分位数回归的求解
分位数回归实际上是一种特殊的 ℓ 1 \ell_1 ℓ1回归问题,特别地,当所求分位数 τ = 0.5 \tau=0.5 τ=0.5时就是中位数回归。
将分位数回归看做是线性规划问题来求解
一般的,线性回归问题可以写为
ℓ
p
\ell_p
ℓp范数线性回归,简称为
ℓ
p
\ell_p
ℓp回归:
arg min
x
∈
R
n
∣
∣
A
x
−
b
∣
∣
p
\argmin_{x\in\mathbb{R}^n}||\boldsymbol{A}\boldsymbol{x}-\boldsymbol{b}||_p
x∈Rnargmin∣∣Ax−b∣∣p
其中
A
∈
R
m
×
n
,
b
∈
R
m
\boldsymbol{A}\in\mathbb{R}^{m\times n}, b\in\mathbb{R}^m
A∈Rm×n,b∈Rm,
∣
∣
v
∣
∣
p
=
(
∑
i
∣
v
i
∣
p
)
1
/
p
||v||_p=(\sum_i|\boldsymbol{v}_i|^p)^{1/p}
∣∣v∣∣p=(∑i∣vi∣p)1/p表示
ℓ
p
\ell_p
ℓp范数
那么从中位数回归的角度来看,损失函数就是绝对损失(
p
=
1
p=1
p=1):
arg min
x
∈
R
n
∣
∣
A
x
−
b
∣
∣
\argmin_{x\in\mathbb{R}^n}||\boldsymbol{A}\boldsymbol{x}-\boldsymbol{b}||
x∈Rnargmin∣∣Ax−b∣∣
考虑一个两参数的分位数回归优化问题
β
^
=
arg min
(
b
0
,
b
1
)
∈
R
2
{
∑
i
=
1
n
∣
y
i
−
b
0
−
b
1
x
i
∣
}
\begin{equation} \hat{\beta}=\argmin_{(b_0,b_1)\in \mathbb{R}^2}\left\{ \sum_{i=1}^n|y_i-b_0-b_1x_i|\right\} \end{equation}
β^=(b0,b1)∈R2argmin{i=1∑n∣yi−b0−b1xi∣}
τ
\tau
τ分位数时更一般的形式
β
^
(
τ
)
=
arg min
b
∈
R
m
×
n
∑
i
=
1
n
ρ
τ
(
y
i
−
x
i
⊤
b
)
\hat{\beta}(\tau)=\argmin_{\mathbf{b}\in\mathbb{R}^{m\times n}}\sum_{i=1}^n\rho_{\tau}(y_i-\boldsymbol{x}_i^{\top}\mathbf{b})
β^(τ)=b∈Rm×nargmini=1∑nρτ(yi−xi⊤b)
其中
τ
∈
(
0
,
1
)
\tau\in(0,1)
τ∈(0,1)是分位数.
ρ
τ
(
⋅
)
\rho_{\tau}(\cdot)
ρτ(⋅)是check function(又称检查函数):
ρ
τ
(
u
)
=
u
(
τ
−
I
(
u
<
0
)
)
\rho_{\tau}(u) = u(\tau-I(u<0))
ρτ(u)=u(τ−I(u<0))
定义
ε
i
=
y
i
−
x
i
⊤
b
\varepsilon_i=y_i-\boldsymbol{x}_i^{\top}\mathbf{b}
εi=yi−xi⊤b为第
i
i
i个残差,则优化目标
(
1
)
(1)
(1)可以转化为残差的形式
β
^
=
arg min
(
b
0
,
b
1
)
∈
R
2
{
∑
i
=
1
n
ε
i
}
\begin{equation} \hat{\beta}=\argmin_{(b_0,b_1)\in \mathbb{R}^2}\left\{ \sum_{i=1}^n \varepsilon_i \right\} \end{equation}
β^=(b0,b1)∈R2argmin{i=1∑nεi}
将上式改写:
∑
i
=
1
n
ρ
τ
(
ε
i
)
=
∑
i
=
1
n
τ
ε
i
+
+
(
1
−
τ
)
∣
ε
i
−
∣
\begin{equation} \sum_{i=1}^n\rho_{\tau}(\varepsilon{_i})=\sum_{i=1}^ n\tau\varepsilon_{i}^{+} + (1-\tau)|\varepsilon_i^{-}| \end{equation}
i=1∑nρτ(εi)=i=1∑nτεi++(1−τ)∣εi−∣
