微服务 高可用
隔离
隔离:本质上是对系统或资源进行分割,从而实现当系统发生故障时能限定传播范围和影响范围,即当发生故障后只有出问题的服务不可用,保证其他服务仍然可用。
服务隔离
- 动静分离,读写分离
轻重隔离 - 核心,快慢,热点
物理隔离 - 线程,进程,集群,机房
隔离 - 服务隔离
动静隔离:
小到CPU的cacheline false sharing,数据库 mysql表设计避免bufferpool 频繁过期,隔离动静表(我们一般设计两张表,一张表经常更新,一张表不怎么更新,避免将这两张表放在一起),大到架构设计中的图片,静态资源等缓存加速。本质上都体现一种思想,即加速/缓存访问量变化小的。比如 CDN场景中,将静态资源和动态API分离,也是体现了隔离的思路。
mysql buffer pool 是用于缓存dataPage 的,dataPage 可以理解为缓存了表的行,那么如果频繁更新dataPage ,那么会因为LRU算法会发生不断的置换操作,会导致命中率下降,所以我们在表设计中,仍然可以沿用类似的思路,其主表基本更新,在上游cache未命中,透穿到mysql中,仍然有bufferpool缓存。
- 读写分离:主从
核心隔离:
业务按照Level进行资源池划分(L0/L1/L2)
- 核心/非核心的故障域的差异隔离(机器资源,依赖资源)
- 多集群,通过冗余资源来提升吞吐和容灾能力
热点隔离:
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的top k 数据,并对访问进行缓存。比如:
- 小表广播:从 remotecache(redis) 提升为 localcache, app 定时更新,甚至可以让运营平台支持广播刷新localcahce,同时使用cop技术,atomic.value
