Graph Representation Learning Chapter[2]
序言
我们将介绍一些传统的方法( basic graph statistics, kernel methods,
and their use for node and graph classification tasks),为后续学习做铺垫
2.1Graph Statistics and Kernel Methods
传统方法是启发式的。通常提取数据、特征将其作为ML的输入。后面会介绍几种传统的启发式学习。
2.1.1 Node-level statistics and features
我们的目的是搞清楚哪些特征和统计数据有价值,哪些可以用来区分一个节点与其他节点。这些东西在后面的分类任务中很有用。
Node degree
节点的度,就是一个点旁边直接连的线有几根。
du = X v∈V A[u, v].
Node centrality
度不能衡量节点的重要性。(度多不一定是最重要的)
所以提出节点中心性。
特征向量中心性与该节点的邻居节点重要性相关。
λe = Ae.
A:邻接矩阵
λ:最大特征值
中心性这块儿,需要了解一下:度中心性、特征向量中心性、中介中心性、连接中心性
总而言之,中心值是 最大特征值对应的特征向量。
特征向量中心性可以理解为,在无限长的随机游走中,某节点被访问的可能性大小。
特征向量中心性与该节点的邻居节点重要性相关。(你的邻居越牛,你就越牛)
书上有个幂迭代求特征值的:e(t+1) = Ae(t),(不管什么方法,都是为了求特征值)。
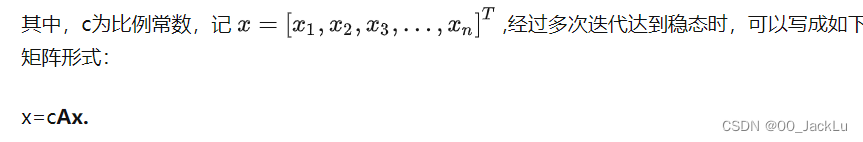
知乎解释:
其实很好理解迭代的含义。一个节点的度可以衡量节点在网络中的重要程度(实际上就是点度中心性),但是一个节点的重要程度除了和自己有关还和邻居的重要程度(邻居的度)有关,换句话说,如果你的邻居越重要你就越重要,同时你相邻的“重要的”邻居越多你就越重要。那么一个邻接矩阵A乘节点度向量x(即Ax=y,其中x=[x1,x2,x3,…,xn],xi表示节点i的度,A为nn,x为n1),相当于将节点i的邻居的度分配/添加到节点i上了,也就是将i的邻居的重要程度加到的i自己的重要程度上了,这相当于一次对点度中心性的扩散,也就是一次迭代。然后我们将y作为每一个节点新的重要程度再与A相乘得到Ay=y’作为一轮新的迭代(新的重要程度扩散),一直迭代下去直到达到一个平衡,此时每一个节点在整个网络中的重要性比例会保持稳定,此时的向量也就是特征向量。
大概明白何为中心性。。。
The clustering coefficient
中心性不能区分除了中心节点之外的点(非中心那一群),所以有了这个“集聚系数”。
这么算:
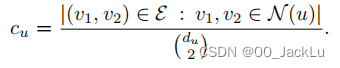
分子:计算节点u的邻居节点间存在的边的数量。(大概就是闭合三角形)
分母:计算邻居节点可以组成多少队。
系数越高越重要
Closed triangles, ego graphs, and motifs
承上文,另一种方法是计算每个邻域中闭三角数量。more precise,在ego-graph中,集聚系数与 实际三角形数和总可能三角形的数量比有关。(so 为什么?)