由于分位数回归使用的是绝对损失函数,残差恒正,所以将其拆分为正部
ε
i
+
=
u
i
=
ε
i
I
(
y
i
−
x
i
⊤
b
>
0
)
,
ε
i
−
=
v
i
=
ε
i
I
(
y
i
−
x
i
⊤
b
<
0
)
\varepsilon_{i}^{+} = u_i=\varepsilon_i I(y_i-\boldsymbol{x}_i^{\top}\mathbf{b}>0),\varepsilon_{i}^-=v_i=\varepsilon_i I(y_i-\boldsymbol{x}_i^{\top}\mathbf{b}<0)
εi+=ui=εiI(yi−xi⊤b>0),εi−=vi=εiI(yi−xi⊤b<0)
可见,回归残差的正部被赋予了
τ
\tau
τ权重,负部被赋予
(
1
−
τ
)
(1-\tau)
(1−τ)的权重,令
τ
=
0.5
\tau=0.5
τ=0.5就是等权,所以中位数回归又是分位数回归的一个特例。
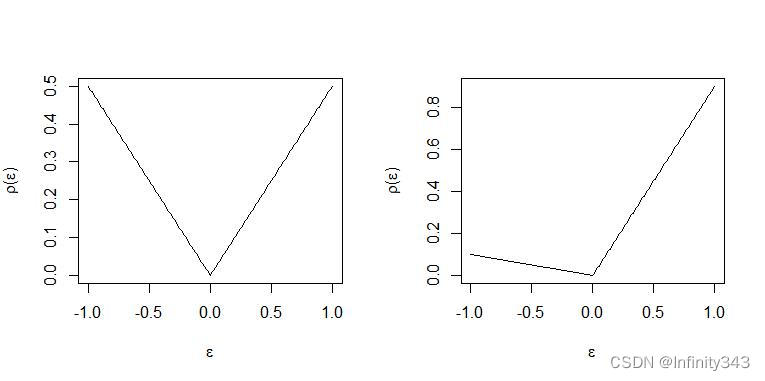
不难看出,
ℓ
1
\ell_1
ℓ1回归问题在零点处不可导,所以OLS方法不可用,但可以将其划为线性回归问题进行求解。对于一个线性规划问题其标准形式为
min
z
c
⊤
z
s
u
b
j
e
c
t
t
o
A
z
=
b
∗
,
z
≥
0
\min_{z} \,\,c^{\top}z \\ \mathrm{subject \,to} \,\,\mathbf{A}z=\mathbf{b}^*, z\ge0
zminc⊤zsubjecttoAz=b∗,z≥0
这里的
b
∗
b^*
b∗带上星号是为了区分开回归参数
b
b
b. 从定义来看,线性回归标准型要求所有决策变量大于零,显然残差是有正有负的,为满足上述条件,回忆之前对残差正负部的定义:
ε
i
=
u
i
−
v
i
\varepsilon_i=u_i-v_i
εi=ui−vi
其中正部
u
i
=
max
(
0
,
ε
i
)
u_i=\max(0,\varepsilon_i)
ui=max(0,εi)负部
v
i
=
max
(
0
,
−
ε
i
)
=
∣
ε
i
∣
I
ε
<
0
v_i=\max(0,-\varepsilon_i)=|\varepsilon_i|I_{\varepsilon<0}
vi=max(0,−εi)=∣εi∣Iε<0。
此时式(3)改写为
∑
i
=
1
n
ρ
τ
(
ε
i
)
=
∑
i
−
1
n
u
i
τ
+
v
i
(
1
−
τ
)
=
τ
1
n
⊤
u
+
(
1
−
τ
)
1
n
⊤
v
\sum_{i=1}^n\rho_{\tau}(\varepsilon_i)=\sum_{i-1}^nu_i\tau+v_i(1-\tau)=\tau\mathbf{1}_{n}^{\top}\boldsymbol{u}+(1-\tau)\mathbf{1}_{n}^{\top}\boldsymbol{v}
i=1∑nρτ(εi)=i−1∑nuiτ+vi(1−τ)=τ1n⊤u+(1−τ)1n⊤v
其中
u
=
(
u
1
,
…
,
u
n
)
⊤
,
v
=
(
v
1
,
…
,
v
n
)
⊤
\boldsymbol{u}=(u_1,\dots,u_{n})^{\top},\boldsymbol{v}=(v_1,\dots,v_n)^{\top}
u=(u1,…,un)⊤,v=(v1,…,vn)⊤,
1
n
\mathbf{1}_n
1n是
n
×
1
n\times1
n×1的全一向量。为记号方便,之后的向量或矩阵将不再加粗,而是通过取消下标来表示。若样本量为
N
N
N参数个数为
K
K
K,令
u
,
v
u,v
u,v为松弛变量,则会有
N
N
N个等式约束
y
i
−
x
i
⊤
b
=
ε
i
=
u
i
−
v
i
i
=
1
,
…
N
y_i-x_i^{\top}b=\varepsilon_i=u_i-v_i \quad i=1,\dots N
yi−xi⊤b=εi=ui−vii=1,…N
上式就可以改写为一个线性规划:
min
b
∈
R
K
,
u
∈
R
+
N
,
v
∈
R
+
N
{
τ
1
N
⊤
u
+
(
1
−
τ
)
1
N
⊤
v
∣
y
i
=
x
i
b
+
u
i
−
v
i
,
i
=
1
,
…
,
N
}