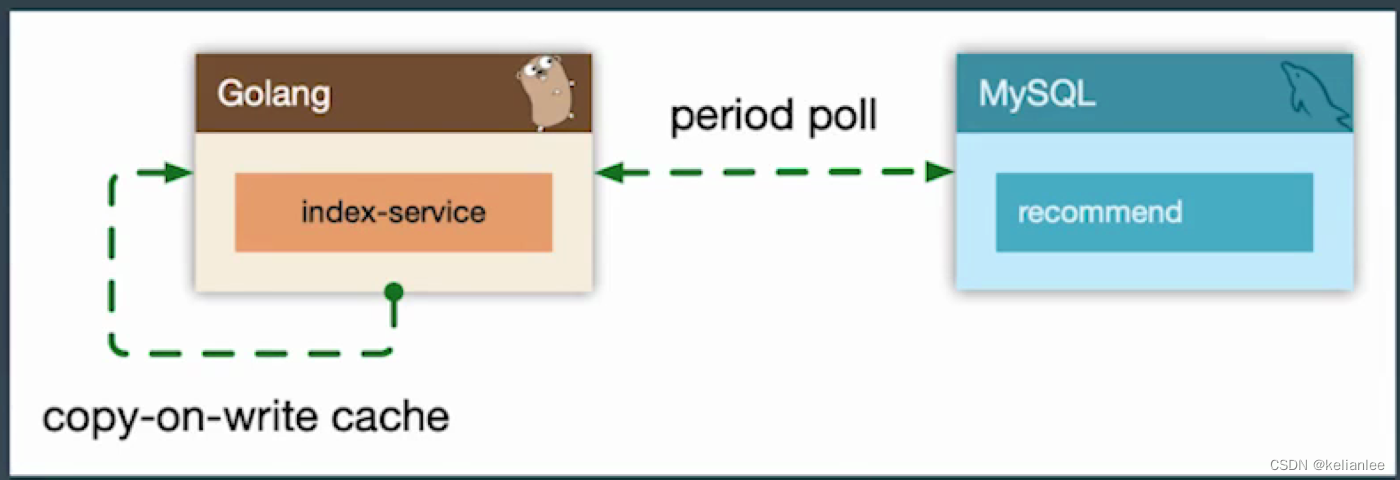
- 主动预热:比如直播房间页高在线情况下 bypass 监控主动防御
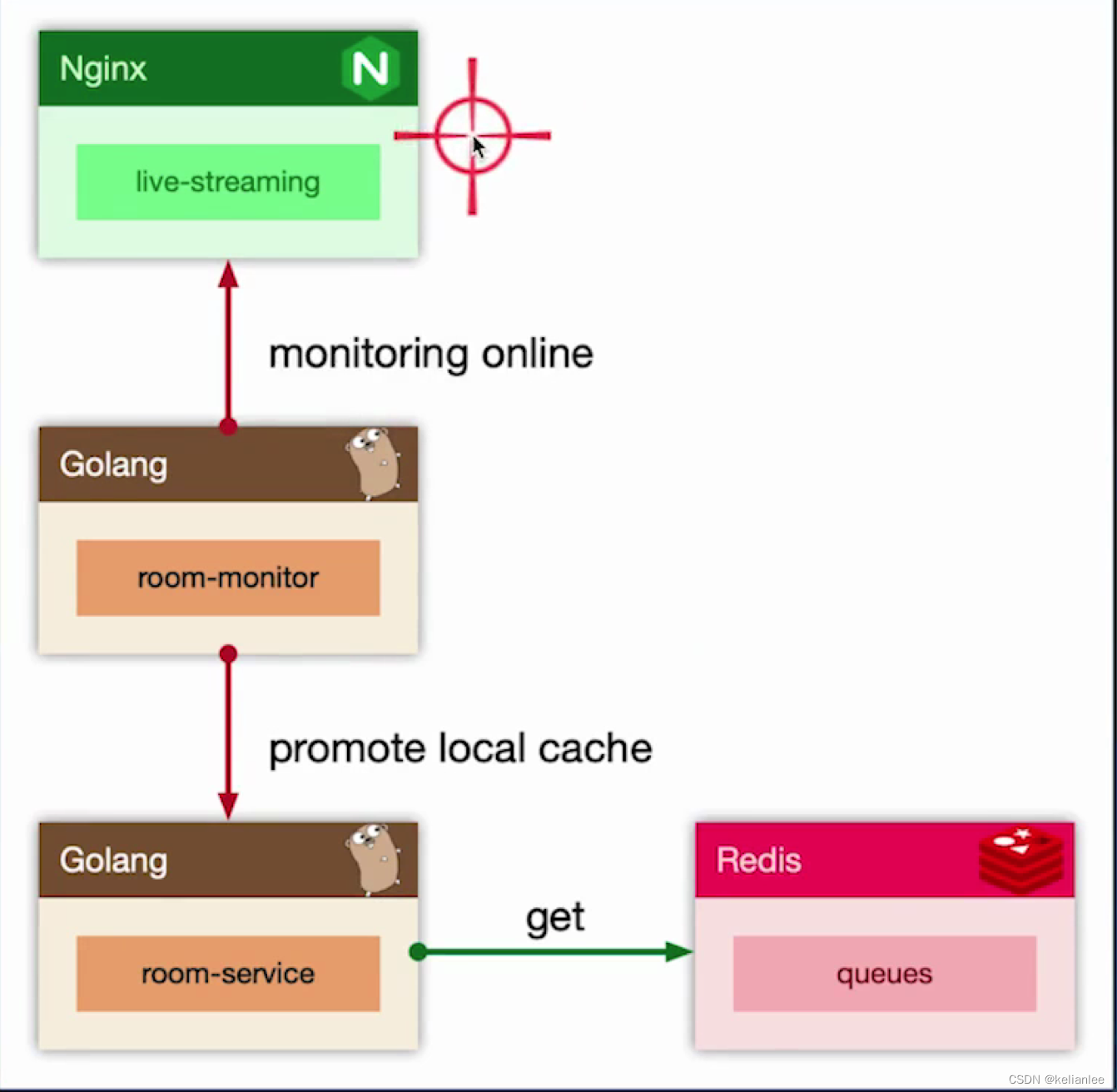
假设直播房间高在线,高刷新的情况下怎么处理?如上图我们通过 room-monitor 服务来监控房间人数,一旦人数达到一个阈值(5w),我们就通知room-service 将 remotecache 升级为 localcache,我们会先访问localcache,如果localcahce未命中,再访问redis。我们将房间信息缓存到localcache中,这样用户在疯狂刷新的时候,就能命中。这是一种旁路监控,找到热点房间,主动广播的思路。更好的办法是进程级别的,
隔离 - case study
- 早期转码集群被超大视频攻击,导致转码大量延迟。
可以采用,将视频集群进行隔离,超大视频用a集群,大视频用b集群,小视频用c集群。这样只会阻塞a集群。将全局故障,转变为局部故障。
超时
超时控制
超时控制,我们的组件能够快速失效(fail fast),因为我们不希望等到断开的实例直到超时。没有什么比挂起的请求和无响应的界面更令人失望。
超时控制是微服务可用性的第一道关,良好的超时策略,可用尽可能让服务不堆积请求,尽快清空高延迟的请求,释放goroutine,一秒钟法则:pc 互联网必须一秒钟返回。
过载保护和限流
过载保护
- 令牌桶算法
- 漏桶算法
漏斗桶/令牌桶确实能够保护系统不被拖垮,但不管漏斗桶还是令牌桶,其防护思路都是设定一个指标,当超过该指标后就阻止或减少流量继续进入,当系统负载降低到某一水平后则恢复流量的进入。但其实通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情。
- 集群增加机器或者减少机器限流阈值是否要重新设置?
