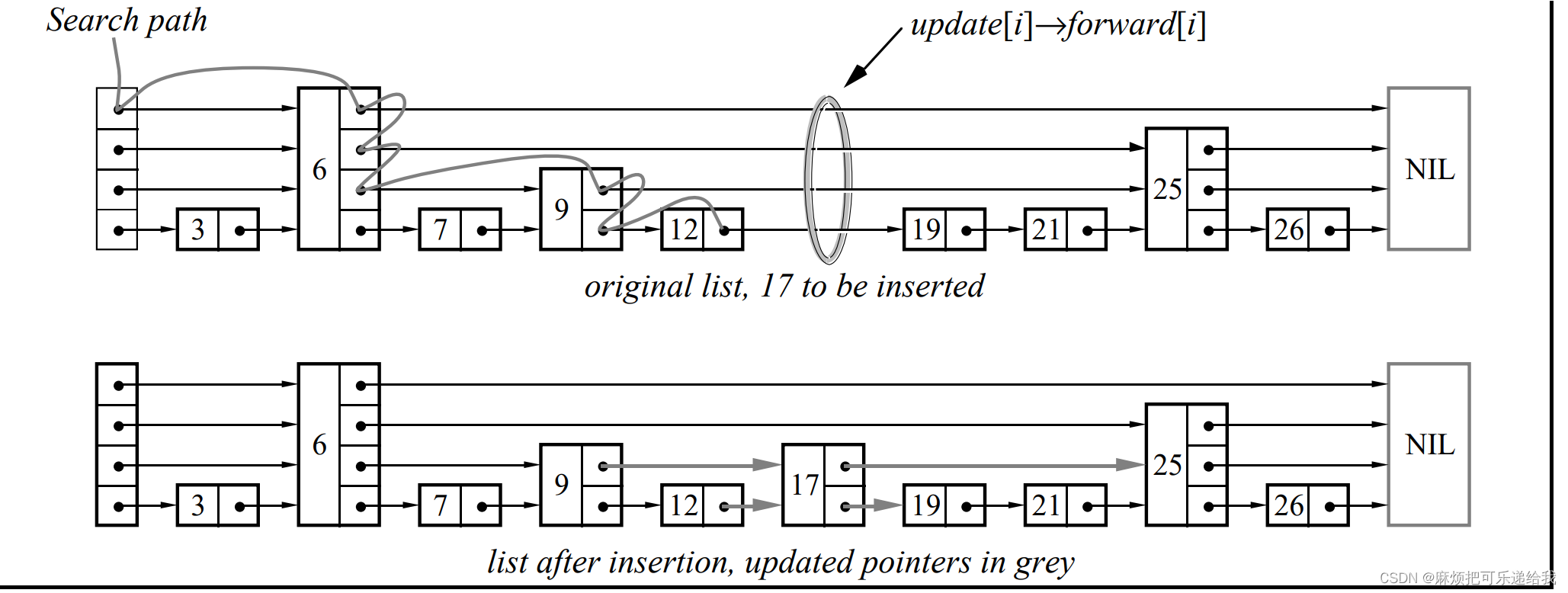
首先是查找,我们通过遍历向前的指针来查找元素,指针指向的元素不能超出要搜索的元素。一旦当前指针无法取得更多进展时,搜索将向下移动一个级别。当我们无法在level 1上取得更多进展时,下一个节点必须就是要查找的节点(如果那个节点存在).下图为查找元素17所应该出现的位置

查找伪代码

插入和删除的操作与查找刚开始的步骤一致,只不过在查找的过程中需要维护一个update数组,这个数组的含义为:update[i]是在待插入/删除位置左边的所有level i节点中最右边的一个.一旦完成查找,就会对update[i]进行更新.下图展示了节点指针的更新
插入和删除伪代码

当我们插入一个节点时,会随机指派它的level,指派的方法为
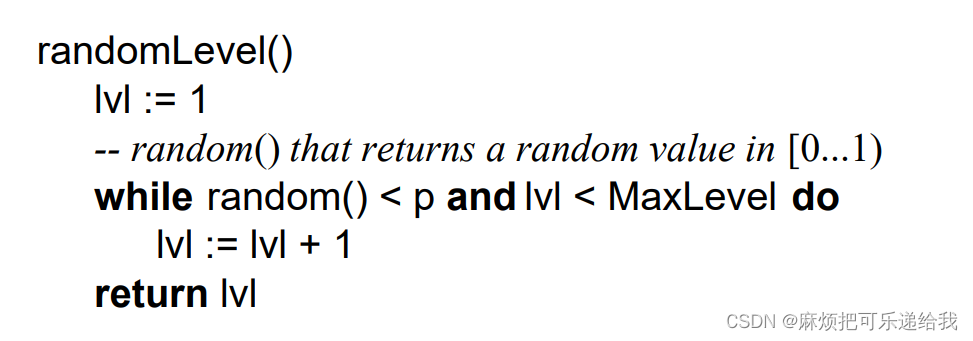
p是一个分布因子,我们讨论的链表的p = 0.5
由于本篇只对跳表概念,原理进行入门讲解,关于p的设定和后序如何挑选search最佳开始的level,以及MaxLevel的选择, 请参考论文 Skip Lists: A Probabilistic Alternative to Balanced Trees