\min _{b \in \mathbb{R}^{K}, u \in \mathbb{R}_{+}^{N}, v \in \mathbb{R}_{+}^{N}}\left\{\tau \mathbf{1}_{N}^{\top} u+(1-\tau) \mathbf{1}_{N}^{\top} v \mid y_{i}=x_{i} b+u_{i}-v_{i}, i=1, \ldots, N\right\}
b∈RK,u∈R+N,v∈R+Nmin{τ1N⊤u+(1−τ)1N⊤v∣yi=xib+ui−vi,i=1,…,N}
注意到,上式中参数
b
∈
R
K
b\in\mathbb{R}^K
b∈RK不能保证非负,所以也需要将
b
b
b分解为正负部
b
=
b
+
−
b
−
b = b^+ - b^-
b=b+−b−
其中
b
+
=
max
(
0
,
b
)
,
b
−
=
max
(
0
,
−
b
)
b^+=\max(0, b), b^-=\max(0, -b)
b+=max(0,b),b−=max(0,−b), 该
N
N
N个等式约束以矩阵表达(更直观):
y
:
=
[
y
1
⋮
y
N
]
=
[
x
1
⊤
⋮
x
N
⊤
]
(
b
+
−
b
−
)
+
I
N
u
−
I
N
v
{y}:=\left[\begin{array}{c} y_{1} \\ \vdots \\ y_{N} \end{array}\right]=\left[\begin{array}{c} \mathbf{x}_{1}^{\top} \\ \vdots \\ \mathbf{x}_{N}^{\top} \end{array}\right]\left(b^{+}-b^{-}\right)+\mathbf{I}_{N} u-\mathbf{I}_{N} v
y:=⎣
⎡y1⋮yN⎦
⎤=⎣
⎡x1⊤⋮xN⊤⎦
⎤(b+−b−)+INu−INv
其中
I
N
=
d
i
a
g
(
1
N
)
\mathbf{I}_{N}=diag(\mathbf{1}_N)
IN=diag(1N).将
x
\mathbf{x}
x写为矩阵继续简化表达
X
(
b
+
−
b
−
)
+
I
N
u
−
I
N
v
=
[
X
,
−
X
,
I
N
,
−
I
N
]
[
b
+
b
−
u
v
]
\mathbf{X}\left(b^{+}-b^{-}\right)+\mathbf{I}_{N} u-\mathbf{I}_{N} v=\left[\mathbf{X},-\mathbf{X}, \mathbf{I}_{N},-\mathbf{I}_{N}\right]\left[\begin{array}{c} b^{+} \\ b^{-} \\ u \\ v \end{array}\right]
X(b+−b−)+INu−INv=[X,−X,IN,−IN]⎣
⎡b+b−uv⎦
⎤
可以看到现在我们有
N
N
N个等式约束,
2
K
2K
2K个参数(因为参数被分为了正负部,所以乘2),另外还有
2
N
2N
2N个松弛变量:
A
:
=
[
X
−
X
I
N
−
I
N
]
A:=[\mathbf{X}\, -\mathbf{X}\quad \mathbf{I}_N \,\, -\mathbf{I}_N]
A:=[X−XIN−IN]
符合标准型的约束条件为:
b
∗
=
A
[
b
+
b
−
u
v
]
=
A
z
b^*=A \begin{bmatrix} b^+ \\ b^- \\ u \\ v \\ \end{bmatrix}=Az
b∗=A⎣
⎡b+b−uv⎦
⎤=Az
因为
b
+
b^+
b+和
b
−
b^-
b−仅通过约束影响最小化问题(优化目标中并不存在
b
b
b),所以必须引入维度为
2
K
×
1
2K \times 1
2K×1的
0
0
0 作为系数向量
c
c
c 的一部分,可以适当地定义为
c
=
[
0
τ
1
N
(
1
−
τ
)
1
N
]
c=\left[\begin{array}{c} \mathbf{0} \\ \tau \mathbf{1}_{N} \\ (1-\tau) \mathbf{1}_{N} \end{array}\right]
c=⎣
⎡0τ1N(1−τ)1N⎦
⎤
这样目标函数就是
c
⊤
z
=
0
⊤
(
b
+
−
b
−
)
⏟
=
0
+
τ
1
N
⊤
u
+
(
1
−
τ
)
1
N
⊤
v
=
∑
i
=
1
N
ρ
τ
(
ε
i
)
.