- 设置限流阈值的依据是什么?
- 人力维护成本是否过高?
- 当重新设置限流,其流量高峰已经过了重新评估限流是否有意义?
这些其实都是采用漏斗桶/令牌桶的缺点,总体来说就是太被动,不能快速适应流量变化。因此我们需要一种自适应的限流算法,即:过载保护,根据系统当前的负载自动丢弃流量。
???
限流
限流是指在一段时间内,定义某个客户或应用可用接收或处理多少个请求的技术。例如,通过限流,你可以过滤掉产生流量峰值的客户和微服务,或者可以确保你的应用程序自动扩展(auto scaling)失效前不会出现过载的情况。
- 令牌桶,漏桶 针对单个节点,无法分布式限流
- QPS限流:1.不同的请求可能需要数量迥异的资源来处理。2.某种静态QPS限流不是特别准
- 给每个租户设置限制:1.全局过载发生的时候,针对某些"异常"进行控制。2. 一定程度的“超卖”配额。
- 按照优先级丢弃
- 拒绝请求也需要成本。
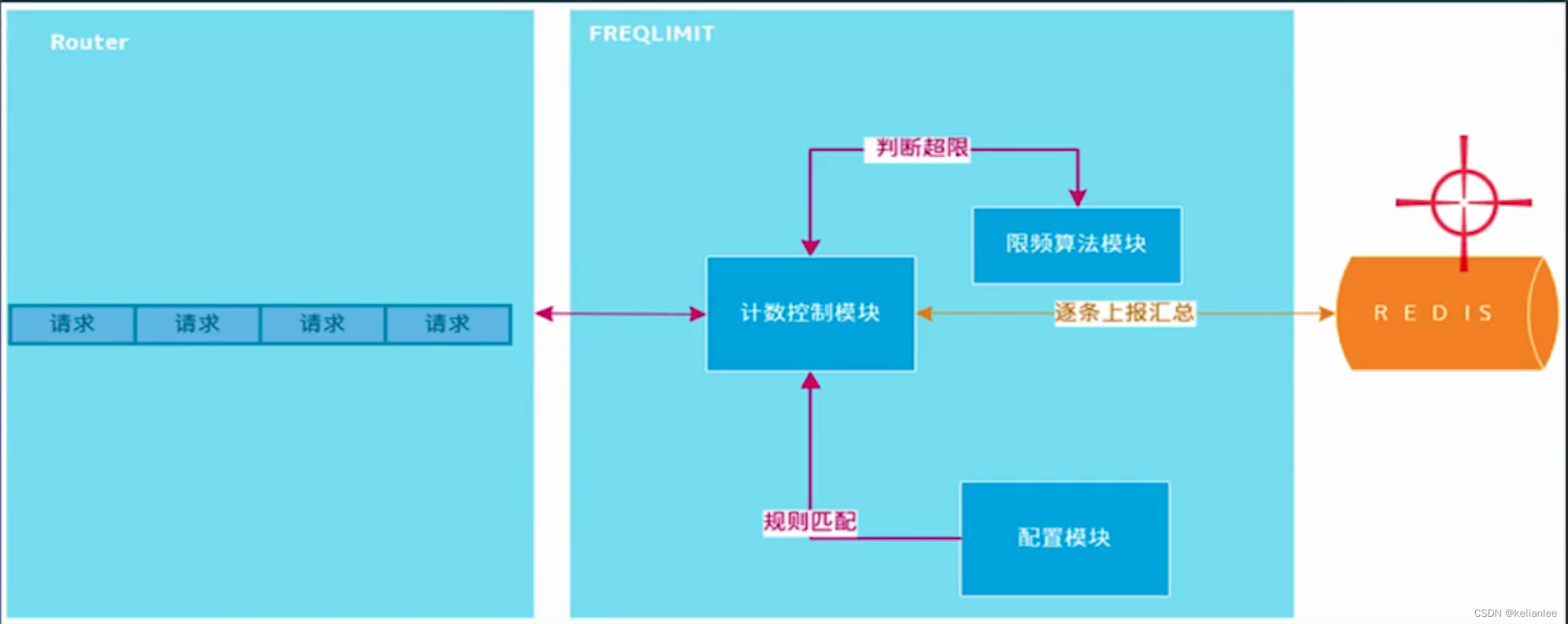
限流 - 分布式限流
分布式限流,是为了控制某个应用全局的流量,而非真对单个节点维度。
一般采用redis,来一个请求,就将对应的key+1, 但是这样会有缺点:
- 单个大流量的接口,使用redis容易产生热点。如果有10w QPS,那么这个流量就会打到redis上。
- 像这种 pre-request 模式对性能有一定影响,高频的网络往返。