ego-graph(指距离中心节点小于特定距离的所有点构成的图)
然后说,这样能应用到更复杂的结构,比如说圈
2.1.2 Graph-level features and graph kernel
以上说的都是基于节点的,图级的任务,我们引入新的方法:图核方法(graph kernel),侧重点在于提取显示的特征表示。
Bag of nodes
最简单的方法是,直接聚合节点级的信息,聚合后作为图级显示。缺点是丢失了全局属性。
The Weisfeiler-Lehman kernel
为提升bag of nodes方法,提出了Weisfeiler-Lehman算法(威斯费勒-莱曼算法)。
1.定义 label l(0)(v)为节点的度
2.通过邻居节点,迭代的给每一个节点分配新的label
3.重复2进行k次
具体的可以看链接。
Graphlets and path-based methods
在图上提取特征,有效简单的是计算不同的小子图。但很难,所以提出了一些近似的方法。
一种是 基于路径(path-based methods):检查图中出现的不同类型的路径。
例如,Kashima等人提出的随机游走核–在图上运行随机游走,然后计算不同度序列的出现。很强大的思想,后面会说。
2.2 Neighborhood Overlap Detection
2.1的方法在节点和图中都很有用,但是不能量化节点间的关系,so不能通过节点相似度来进行关系预测(边预测)
后面介绍的邻域重叠检测方法,能够解决这个。
先定义节点相似度矩阵,度量两节点间的关联度。最简单的邻域重叠度量是计算两个节点共享的邻居的数量
S
[
u
,
v
]
=
∣
N
(
u
)
∩
N
(
v
)
∣
,
S
∈
R
∣
V
∣
×
∣
V
∣
S[u, v] = |N (u) ∩ N (v)|,S ∈ R |V|×|V|
S[u,v]=∣N(u)∩N(v)∣,S∈R∣V∣×∣V∣
S[u,v]表示量化节点u和v之间关系的量化值
S∈R|v|×|v|表示汇总所有成对节点统计量的相似度矩阵。
坦白讲,俩人邻居都一样,那可不就贼相似,关联度贼高,就是这个意思。
2.2.1 Local overlap measures
局部重合度的简单的思想就是上文提及的用共同邻居的比例来描述节点间两两的relationship,当然,单纯计数是缺少一致性,因而需要进行标准化处理。
其中比较著名的有Sorensen提出的:

其中du便是节点u的度:
类似Salton: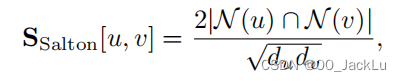
Jaccard overlap:
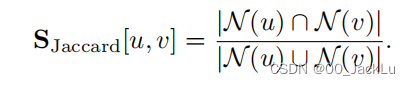
这些措施试图量化节点邻域之间的重叠,同时最小化由于节点度引起的任何偏差。
当然,也有的指标并不局限于描述有多少重合的邻居节点,而是反过来描述重合节点的重要程度又如何。譬如经典的Resource Allocation (RA) index:
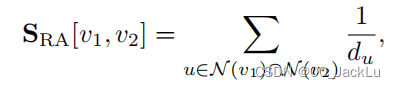
还有在RA基础上加上了对数函数的Adamic-Adar(AA) index:
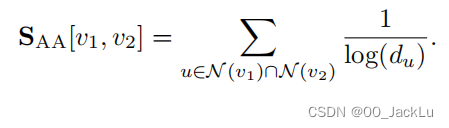
RA和AA index都给了低度(low degree)的邻接点更高的权重,因为这些low-degree的节点能够比high-degree的节点提供更多信息,这点在文本分类中思想也有体现,譬如经典的TF-IDF,给予频率较少的词更大权重以区分不同词的重要性。
2.2.2 Global overlap measures
上节提到的局部重叠检测(local overlap measures)能够提供重要度以及节点间相似度信息以完成link prediction一类的任务,即使这种方法十分简单高效,还是能匹配DL,but 譬如在社区发现算法中,分到同一个社区的两个节点很可能没有重合的邻居,如何描述他们之间的关系?要借助global overlap的一些统计量描述在全图视角下节点间关系。
Katz index
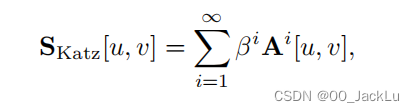