c^{\top} z=\underbrace{\mathbf{0}^{\top}\left(b^{+}-b^{-}\right)}_{=0}+\tau \mathbf{1}_{N}^{\top} u+(1-\tau) \mathbf{1}_{N}^{\top} v=\sum_{i=1}^{N} \rho_{\tau}\left(\varepsilon_{i}\right) .
c⊤z==0
0⊤(b+−b−)+τ1N⊤u+(1−τ)1N⊤v=i=1∑Nρτ(εi).
显然此时已经识别出了线性规划标准型的所有因素,利用R或python就可以实现求解
getwd()
setwd('C:/Users/beida/Desktop')
base=read.table("rent98_00.txt",header=TRUE)
attach(base)
library(quantreg)
library(lpSolve)
tau <- 0.5
# only one covariate
X <- cbind(1, base$area) #设计阵X
K <- ncol(X) #列数量,即参数个数
N <- nrow(X) #行数量,即样本量(等式约束量)
A <- cbind(X, -X, diag(N), -diag(N)) #优化系数
c <- c(rep(0, 2*ncol(X)), tau*rep(1, N), (1-tau)*rep(1, N)) #目标函数系数
b <- base$rent_euro #响应变量Y
const_type <- rep("=", N) #N个等式约束
linprog <- lp("min", c, A, const_type, b)
beta <- linprog$sol[1:K] - linprog$sol[(1:K+K)] #
beta
rq(rent_euro ~ area, tau=tau, data=base)
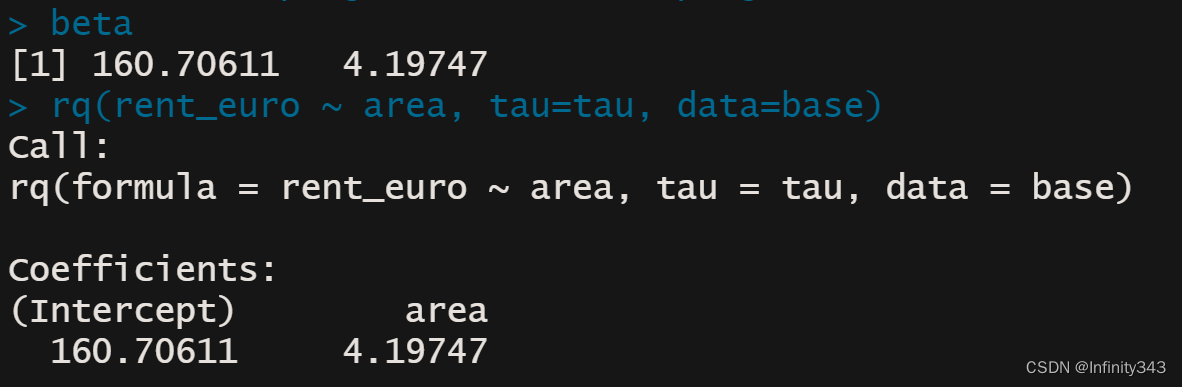
可以看到线性规划求解的结果与quantreg包的rq函数得到了相同的解。
python同理
import io
import numpy as np
import pandas as pd
import requests
np.