限流 - 熔断
熔断是从client侧做保护。直接不请求下游。他是对下游做保护的,即对server做保护。
- 服务依赖的资源出现大量错误。
- 某个用户超过资源配额的时候,后端任务会快速拒绝请求,返回"配额不足"的错误,但是拒绝回复仍然会消耗一定的资源。有可能后端忙着不停发送拒绝请求导致过载。
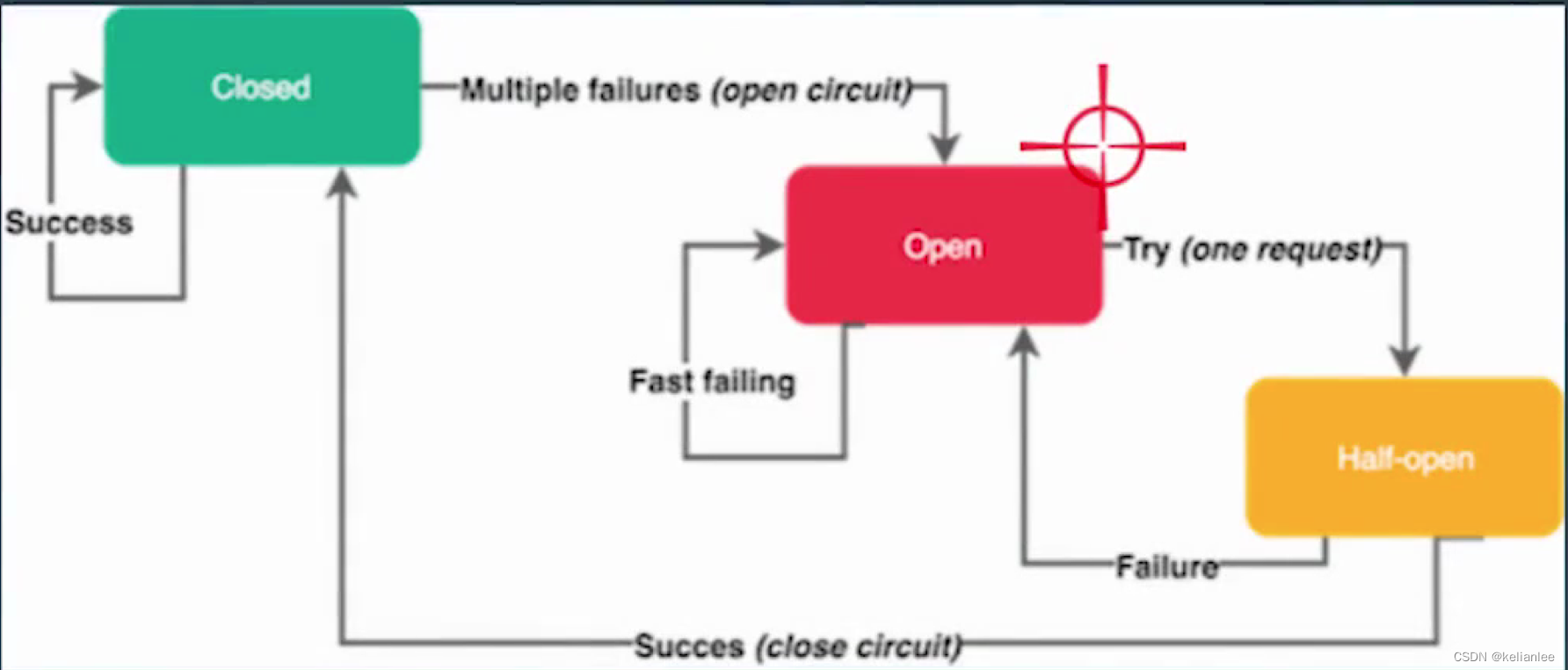
如上图所示,熔断刚开始是closed的,这时候请求会成功发送到下游,当下游的服务发生过多的错误的时候,我们会开启熔断,这时候请求进入fast failing状态,直接失败,但是我们会放一个请求去尝试请求下游看看是否恢复。
降级重试
通过降级回复来减少工作量,或者丢弃不重要的请求。而且需要了解哪些流量可以降级,并且有能力区分不同的请求。我们通常提供降低回复的质量来答复减少所需的计算量或者时间。我们自动降级通常需要考虑几个点:
- 确定具体采用哪个指标作为流量评估和优雅降级的决定性指标(cpu,延迟,队列长度,线程数量,错误等)
- 当服务进入降级模式时,需要执行什么动作
- 流量抛弃或者优雅降级应该在服务的哪一层实现?是否需要在整个服务的每一层都实现,还是可以选择某个高层面的关键节点来实现?
同时我们要考虑以下几个点: - 优雅降级不应该被经常触发
- 演练,代码平时不会触发和使用,需要定期针对一小部分的流量进行演练,保证模式的正常
- 应该足够简单