统计两点间所有的任意长度的path
β是定义 短路权重/长路权重,β < 1表示长路权重低一点。
邻接矩阵A 的i次方用来表两点间长度为i的路的条数
证明:略
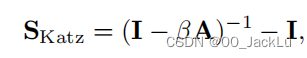
Leicht, Holme, and Newman (LHN) similarity
Katz指数的一个问题是它受节点度的强烈偏差。Katz指通常会给度高的节点更高的总体相似性得分,因为度高节点通常会涉及更多的路径。因此,我们需要标准化路的数量,所以用了这个:
number of expected paths between two nodes
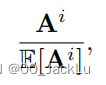
E[Ai]的计算是下式:推导过程
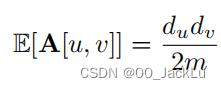
m为总节点数,说明在random configuration model假设下节点间边的似然是和两节点的degree乘积成比例。
如果节点u有du条边离开u,那么这些边有dv/2m的概率流入v点。
基于此提出(蛮复杂,以后用到再细看):
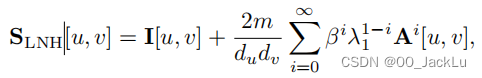
Random walk methods
从全局角度衡量节点关系的方法则是大名鼎鼎的随机游走法,这种节点关系表征法直接催生出了如Deepwalk这样经典的工作。
在无向图中,易知P为对称矩阵,所以第u行/列就是从节点u出发随机游走无数次后到达其他节点的概率。
2.3 Graph Laplacians and Spectral Methods
这节学习图中节点聚类的问题,介绍谱图理论
2.3.1 Graph Laplacians
拉普拉斯矩阵,在GCN也有用到,类似卷积核这样的东西,挺重要的。
细看
Unnormalized Laplacian
由邻接矩阵变化而来,很有用
非标准化的也是最基础的:L = D − A
L是拉普拉斯,D是节点度的对角矩阵,A是邻接矩阵
L重要性质:
- 对称并且半正定的
- 有恒等式(总变差公式)
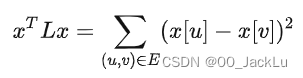
- 特征值非负
yinyong引用
Normalized Laplacians
标准化的拉普拉斯矩阵有几种形式:
对称标准化 (symmetric normalized Laplacian)
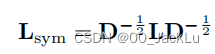
随机游走标准化 (random walk Laplacian)
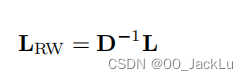
以上也有拉普拉斯的3个性质,但此前关于特征值为0的节点连接结论则要随着特征值的标准化的改变而改变。
2.3.2 Graph Cuts and Clustering
L的0特征值对应的特征向量,可以用来将连通分量中的节点分配给簇。但如果整张图都是连通的呢? 在这一节中,我们会介绍使用拉普拉斯矩阵,在完全连通图中给出节点的最优聚类(optimal cluster)。
Graph cuts
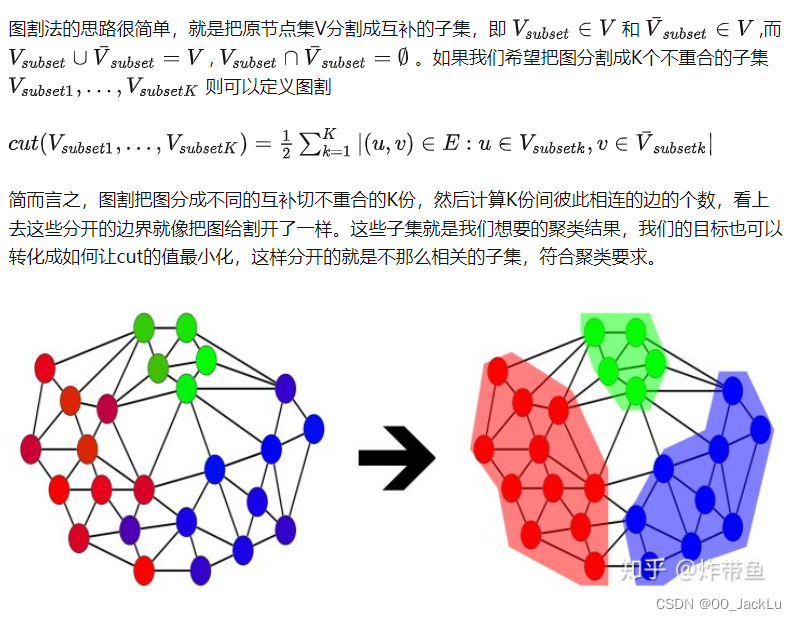
除了直接最优化最小的cut,还有的思路在于描述cut的不同的表达方式

Approximating the RatioCut with the Laplacian spectrum

2.3.3 Generalized spectral clustering
上一节,我们找到了一个将图分成两个簇的最优划分。那么,我们也可以将这种方法推广到K个簇的最优划分问题上。
1、找到L的K个最小的特征值对应的特征向量,除去最小的那个,还剩下K-1个特征向量
2、使用第一步找到的K-1个特征向量组成矩阵 U,每一列对应一个特征向量,矩阵U就是原图在谱空间上的表征
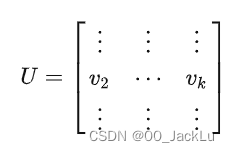
3、一行代表一个对应节点的表示向量
4、使用K均值聚类方法来聚合,将图划分为K簇