url = "http://freakonometrics.free.fr/rent98_00.txt"
s = requests.get(url).content
base = pd.read_csv(io.StringIO(s.decode('utf-8')), sep='\t')
tau = 0.5
from cvxopt import matrix, solvers
X = pd.DataFrame(columns=[0, 1])
X[1] = base["area"] # data points for independent variable area
#X[2] = base["year"] # data points for independent variable year
X[0] = 1 # intercept
K = X.shape[1]
N = X.shape[0]
# equality constraints - left hand side
A1 = X.to_numpy() # intercepts & data points - positive weights
A2 = X.to_numpy() * -1 # intercept & data points - negative weights
A3 = np.identity(N) # error - positive
A4 = np.identity(N) * -1 # error - negative
A = np.concatenate((A1, A2, A3, A4), axis=1) # all the equality constraints
# equality constraints - right hand side
b = base["rent_euro"].to_numpy()
# goal function - intercept & data points have 0 weights
# positive error has tau weight, negative error has 1-tau weight
c = np.concatenate((np.repeat(0, 2 * K), tau * np.repeat(1, N), (1 - tau) * np.repeat(1, N)))
# converting from numpy types to cvxopt matrix
Am = matrix(A)
bm = matrix(b)
cm = matrix(c)
# all variables must be greater than zero
# adding inequality constraints - left hand side
n = Am.size[1]
G = matrix(0.0, (n, n))
G[:: n + 1] = -1.0
# adding inequality constraints - right hand side (all zeros)
h = matrix(0.0, (n, 1))
# solving the model
sol = solvers.lp(cm, G, h, Am, bm, solver='glpk')
x = sol['x']
# both negative and positive components get values above zero, this gets fixed here
beta = x[0:K] - x[K : 2 * K]
print(beta)
- 思考
从R的运行情况来看,线性规划的求解速度显著慢于rq函数,这与求解方法有关。rq提供了以下方法来求解分位数回归:
the algorithmic method used to compute the fit. There are several options:
-
“br” The default method is the modified version of the Barrodale and Roberts algorithm for
l 1 l_1 l1-regression, used by l1fit in S, and is described in detail in Koenker and d’Orey(1987, 1994), default = “br”. This is quite efficient for problems up to several thousand observations, and may be used to compute the full quantile regression process. It also implements a scheme for computing confidence intervals for the estimated parameters, based on inversion of a rank test described in Koenker(1994). -
“fn” For larger problems it is advantageous to use the Frisch–Newton interior point method “fn”. This is described in detail in Portnoy and Koenker(1997).
-
“pfn” For even larger problems one can use the Frisch–Newton approach after preprocessing “pfn”. Also described in detail in Portnoy and Koenker(1997), this method is primarily well-suited for large n, small p problems, that is when the parametric dimension of the model is modest.
-
“sfn” For large problems with large parametric dimension it is often advantageous to use method “sfn” which also uses the Frisch-Newton algorithm, but exploits sparse algebra to compute iterates. This is especially helpful when the model includes factor variables that, when expanded, generate design matrices that are very sparse. At present options for inference, i.e. summary methods are somewhat limited when using the “sfn” method. Only the option se = “nid” is currently available, but I hope to implement some bootstrap options in the near future.
-
“fnc” Another option enables the user to specify linear inequality constraints on the fitted coefficients; in this case one needs to specify the matrix R and the vector r representing the constraints in the form Rb \geq rRb≥r. See the examples below.
-
“conquer” For very large problems especially those with large parametric dimension, this option provides a link to the conquer of He, Pan, Tan, and Zhou (2020). Calls to summary when the fitted object is computed with this option invoke the multiplier bootstrap percentile method of the conquer package and can be considerably quicker than other options when the problem size is large. Further options for this fitting method are described in the conquer package. Note that this option employs a smoothing form of the usual QR objective function so solutions may be expected to differ somewhat from those produced with the other options.
-
“pfnb” This option is intended for applications with large sample sizes and/or moderately fine tau grids. It uses a form of preprocessing to accelerate the solution process. The loop over taus occurs inside the Fortran call and there should be more efficient than other methods in large problems.
-
“qfnb” This option is like the preceeding one except that it doesn’t use the preprocessing option.
-
“ppro” This option is an R prototype of the pfnb and is offered for historical/interpretative purposes, but probably should be considered deprecated.
-
“lasso” There are two penalized methods: “lasso” and “scad” that implement the lasso penalty and Fan and Li smoothly clipped absolute deviation penalty, respectively. These methods should probably be regarded as experimental. Note: weights are ignored when the method is penalized.
可见求解方法之多,运行速度也不尽相同。但需要注意的是对于当前问题,单纯形法是很难甚至是无法求解的
simplex(c, A3 = A, b3 = b, maxi = TRUE, n.iter =200, eps = 1e-4)
> No feasible solution could be found
我们只选取了两个回归系数,样本量为4571,单纯形法的计算时间就超过了5分钟,且没有得到可行解(尽管降低了解的精度要求)。
后续将继续更新别的求解算法。